
Setting Up for Maximal Parallel Loading
In this post, I will discuss how to engineer your data vault load in Snowflake Cloud Data Platform for maximum speed. If you are not familiar with the Data Vault (DV) method, please read this introductory blog post and part 1 of this series before reading this post.
Because Snowflake separates compute from storage and allows the definition of multiple independent compute clusters, it provides some truly unique opportunities to configure virtual warehouses to support optimal throughput of DV loads.
Along with using larger “T-shirt size” warehouses to increase throughput, using multi-cluster warehouses during data loading increases concurrency for even faster loads at scale.
Sequential Key Load Pattern
This is the standard pattern for loading DV 1.0 warehouses, as mentioned in part 1 of this series.
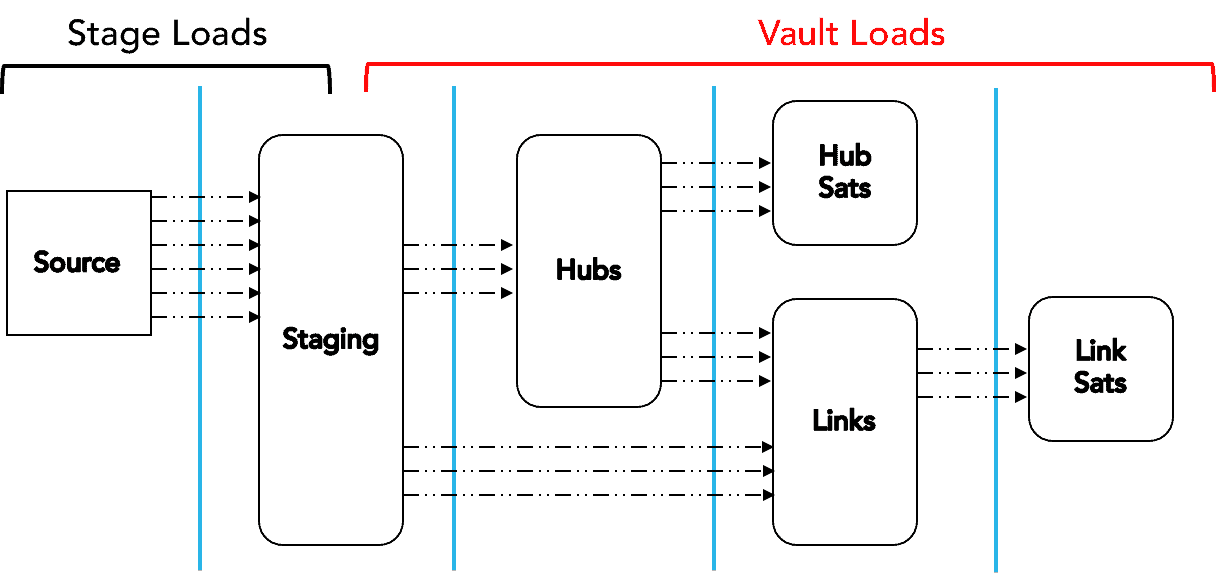
In DV 1.0 loading, you can do the stage loads (first vertical bar) with one multi-cluster warehouse (to allow for automatic scale-out concurrency of many tables being loaded at once). Moving downstream in the process, you can apply multiple virtual warehouses at different points in the process to allow for maximum throughput and concurrency while minimizing contention.
- You can run stage-to-Hub loads (second vertical bar) using a second multi-cluster warehouse. This allows the stage loads to run continuously without contention with the HUB loads.
- Because Hub surrogate keys must be built before loading Satellite (Sat) tables, you can run Hub-to-Hub Sat loads (third vertical bar) using the same multi-cluster warehouse, although you could use a separate, differently sized virtual warehouse if, for example, there were a lot of rapidly changing Sats with lots of columns. In that case, a larger warehouse might make more sense.
- Also after the Hub loads are done, you can run the Link loads in parallel to Hub Sat loads by using a third multi-cluster warehouse.
- Finally, you can run the Links-to-Link Sats loads (fourth vertical bar) using a fourth multi-cluster warehouse.
The diagram below shows where the different virtual warehouses would sit in the process.
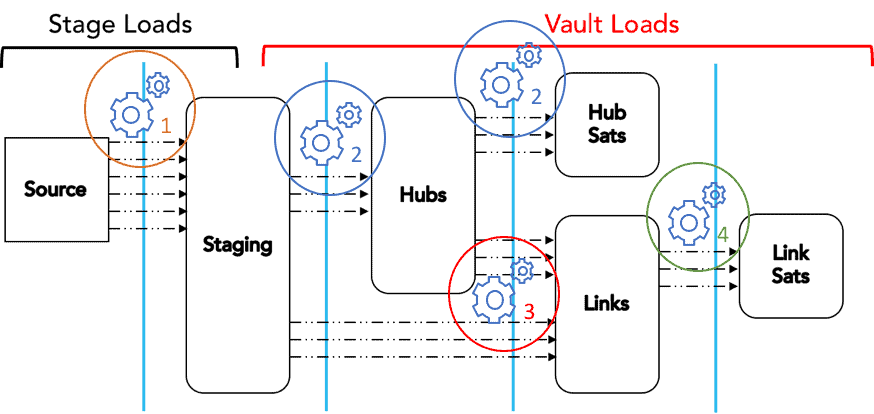
As with all virtual warehouse setups in Snowflake, we recommend enabling auto-suspend and auto-resume to minimize ongoing maintenance and cost.
Natural/Hashed Key Load Pattern
Because of the use of calculated (hashed) keys or natural business keys found in the source data, the DV 2.0 approach allows for maximum parallelization of the loading process, as depicted in the diagram below.
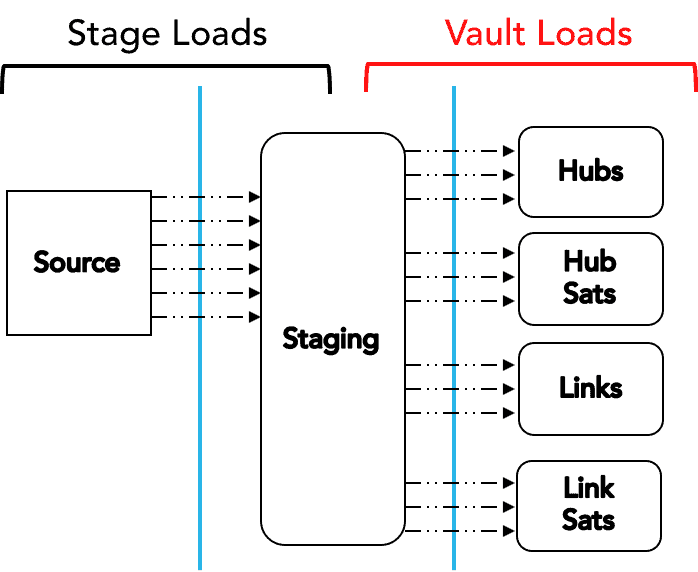
As with the DV 1.0 approach, Snowflake provides the opportunity to take full advantage of this load architecture.
The recommendations for setting up this approach are very similar in nature to the recommendations above. First, set up a multi-cluster warehouse for the stage loads (first vertical bar). From there, you can run all loads (second vertical bar) in parallel using four separate multi-cluster warehouses, as shown in the following diagram.
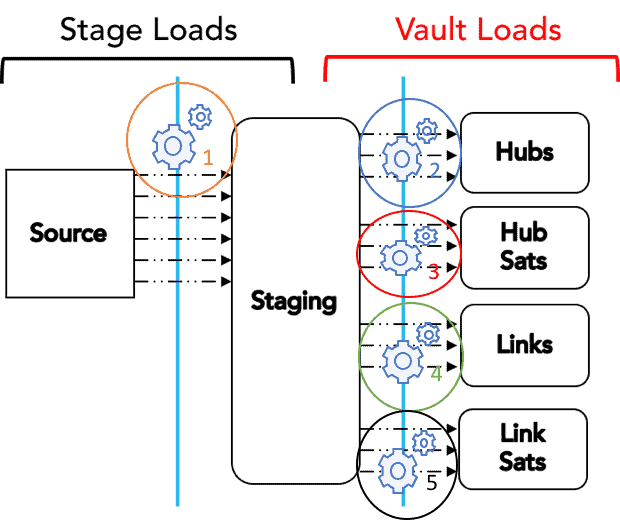
With this configuration, you can run continuous loading scenarios across your DV with zero contention. Using multi-cluster warehouses also allows you to iteratively add not only new source loads but new objects (Hubs, Links, Sats) to the model without having to be concerned about hitting a concurrency threshold. And remember: You pay only what you use, so even a multi-cluster warehouse with a setting of 10 for the maximum clusters, will turn those additional clusters on only if there is queuing in the loads.
Additional Tips
For both of the load patterns discussed here, we recommend you do some initial testing to determine the optimal T-shirt size for the various virtual warehouses. It’s likely you will find that you can use smaller warehouses for Hubs and Links, but you may benefit from using larger ones for Sats. The best way to pick a size is through empirical testing.
In part 3 of this series, I will discuss some additional features of Snowflake that you might use in a DV. These include using VARIANT column types and using multi-table inserts.
In the meantime, be sure to follow us on Twitter at @SnowflakeDB and @kentgraziano to keep up on all the latest news and innovations on DV and Snowflake Cloud Data Platform.
Special thanks to Keith Hoyle, Snowflake Solution Architect, for helping me vet and test these concepts, and for doing the original diagrams.