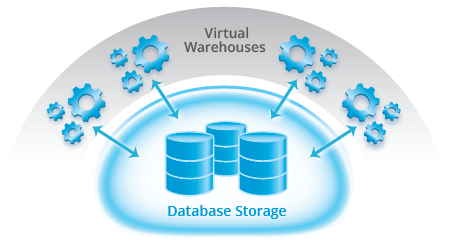
Hopefully you had a chance to read our previous top 10 posts. As promised, we continue the series with a deeper dive into another of the Top 10 Cool Features from Snowflake:
#3 Support for Multiple Workloads
With our unique Multi-cluster, shared data architecture, Snowflake can easily support multiple and disparate workloads. This is a common issue in traditional data warehouses so it makes total sense to be able to keep disparate workloads separate, to truly avoid resource contention, rather than just saying we support “mixed” workloads.
In legacy data warehouse environments, we often found ourselves constrained by what we could run and when we could run it for fear of resource contention, especially with the CPUs. In many cases it was impossible to refresh the data during the day because the highly parallelized, batch ETL process, while tuned for maximum throughput, usually hogged all the CPUs while it ran. That meant virtually no reporting queries could get resources so they would just hang. Likewise a complex report with calculations and massive aggregations would cause normally fast, simple reports to languish. And there was no way you could let any business users in the system to do exploratory queries as those might also cause everything else to hang.
Because of the separation of compute and storage native to Snowflake’s architecture, as previously highlighted, you can easily spin up a set of compute nodes (we call them Virtual Warehouses) to run your ELT processes, and another set to support your BI report users, and a third set to support data scientists and data miners. In fact you can spin up (or down!) as many virtual warehouses as you need to execute all the workloads you have.
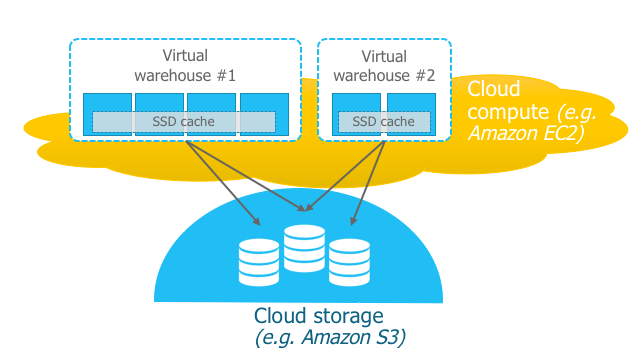
So not only does each virtual warehouse share the same data (insuring consistent results), they are able to do so without being affected by operations being launched in other virtual warehouses because they are using completely separate resources. Hence there is no more resource contention!
With the Snowflake Elastic Data Warehouse, there is no more need to run the data loads at night just to avoid slowing down the reports. No more worry that one runaway query will impact the loads or other users. You can now run loads (e.g., real time, micro-batch, etc) at any time and thus provide your analysts and users current data on a more frequent basis.
And even better – no special skills or secret configuration settings are required to make this work. It is the way Snowflake’s Data Warehouse as a Service (DWaaS) is built by design.
Nice!
For a quick look at how this works, check out this video.
Thanks to Saqib Mustafa for his help and suggestions on this post.
As always, keep an eye on this blog site, our Snowflake Twitter feeds (@SnowflakeDB), (@kentgraziano), and (@cloudsommelier) for more Top 10 Cool Things About Snowflake and for updates on all the action and activities here at Snowflake Computing.