
Snowflake enables organizations to be data-driven by offering an expansive set of features for creating performant, scalable, and reliable data pipelines that feed dashboards, machine learning models, and applications. But before data can be transformed and served or shared, it must be ingested from source systems. The volume of data generated in real time from application databases, sensors, and mobile devices continues to grow exponentially. While data generated in real time is valuable, it is more valuable when paired with historical data that provides context. That proves to be a difficult task for data engineering teams that have to manage separate infrastructure for batch data and streaming data.
To address this challenge, we are happy to announce the public preview of Snowpipe Streaming as the latest addition to our Snowflake ingestion offerings. As part of this, we are also supporting Snowpipe Streaming as an ingestion method for our Snowflake Connector for Kafka.
Whether you use Snowpipe Streaming as a standalone client or as part of your Kafka architecture, you can create scalable and reliable data pipelines with a fully managed underlying infrastructure with built-in observability.
Streaming ingestion is not meant to replace file-based ingestion, but rather to augment it for data loading scenarios where it makes sense, such as:
- Low-latency telemetry analytics of user-application interactions for clickstream recommendations
- Identification of security issues in real-time streaming log analytics to isolate threats
- Stream processing of information from IoT devices to monitor critical assets
Snowpipe Streaming enables low-latency streaming data pipelines to support writing data rows directly into Snowflake from business applications, IoT devices, or event sources such as Apache Kafka, including topics coming from managed services such as Confluent Cloud or Amazon MSK.
„Before testing the Snowflake Connector for Kafka which leverages the Snowpipe Streaming framework, we have been using a custom service that imports logs into a cloud object store and then uses Snowpipe to load files in small batches,” said Yicheng Shen, Principal Cloud Architect, Securonix. “Now we are able to ingest our data in near real time directly from Kafka topics to a Snowflake table, drastically reducing the cost of ingestion and improving our SLA from 15 minutes to within 60 seconds. This solution is both scalable and reliable, as we have been able to effortlessly ingest upwards of 1GB/s throughput.”
How does Snowpipe Streaming work?
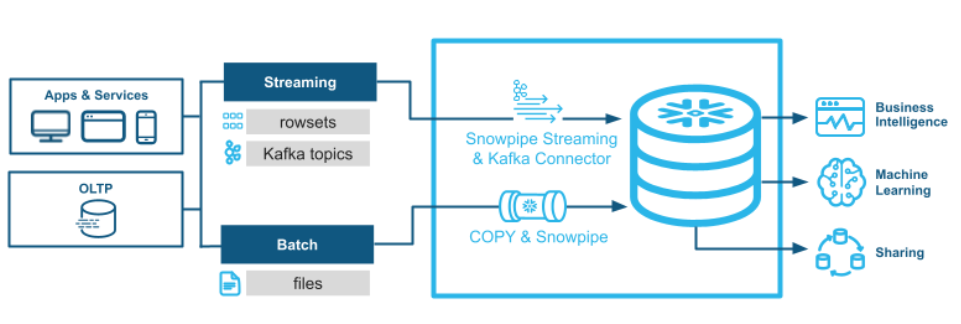
This new method of streaming data ingestion is enabled by our Snowflake Ingest Java SDK and our Snowflake Connector for Kafka, which leverages Snowpipe Streaming’s API to ingest rows with a high degree of parallelism for scalable throughput and low latency. Rather than streaming data from source into cloud object stores then copying it to Snowflake, data is ingested directly into a Snowflake table to reduce architectural complexity and reduce end-to-end latency.
Removing this intermediary step in cloud storage is critical for low-latency data ingestion as streaming data often results in small file sizes from frequent data flushing, which adds operational overhead from cloud storage transactions and network request latency. At scale, these latencies compound to turn single-digit second streaming data pipelines into double-digit or even minute-level data pipelines.
By offering a native streaming data ingestion offering to Snowflake’s Data Cloud, Snowpipe Streaming simplifies the creation of streaming data pipelines with sub-5 second median latencies, ordered insertions of rows, and serverless scalability to support throughputs of gigabytes per second. Data engineers and developers will no longer need to stitch together different systems and tools to work with real-time streaming and batch data in one single system.
Why Snowpipe Streaming?
Streaming data and historical data should not live in silos or cause infrastructure management complexity. For low-latency streaming ingestion, Snowpipe Streaming and the Snowflake Connector for Kafka with Snowpipe Streaming support are two new tools in your Snowflake data ingestion toolbox to directly stream into Snowflake tables. For batch and continuous file ingestion workloads, Copy and Snowpipe continue to provide all the scalability and governance benefits of the Snowflake platform, enhancing the value of your data.
And to bring even more value to your data, the Snowflake platform has a wide range of deeply integrated components that can help you build modern data pipelines. Data can be prepared and transformed using your language of choice with Snowpark, pipelines can be orchestrated with tasks, and results can be securely shared with others. Snowpipe Streaming is just the beginning of our streaming ingestion story, and we plan to continue improving our platform for even better performance, functionality, and cost-efficiency.
Try Snowpipe Streaming today
Find more details in our Snowflake ingestion best practices webinar and build your first ingestion pipelines using the Getting Started with Snowpipe Streaming Quickstart. And if you are using Amazon Managed Streaming for Apache Kafka (MSK), you can get started using this guided demo.
For additional information, our documentation is always a great place to start. Stay tuned for part 3 of my blog series on “Best Practices for Data Ingestion with Snowflake,” in which I will dive deeper into comparing the technical aspects of batch vs. streaming ingestion.
Give Snowpipe Streaming a try today to streamline your streaming data ingestion, and let us know your feedback about the feature. Generally, previews are not supported for production use, but they are a great way to get ready for production use when the general availability release is available.


