
Data Vault is an architectural approach that includes a specific data model design pattern and methodology developed specifically to support a modern, agile approach to building an enterprise data warehouse and analytics repository. If you are not familiar with Data Vault (DV) and want to learn a bit more, check out this introductory post first.
Snowflake Cloud Data Platform was built to be design pattern agnostic. That means you can use it with equal efficiency 3NF models, dimensional (star) schemas, DV, or any hybrid you might have.
Snowflake supports DV designs and handles several DV design variations very well with excellent performance. This series of blog posts will present some tips and recommendations that have evolved over the last few years for implementing a DV-style warehouse in Snowflake.
Modeling Considerations
The world of DV has evolved in the last decade. Some folks, who started years ago may be doing what we refer to now as DV 1.0, while others will be using the more current DV 2.0 patterns. Both of these work well in Snowflake and, in fact, we have customers doing both of these today.
So let’s take a quick look at what these types of models look like.
Sequential keys (DV 1.0 style)
Using sequence generated, integer values for primary keys (PKs) is a characteristic of the modeling style when DV was first released in the early 2000s (since superseded by DV 2.0). For customers who have current DVs built this way, these will easily port to Snowflake and, in fact, will usually provide the fastest query join performance because the joins are on integer columns (which are generally the fastest in all RDBMSs).
This style of DV works best for customers who give more priority to querying directly against the DV and have more tolerance for data loading performance. Using this style of DV means you will have dependencies between Hubs and Satellites (Sats) and then Hubs and Links during load operations, but join performance, to extract the data, will be optimal because all the join keys are integers.
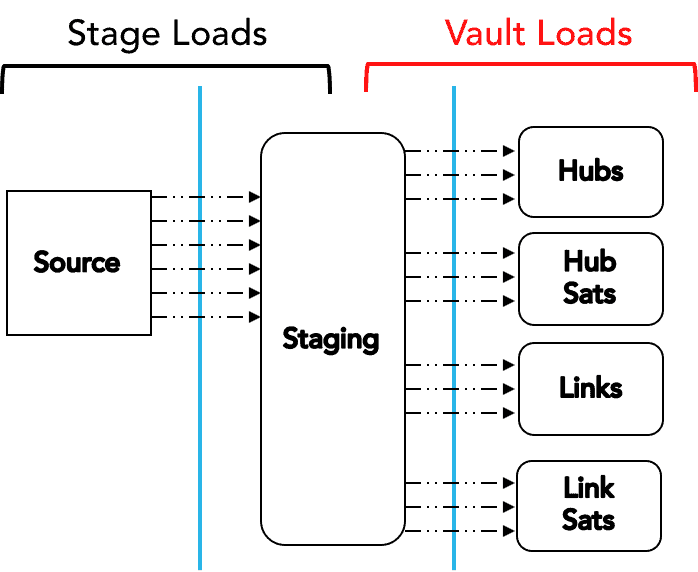
The figure below depicts a typical DV 1.0 model.

Here is a depiction of the typical load pattern for a DV 1.0 model (more discussion on this later):

Natural (business) keys (logical DV style):
Using natural or “business” keys (BKs) for the PKs was the design approach Dan Linstedt originally taught for building a logical DV model. Unfortunately most legacy databases could not adequately support joins using this approach, so surrogate keys were introduced to the physical model to improve query performance. With Snowflake, this is no longer a concern.
This approach works best for customers who place a higher priority on being able to load their DV objects in parallel. Query performance for this approach is still excellent on Snowflake, but it may be slightly slower than joins using integers (depending on how many attributes make up the BK). With Snowflake’s advanced metadata-driven optimization engine, you can still achieve excellent query performance using BKs because Snowflake prunes on character-based column values as well. Based on some internal testing, if the BK is made of only one or two attributes, the join performance may be equivalent to that of joining on integers.
The diagram below is a model using multicolumn BKs:

The advantage of this style of DV is that all the objects can be loaded in parallel because the primary keys for the Hubs do not have to be calculated during the load (as they do with the DV 1.0 style) but are simply mapped from the stage tables. This eliminates the dependencies in the load process, so everything can be loaded in parallel. The next diagram depicts a typical load pattern for this approach:
Hashed primary keys (DV 2.0 style)
Hashed PKs were introduced as part of DV 2.0. The goal was to be able to load all objects in parallel by eliminating the bottleneck encountered by most database sequence generators. At scale, this, combined with the load dependencies, turned out to be a limiting factor for many who were trying to implement a DV-style warehouse on legacy platforms. This DV pattern works well for customers who place more priority on data loading performance and who may want to use data warehouse automation tools that have built-in templates for generating hashed PKs (for example, using MD5) based on BKs.
Because of the power of the Snowflake optimizer, queries against a DV that uses this approach are still very fast (compared to legacy platforms) but will be slower than queries using BKs (character-based, multicolumn) or integer surrogate keys. This is the nature of all RDBMSs: integer joins are the fastest, followed by character string joins, followed by dense character string joins (such as UUIDs and hashed key values). The advantage Snowflake provides over other data warehouse systems is that its unique elastic compute architecture achieves high performance on these types of joins, but it may require more compute power (which means a larger size virtual warehouse).
The diagram below includes MD5 hash-based PKs:
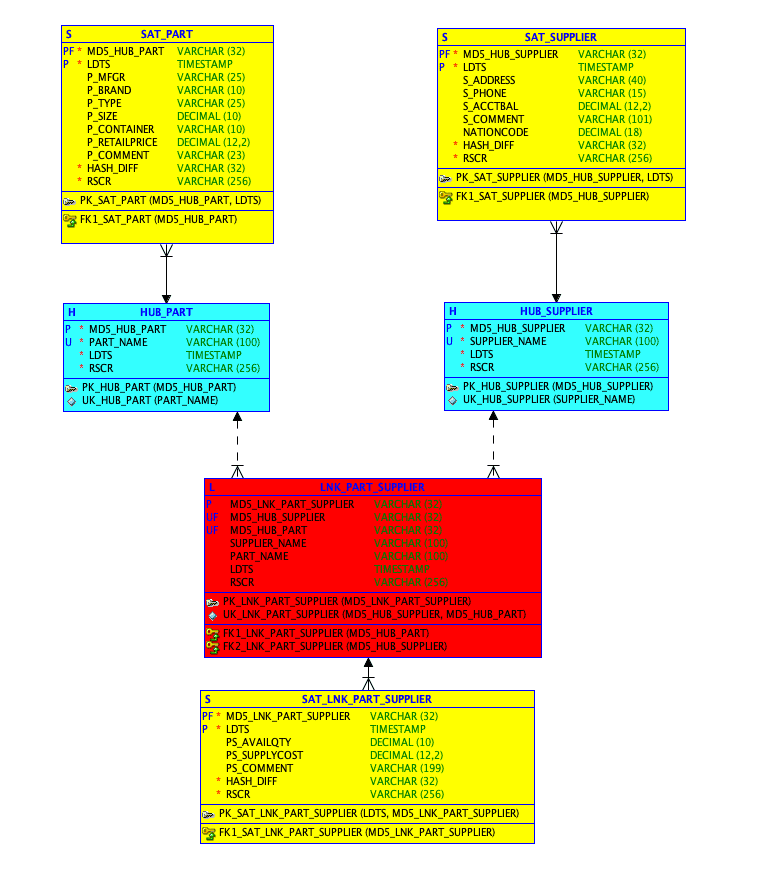
Today, there are Snowflake customers using MD5 hashes as well as SHA-256 hashes for PKs. So if you are using this approach today with your current DV on a legacy platform, there is no need to change the approach in order to migrate over to Snowflake.
A word of caution: Although hash-based joins may be slightly slower than other joins, it is possible to have a highly complex (multipart) BK with so many attributes that using a hash-based join may actually still be faster. In particular, this may occur with a central Link table that has many Hubs, which in turn have multipart business keys. Determining how many attributes is too many is hard because the size (length) of the attribute values is also a factor in determining how well the result sets can be pruned.
Like the BK style, the typical load pattern for DV 2.0 with hash keys looks the same:
In the next post, I will show you how to maximize load throughput of a DV using Snowflake.
In the meantime, be sure to follow us on Twitter @SnowflakeDB and @kentgraziano to keep up on all the latest news and innovations on DV and Snowflake Cloud Data Platform.