
For this last post in my Data Vault (DV) series, I will discuss two more cool features of Snowflake Cloud Data Platform that you can take advantage of when building a DV on our platform. If you are not familiar with the DV method, please read this introductory blog post and part 1 of this series before reading this post. Part 2 of this series describes how to set up a DV for maximal parallel loading.
Using a VARIANT data type
In order to handle “big data” and, more specifically, semi-structured data, Snowflake invented a new, proprietary date type we call VARIANT. When a column in a table is created using this data type, it is possible to load JSON, AVRO, Parquet, XML, and Orc type documents directly into the table without having to transform or parse the document to fit a fixed schema. In this way, we are able to support true Schema-on-Read using SQL. (For a deeper dive, see this post and the related ebook or this webinar).
So how does this apply to a DV model? A few years ago Dan Linstedt, inventor of the DV method, asked me how we could possibly leverage this feature. My suggestion was simply to use it to hold the descriptive information found in a Satellite (Sat) table. Normally, a Sat table has the primary key (PK) of the parent Hub (or Link), a load date timestamp (LDTS), a hash difference column (HASH_DIFF in DV 2.0), the record source (RSRC), and then a set of attributes that are the descriptive information related to the parent object.
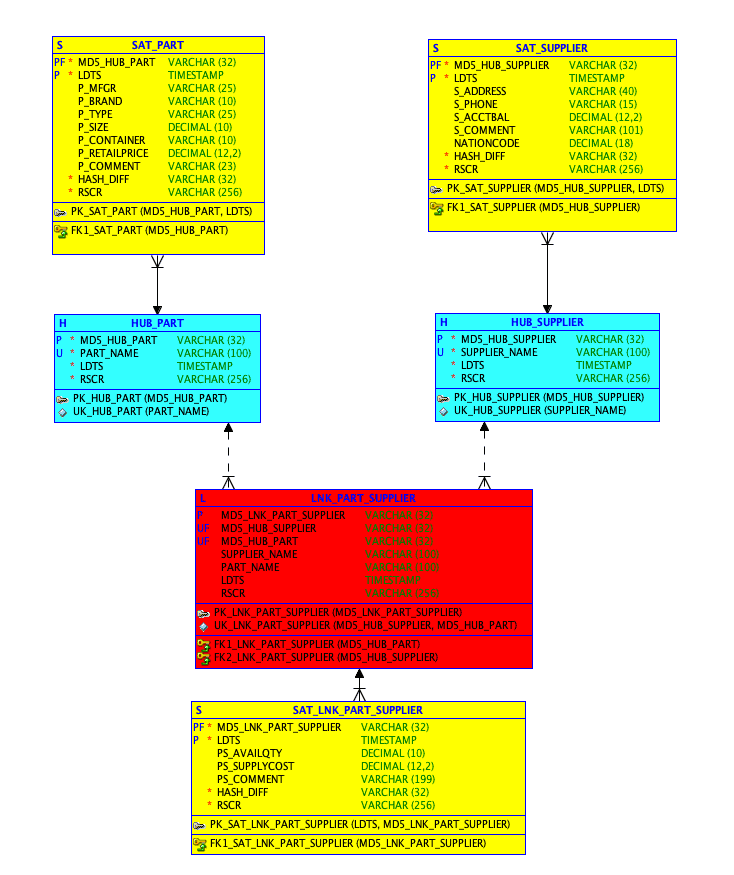
Figure 1: DV 2.0 model with standard Sat definitions
My proposal was that if the source of the data was a JSON document, we could model the Sat like this:
- Hub key
- LDTS
- VARIANT
- HASH_DIFF
- RSCR
Applying this to the model in Figure 1, the revised model would look like the one in Figure 2.
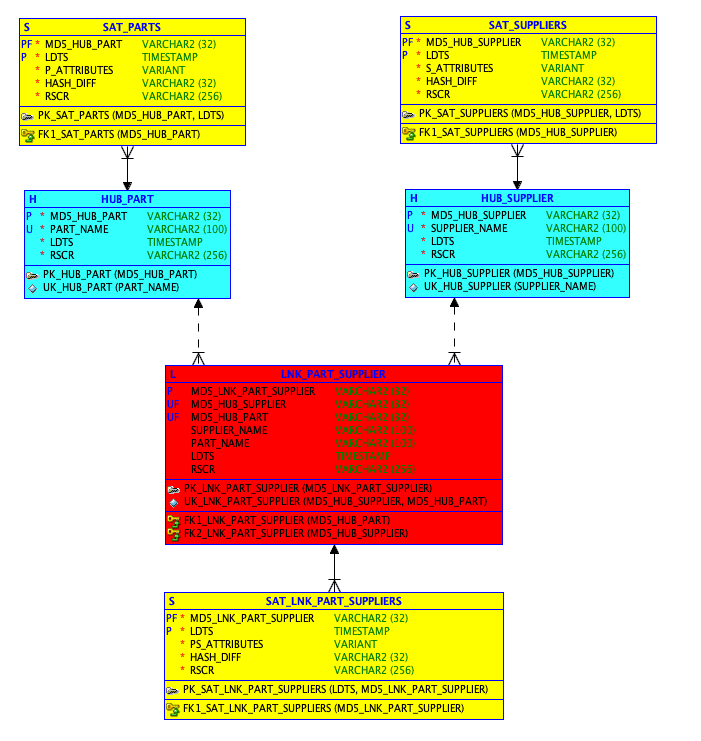
Figure 2: DV 2.0 model using VARIANT in Sats
With this approach, we can be even more agile by loading the entire document into the Sat without having to parse the keys into separate columns in the table. Why is this good? Well, imagine you have a JSON document with over 100 keys. You do some discovery and can easily find the attributes that would make up the business key for the Hub, but you don’t yet know what all of the other attributes are for and, in fact, the original requirements asked only for five of the attributes in the document, but you know that eventually some of the other attributes are likely to be required. You just don’t know which ones, or when. Because of the Schema-on-Read aspects of Snowflake, you don’t have to know all the requirements up front. Instead of taking a guess and loading just the original five, knowing you will be forced to re-engineer later, you simply load the entire document to the Sat in a VARIANT. Then, when the requirements change later, you already have the data loaded. That is agile!
But how do you expose the values in the JSON document (now stored in the VARIANT column) for users to query?
Build a Business Vault view
Using the Snowflake SQL extensions for JSON, you can build a view on top of the Sat to expose the attributes that the users asked for. Because Snowflake optimizes the storage and organization of data in a VARIANT, queries against this type of data are highly performant. Many Snowflake customers have been using this approach to expose JSON data for reports and dashboards for as long as I have been at Snowflake.
In DV parlance, any structure built on top of, or in addition to, the base raw DV is usually referred to as a Business Vault (BV). One use of a BV is to build objects that apply business logic that is generally applicable to all downstream applications and reports. In this case, the business logic is simply to expose and format the attributes that the business users asked for.
Here is an example of the code you could write to accomplish this:
CREATE OR REPLACE VIEW bizvault.vw_sat_parts ( hub_part_key, load_dts, manufacturer, brand, retail_price, record_source AS WITH sat_cte AS ( SELECT md5_hub_part, ldts, rsrc, p_attributes, -- This is the VARIANT column LEAD(ldts) OVER (PARTITION BY md5_hub_part ORDER BY ldts) AS lead_dts -- used to find current row FROM rawvault.sat_parts ) SELECT sat.md5_hub_part, sat.ldts, sat.p_attributes:p_mfgr::STRING, sat.p_attributes:p_brand::STRING, sat.p_attributes:p_retailprice::NUMBER, sat.rsrc FROM sat_cte sat WHERE lead_dts IS NULL -- gets current row only
The advantage of this approach is that it is extremely agile because it is very easy to change the view to add in new attributes as the business requirements evolve. That is much less work than re-engineering the DV tables and modifying and then testing the transformation process to parse out the new attributes. In addition, because this is a view, it enables near real-time access to the data in the DV. If your data pipeline is continually feeding data to the DV, or even doing micro-batches, each time a query is executed against this view, the results will be current. If you are doing batch processes today, this approach is future-proofed for when you need to load more often.
If the requirements mean that the BV view needs to be much more complex and you cannot get the queries to meet the SLAs, you always have the option to turn the view into a persistent table that is refreshed manually in a future iteration. From an agile perspective, I always recommend customers start by using views to validate their understanding with the business users and, thus, show them progress earlier in the development lifecycle. Only if you cannot meet the SLA by using the right-sized Snowflake virtual warehouse do you then consider persisting the data.
Building Information Marts on top of a Business Vault
Just as with using views for the BV objects, folks building a full DV architecture in Snowflake also use views to build out Information Marts and other reporting layer type objects (yes, views on views).
The benefit again is faster time to value. Views are very easy to adjust to new requirements, allowing the team to be more agile and responsive to the business users. If you have near real-time requirements for your data marts, views get you much closer to being able to deliver on that as well.
Another advantage is that with views, you can easily create any type of projection on top of your DV/BV repository. That means you can provide the end users with a star schema set of views, a Third Normal Form (3NF) (or virtual operational data store [ODS]) set of views, or even a wide, denormalized view for data scientists. And by using views, you can ensure they are all looking at the same data!
Multi-Table Insert
Another cool feature in Snowflake is the ability to load multiple tables at the same time using a single data source. This is called multi-table insert (MTI). I wrote about this in the earlier introductory blog post but did not include the code to handle the change data captures (CDC) aspects of a DV load pattern. Here is an example of how you can load a Hub and a Sat from a single stage table and at the same time add only new records to the Hub and new or changed records to the Sat using the DV 2.0 approach of a HASH_DIFF comparison.
INSERT ALL
WHEN (SELECT COUNT(*)
FROM dv.hub_country hc
WHERE hc.hub_country_key = stg.hash_key) = 0
THEN
INTO dv.hub_country (hub_country_key, country_abbrv, hub_load_dts,
hub_rec_src)
VALUES (stg.hash_key, stg.country_abbrv, stg.load_dts, stg.rec_src)
WHEN (SELECT COUNT(*)
FROM dv.sat_countries sc
WHERE sc.hub_country_key = stg.hash_key
AND sc.hash_diff = MD5(country_name)) = 0
THEN
INTO dv.sat_countries (hub_country_key, sat_load_dts,
hash_diff, sat_rec_src, country_name)
VALUES (stg.hash_key, stg.load_dts,
stg.hash_diff, stg.rec_src, stg.country_name)
SELECT MD5(country_abbrv) AS hash_key,
country_abbv,
country_name,
MD5(country_name) AS hash_diff,
CURRENT_TIMESTAMP AS load_dts,
stage_rec_src AS rec_src
FROM stage.country stg;
The first WHEN clause in the MTI statement checks to see if there are any existing rows in the target Hub and Sat tables (in this case, HUB_COUNTRY and SAT_COUNTRIES) that match the inbound stage data found in the STAGE.COUNTRY table. If the staged data indeed contains new country records and would result in a new Hub record, then the COUNT(*) will return zero (0) because the key does not exist in the Hub yet.
Similarly, the second WHEN checks to see if there is a record already in the Sat for that Hub and if it contains the same data (in which case, the HASH_DIFF would match). Again, a zero (0) count means either the record does not exist so a new Sat record needs to be inserted or the data in the stage table differs from the records already in the DV so a new version of the record needs to be inserted. So if the count is zero, a new record will be inserted into DV.SAT_COUNTRIES; otherwise the second WHEN just skips over that record.
With this method, even if you restart the load, or you get the same data twice, you will never load a duplicate into either the Hub or the Sat. Pretty cool, right? (Technically this is called an idempotent load.)
Conclusion
Well, that is it for this series on using a DV with Snowflake Cloud Data Platform. Over the last year, I have spoken to many organizations that are looking to adopt a DV in their move to Snowflake so I hope you found it useful to see some of the unique capabilities of Snowflake and how they can be leveraged to make your DV system even more agile and performant than before!
Until the next time, be sure to follow us on Twitter at @SnowflakeDB and @kentgraziano to keep up on all the latest news and innovations on Snowflake Cloud Data Platform.