
The velocity of change is accelerating. The rate of change businesses are experiencing is just astounding. As many organizations have experienced during the pandemic, especially in their supply chain, the need for the data environment to be able to deliver faster is now mission-critical for all!
We need better data—but at a rate that’s much faster than before. Businesses need their data teams to become more responsive to changing data demands.
That means they need agility.
But they still must deliver data the business can trust and make decisions on.
That means they need governance.
We all know of the demands from anxious stakeholders who want everything now (well, really…yesterday!). They need data teams to be agile with data just like we are agile in software development.
But our data teams are often stilted.
They are overrun with new demands and huge backlogs that keep changing. Everything in the data world is still very manual, from building the database, to engineering the loads and transformations, to all of the testing. What about managing dev/test/prod environments? Forget about it. It’s all manual and likely not even close to being in sync. That means it may take weeks to implement a new change to production with proper testing.
This is not agile, particularly since a data team’s time frequently gets hijacked for “other” work.
No one trusts the data and it all just takes too long.
Despite massive investments in technology and people (and consensus that data is a company’s key strategic asset), a recent MIT Sloan Management Review study showed that only 9% of executives always trust that their data is accurate, and only 6% trust that their data is complete.
These are major challenges impeding us if we are going to build data-driven organizations.
We must solve this.
Why We Need DataOps
Snowflake delivers on governance and security, and those are key requirements from our customers. But agility is critical too. They need to be able to respond to the needs of the business. Having an agile platform such as Snowflake with elastic compute and low-cost storage is a great start, but you still need agile processes to move data through the data pipeline to deliver the promise and the value of that data. We need to balance governance and agility.

Figure 1: Snowflake’s platform enables many workloads and ensures data is secure and governed but to be fully agile, DataOps is also needed.
Key Questions
In meeting after meeting, we hear customers asking these questions:
- How do I apply the principles of the Agile methodology in a data-driven world?
- How can I do CI/CD for data?
- How can I manage dev/test/prod environments more easily?
- How can I orchestrate all the tools involved in my data pipeline?
To drill down a bit, I ask what folks mean by “CI/CD for data.” They explain that they want to not only manage changes to the CODE. They also want to change the SCHEMA design, and the DATA in that schema, and then TEST it properly and ORCHESTRATE it all easily, all with governance and auditability in mind.
As an example, one developer makes a change, a second person peer-reviews it, and a third person approves it to be merged into the project. Everything needs to be documented: who, what, where, and when.
I couldn’t believe it when I worked with big, global companies and found DBAs still making changes directly to the production data environment; in no other space I know of is this acceptable.
This issue was solved years ago with the advent of DevOps for software. “The Phoenix Project” outlined how to do it. Successful organizations who have adopted DevOps frameworks are pushing hundreds or thousands of code changes a day into production…but not with data.
We need a new way of thinking about how we deal with our data platforms and the data within them. That new way is DataOps.
What Is DataOps?
Fundamentally, DataOps is the application of DevOps principles to data. There is a bit of a definition outlined in the DataOps Manifesto, which clearly mirrors the Agile Manifesto for software development:

Figure 2: The principles of DataOps mirror the principles of the Agile Manifesto.
But for practical application, in the real world, this does not go far enough.
#TRUEDATAOPS
To try to address all of this, a few of my colleagues and I decided to create a new DataOps movement called #TrueDataOps. So with Justin Mullens and Guy Adams of DataOps.live taking the lead, we authored truedataops.org to articulate our detailed philosophy around managing data in the cloud.
Over the last year, we started discussing the needs of Snowflake customers for DevOps and DataOps specifically. We have been working on how to bring the world of DevOps—true DevOps—to data. How do we harness all the best practices that DevOps has shown us over the last 20 years and apply them to data? So, we collaborated on developing a refined vision of what we now call “True DataOps.” This vision articulates what it really means to apply DevOps principles in the cloud along with how we deliver DataOps to the world. Collectively, we realized that only now, and because of the unique capabilities of Snowflake, has our vision of True DataOps become achievable.
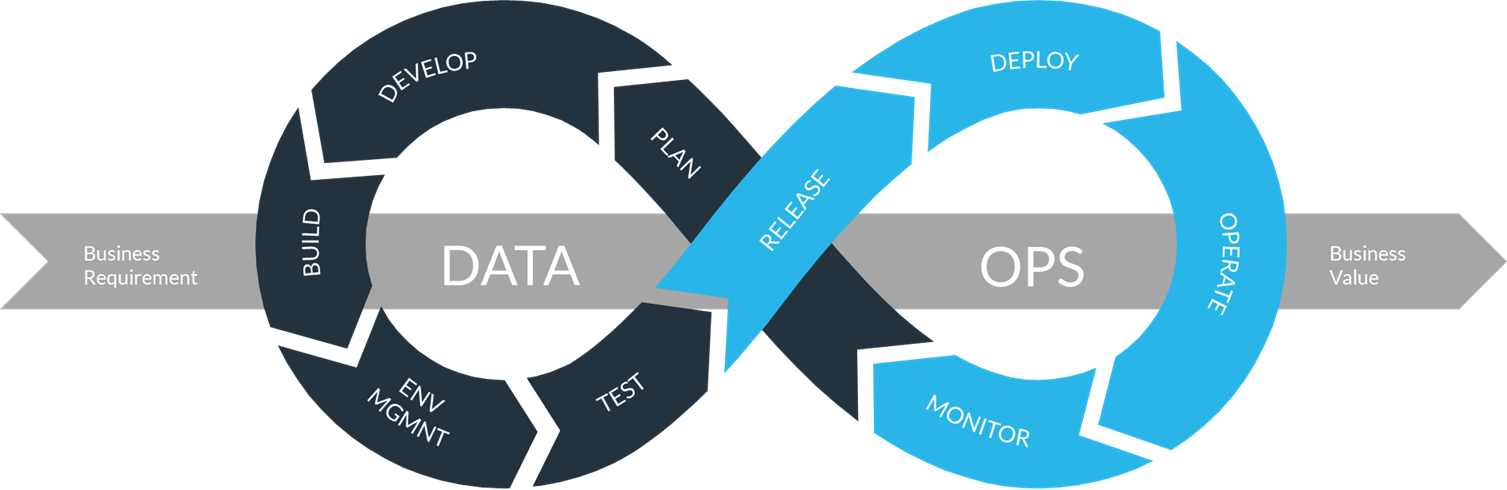
Figure 3: The DataOps lifecycle
The 7 Pillars of True DataOps
To give a little more detail about what we think a True DataOps framework should look like, we decided on these fundamental pillars (feature sets) that we believe are required to be truly successful.
ELT: Rely on the data platform more. Use low-cost storage and elastic compute, and leverage Schema-on-Read whenever possible to achieve agility and keep the data in one place. Stop extracting the data from the platform to transform it, because that adds latency and reduces your agility.
Agility and CI/CD: Your DataOps process should have a repeatable, orchestrated pipeline for everything (data and schemas) so you can achieve the goals of continuous integration and continuous development.
Component design: We should build all of our data processes the same way we build software: not large, monolithic systems but small, easy-to-understand, easy-to-maintain, easy-to-test pieces that can then be assembled into the advanced systems we need. A great example of this in the data modeling world is the Data Vault 2.0 approach.
Environment management: This is all about building our production, development, and test instances but also includes managing trunk and feature branch databases to enable CI/CD.
Governance, security, and change control: Every change must be recorded in a shared repository so it can be tracked, replicated (or rolled back), properly approved, and reported on for audit.
Automated testing: This, in particular, is critical. Current approaches are either to make a change every few months and manually review them with a few tests before moving to production or to make changes every day and hope all goes well. Neither approach is acceptable, nor should they be acceptable because data is a strategic asset. With an automated testing approach and an automatically scaling platform (such as Snowflake), you should be able to run thousands of tests in minutes.
Collaboration and self-service: You need to enable the entire organization to access governed data using structured anonymization. For example, you can orchestrate data sharing so the organization can put different subsets of data into different Snowflake accounts and have it all tracked and masked appropriately.
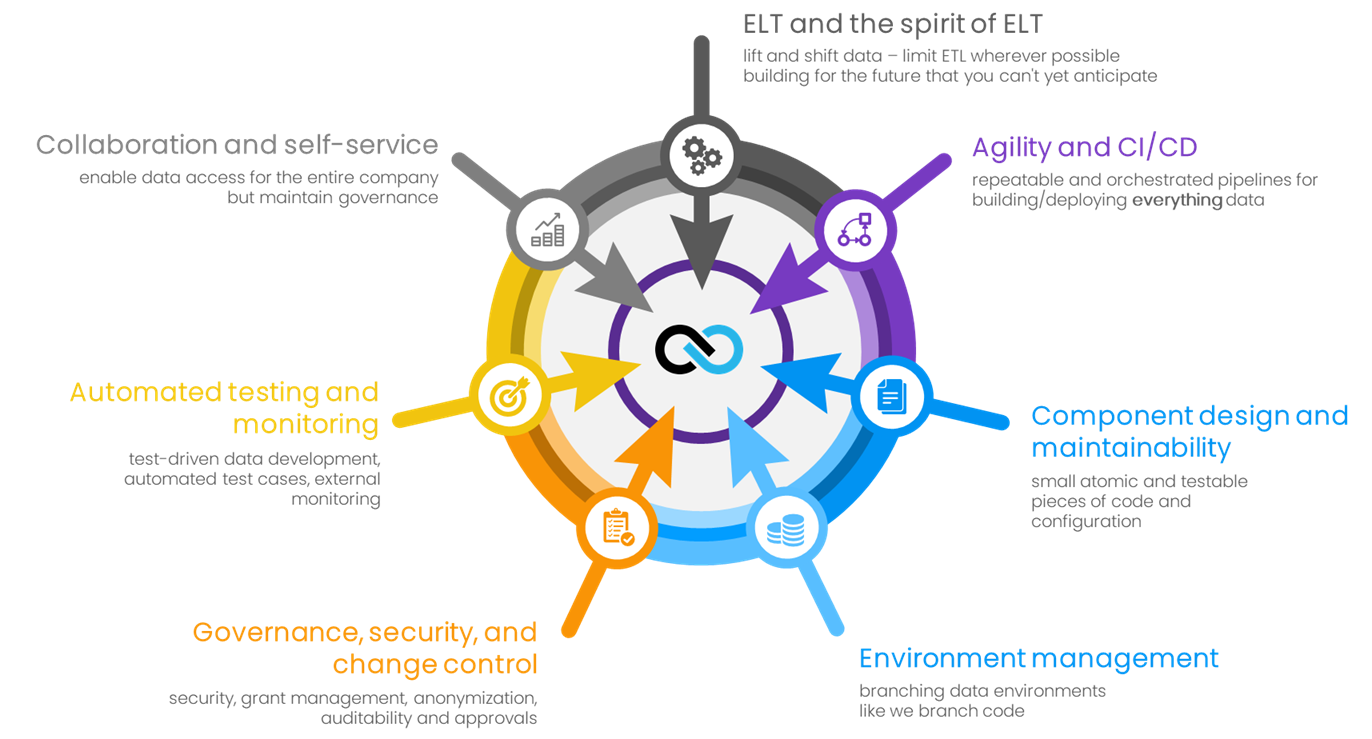
Figure 4: The seven pillars of True DataOps
This is the new framework. The goal is to meet the needs we are hearing from customers: agility and governance.
Benefits of True DataOps
So, if we adopt a True DataOps approach, how will it help?
Maintainability
With everything broken down into small component parts, each small piece does one thing, does it well, and is easy to understand and maintain. Monolithic systems are virtually impossible (and incredibly expensive) to maintain, as legacy systems have shown.
Testability
With the ability to deploy either the entire system or part of the system with the click of a button or by running a command, everything becomes easier to test. We should actually be building tests alongside our code; development and testing are two sides of the same coin.
Availability (including rollback)
If every change has been tested multiple times and then peer-reviewed and approved, the availability of the resulting system becomes far higher (for example, there are fewer bugs to take it down). In the situation where anything goes wrong or gets interfered with, just rerun the deployment from the repository and start again.
Speed of development
Despite any initial concerns of “isn’t this more work,” the result is a dramatic improvement in the productivity and speed of development teams. Work is easier to pick up, is easier to test, and provides the ability to possibly do up to 20 or even 30 complete lifecycles per hour (versus one or two a week with a great team). It’s also easier to deploy. This allows an agile way of working to emerge. This approach couldn’t have happened without DevOps. Done right, this is a low-code or no-code approach.
Getting Started
If you are a Snowflake customer, you can start today by clicking the DataOps tile in Snowflake Partner Connect:

Figure 5: The DataOps tile in Snowflake Partner Connect
This leads to a product that’s available today, built by an experienced Snowflake partner, and specifically supports the Snowflake Data Cloud and delivers this vision of True DataOps. It uses git, dbt, and other tools (under the covers) with a simplified UI to automate all this for Snowflake users.
Using this approach and these principles, you can start a True DataOps operation today. Doing so will require a cultural shift in how you approach your data work, but the payoff is huge. You can achieve agility and governance in your data platform.
If not now, when? If not you, then who?
Be a Data Leader!