This article is the second in a three-part series to help you use Snowflake’s Information Schema to better understand and effectively utilize Snowflake.
As a Customer Success Engineer, my daily job entails helping our customers get the most value from our service. And I’m now passing along some of what I’ve learned to help you become more self-sufficient. In my first post, I discussed getting a handle on your utilization of compute resources by using various Information Schema views and functions to profile your virtual warehouse usage.
In this post, I provide a deep-dive into understanding how you are utilizing data storage in Snowflake at the database, stage, and table level. To do this, I will show you examples of two functions and a view provided in the Information Schema for monitoring storage usage. I will also show you a handy page in the UI that provides an account-level view of your storage. Keep in mind that you need ACCOUNTADMIN access to perform any of the tasks described in this post.
Let’s get started.
Summary Storage Profiling in the UI
Before diving into our detailed analysis of data storage, let’s take a quick look at the summary, account-level storage view provided by Snowflake. As a user with the ACCOUNTADMIN role, you can navigate to the Account page in the Snowflake UI to get a visual overview of the data storage for your account.
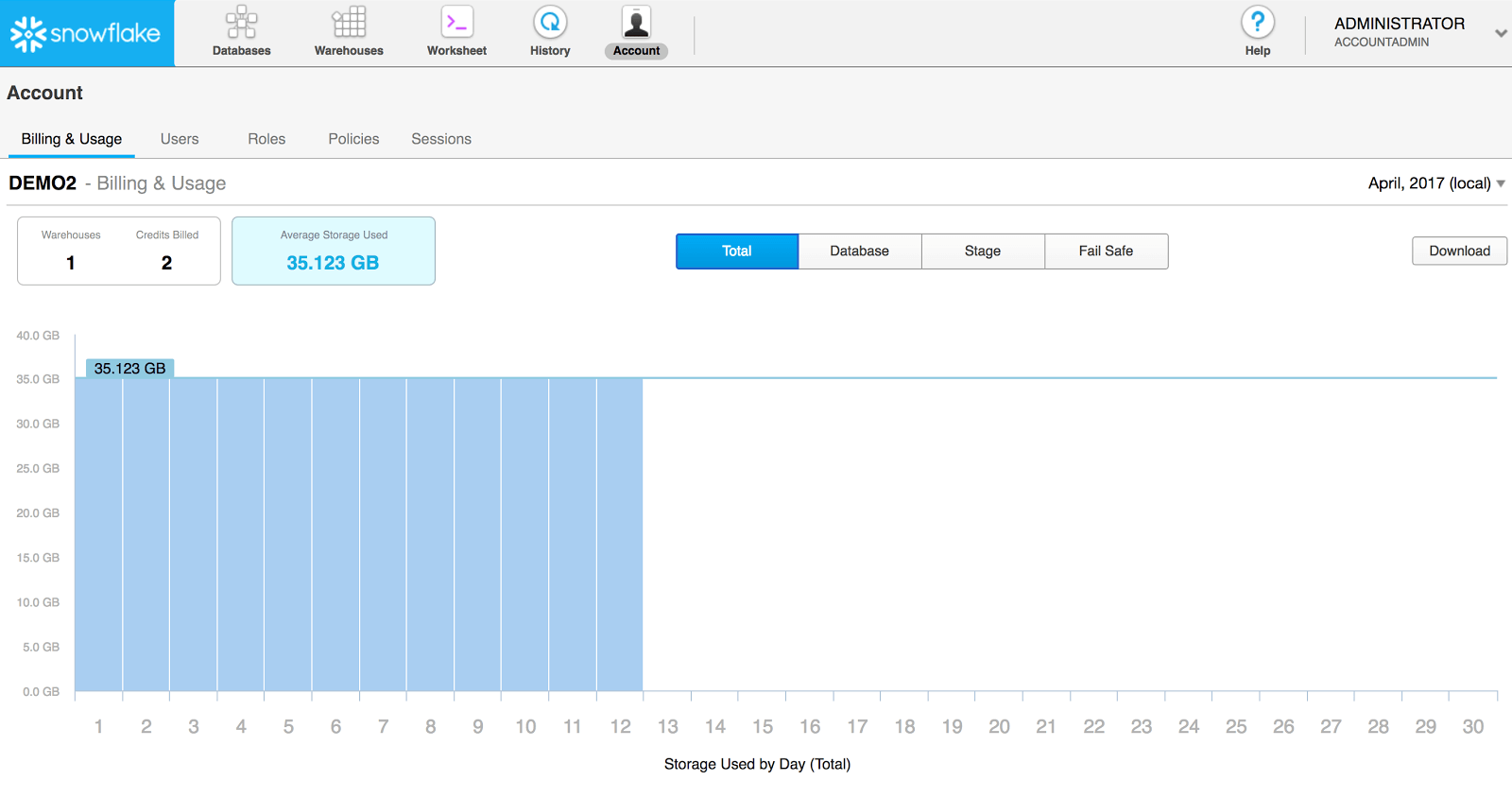
This page provides a view, by month, of the average and daily storage usage across your entire account. You can use the filters on the page to filter by database, Snowflake stage, and data maintained in Fail-safe (for disaster recovery).
Detailed Storage Profiling Using the Information Schema
The Snowflake Information Schema provides two functions and one view for monitoring detailed data storage at the database, stage, and table level:
- DATABASE_STORAGE_USAGE_HISTORY (function)
- STAGE_STORAGE_USAGE_HISTORY (function)
- TABLE_STORAGE_METRICS (view)
The DATABASE_STORAGE_USAGE_HISTORY table function shows your database status and usage for all databases in your account or a specified database. Here’s an example of the usage over the last 10 days for a database named sales:
use warehouse mywarehouse;
select * from
table(sales.information_schema.database_storage_usage_history(dateadd('days',-10,current_date()),current_date(), ‘SALES’));
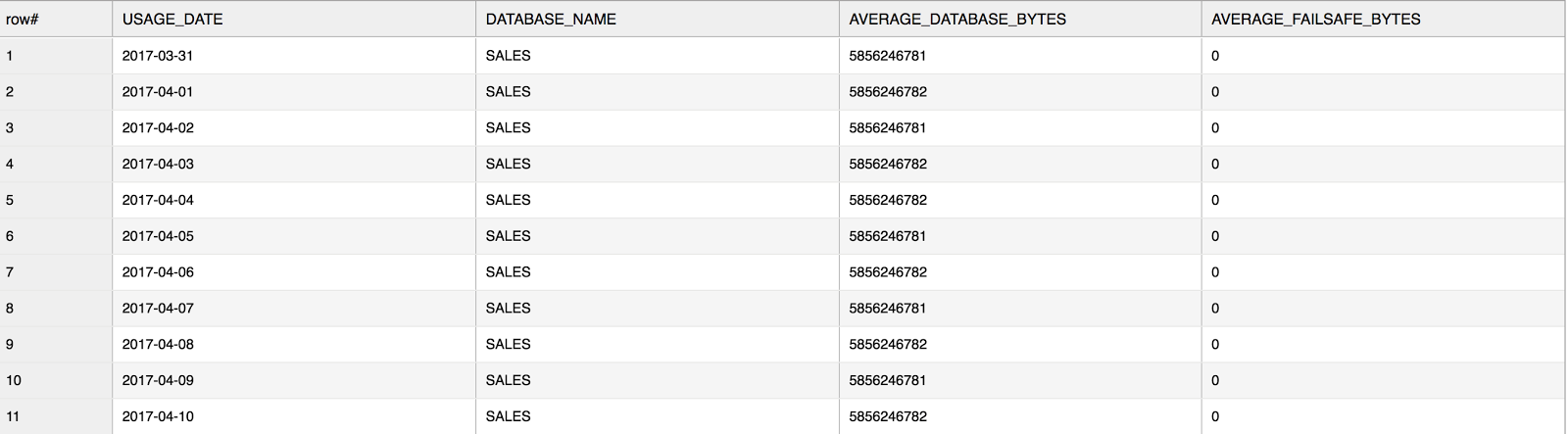
Note that the above screenshot only displays some of the output columns. For full details about the output, see the online documentation. Also, per the Snowflake documentation:
If a database has been dropped and its data retention period has passed (i.e. database cannot be recovered using Time Travel), then the database name is reported as DROPPED_id.
At its core, the most useful insight from this function is the average growth in your database. Keep in mind, the output includes both AVERAGE_DATABASE_BYTES and AVERAGE_FAILSAFE_BYTES. Leveraging these data points to derive a percentage of Fail-safe over actual database size should give you an idea of how much you should be investing towards your Fail-safe storage. If certain data is not mission critical and doesn’t require Fail-safe, try setting these tables to transient. More granular information about Fail-safe data is provided in TABLE_STORAGE_METRICS, which we will look at more closely later in this post.
Next, let’s look at STAGE_STORAGE_USAGE_HSTORY. This function shows you how much storage is being used for staged files across all your Snowflake staging locations, including named, internal stages. Note that this function does not allow querying storage on individual stages.
Here’s an example of staged file usage for the last 10 days (using the same database, sales, from the previous example):
select * from
table(sales.information_schema.stage_storage_usage_history(dateadd('days',-10,current_date()),current_date()));
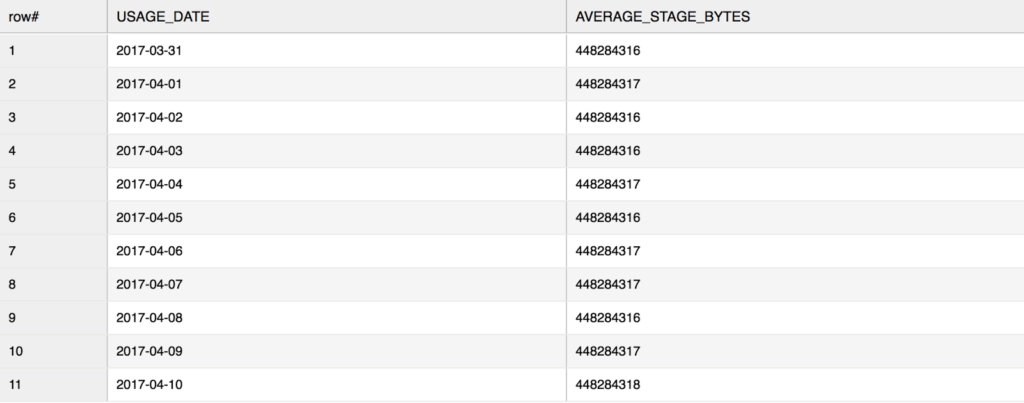
Note that the above screenshot only displays some of the output columns. For full details about the output, see the online documentation.
Also note that you can only query up to 6 months worth of data using this function. Some of our users like to use Snowflake stages to store their raw data. For example, one user leverages table staging locations for their raw data storage just in case they need to access the data in the future. There’s nothing wrong with this approach, and since Snowflake compresses your staged data files, it certainly makes sense; however, only the last 6 months of staged data storage is available.
Finally, the TABLE_STORAGE_METRICS view shows your table-level storage at runtime. This is a snapshot of your table storage which includes your active and Fail-safe storage. Additionally, you can derive cloned storage as well utilizing the CLONE_GROUP_ID column. As of today, this is the most granular level of storage detail available to users.
Here’s a general use example (using the sales database):
select * from sales.information_schema.table_storage_metrics where table_catalog = 'SALES';
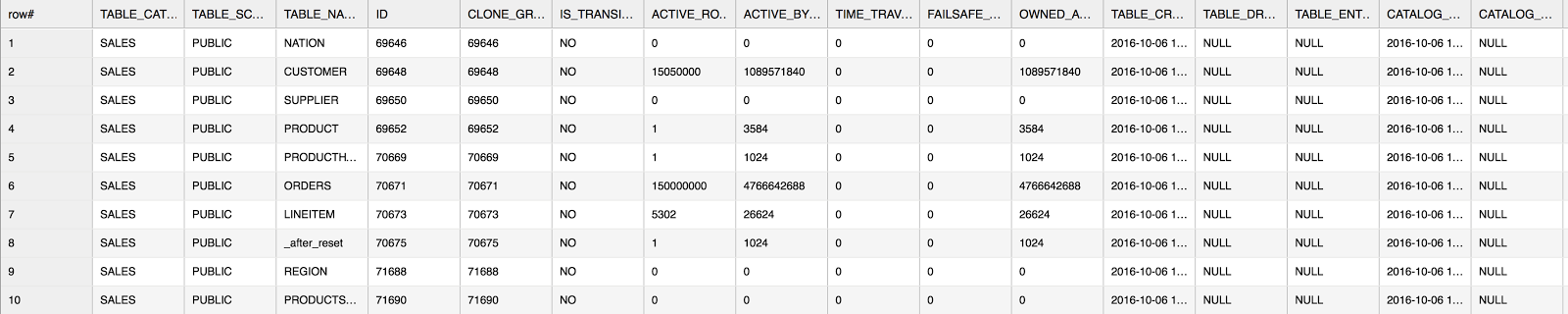
Note that the above screenshot only shows a portion of the output columns. For full details about the output, see the online documentation.
One interesting analysis I’ve been helping our customers with is deriving how much of their table storage is based on cloned data. In Snowflake, cloning data has no additional costs (until the data is modified or deleted) and it’s done very quickly. All users benefit from “zero-copy cloning”, but some are curious to know exactly what percentage of their table storage actually came from cloned data. To determine this, we’ll leverage the CLONE_GROUP_ID column in TABLE_STORAGE_METRICS.
For example (using a database named concurrency_wh):
with storage_sum as (
select clone_group_id,
sum(owned_active_and_time_travel_bytes) as owned_bytes,
sum(active_bytes) + sum(time_travel_bytes) as referred_bytes
from concurrency_wh.information_schema.table_storage_metrics
where active_bytes > 0
group by 1)
select * , referred_bytes / owned_bytes as ratio
from storage_sum
where referred_bytes > 0 and ratio > 1
order by owned_bytes desc;
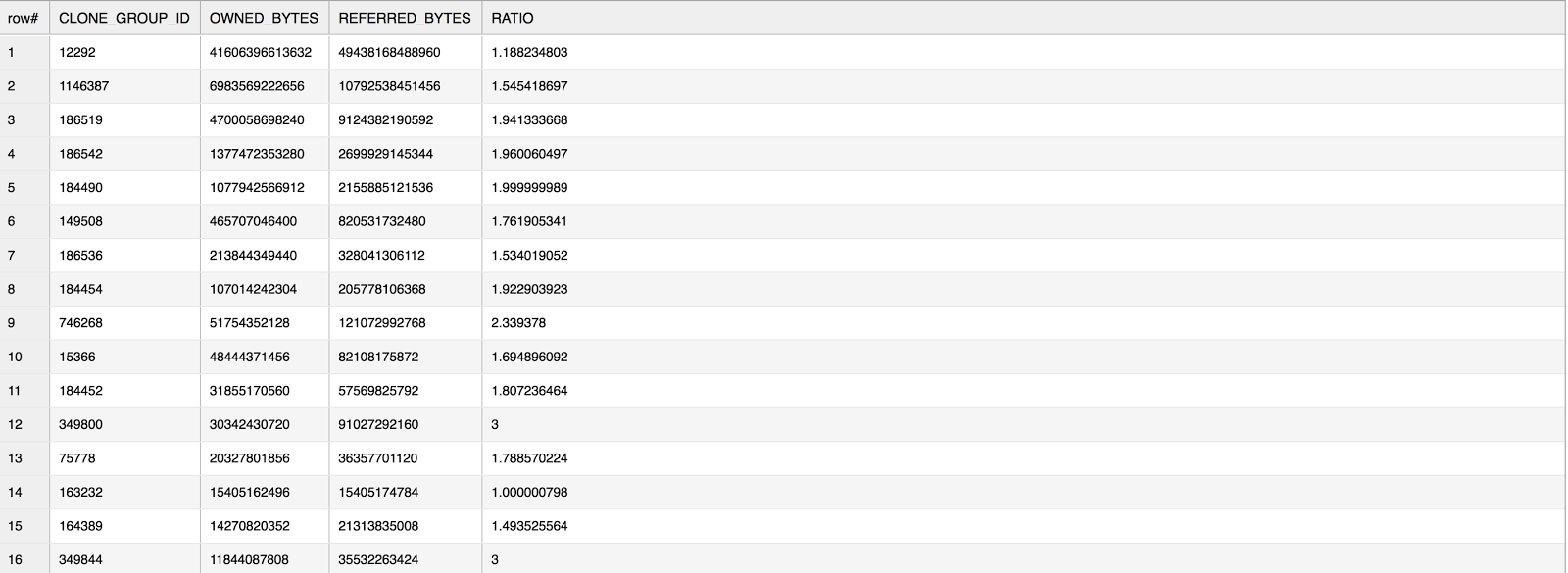
The ratio in the above query gives you an idea of how much of the original data is being “referred to” by the clone. In general, when you make a clone of a table, the CLONE_GROUP_ID for the original table is assigned to the new, cloned table. As you perform DML on the new table, your REFERRED_BYTES value gets updated. If you join the CLONE_GROUP_ID back into the original view, you get the output of the original table along with the cloned table. A ratio of 1 in the above example means the table data is not cloned.
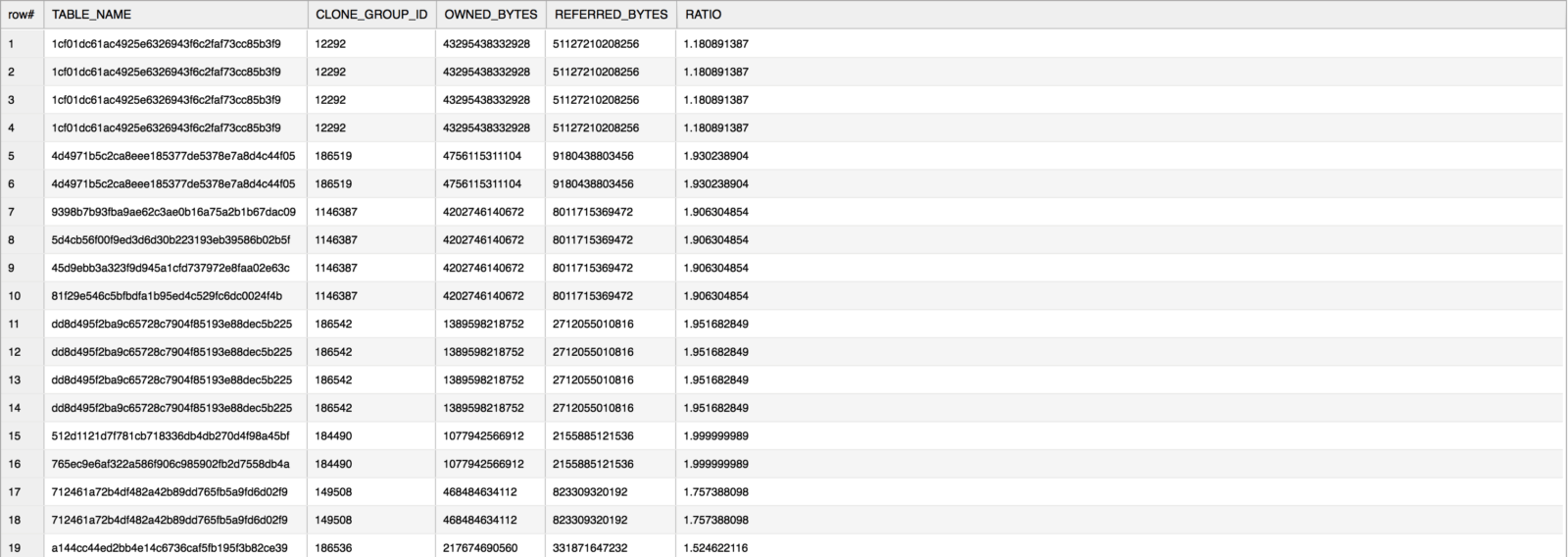
If you need to find out the exact table name from the above query, then simply join the CTE back to the TABLE_STORAGE_METRICS view and ask for the TABLE_NAME column.
For example (using the same database, concurrency_wh, from the previous example):
with storage_sum as (
select clone_group_id,
sum(owned_active_and_time_travel_bytes) as owned_bytes,
sum(active_bytes) + sum(time_travel_bytes) as referred_bytes
from concurrency_wh.information_schema.table_storage_metrics
where active_bytes > 0
group by 1)
select b.table_name, a.* , referred_bytes / owned_bytes as ratio
from storage_sum a
join concurrency_wh.information_schema.table_storage_metrics b
on a.clone_group_id = b.clone_group_id
where referred_bytes > 0 and ratio > 1
order by owned_bytes desc;
Conclusion
By utilizing the UI and the Information Schema functions and views described in this post, you can profile your data storage to help you keep your storage costs under control and understand how your business is growing over time. It’s a good idea to take regular snapshots of your storage so that you can analyze your growth month-over-month. This will help you both formulate usage insight and take actions.
To dig in some more on this subject, check out our online documentation:
- DATABASE_STORAGE_USAGE_HISTORY function
- STAGE_STORAGE_USAGE_HSTORY function
- TABLE_STORAGE_METRICS view
- Understanding Fail-safe
- Data Storage Considerations
I hope this article has given you some good ideas for how to manage your Snowflake instance. Look for Part 3 of this series in coming weeks where I will show you how to analyze your query performance. As already shown in Parts 1 and 2, there are a lot of options to play with in Snowflake and they’re all intended to give you the flexibility and control you need to best use Snowflake. Please share your thoughts with us!
Also, for more information, please feel free to reach out to us at [email protected]. We would love to help you on your journey to the cloud. And keep an eye on this blog or follow us on Twitter (@snowflakedb) to keep up with all the news and happenings here at Snowflake Computing.



