
The Snowflake Connector for Spark (“Spark Connector”) now uses the Apache Arrow columnar result format to dramatically improve query read performance.
Previously, the Spark Connector would first execute a query and copy the result set to a stage in either CSV or JSON format before reading data from Snowflake and loading it into a Spark DataFrame. Typically, downloading and deserializing the CSV or JSON data consumed the bulk of end-to-end processing time when data was read from a Snowflake Cloud Data Platform data source.
With this 2.6.0 release, the Snowflake Spark Connector executes the query directly via JDBC and (de)serializes the data using Arrow, Snowflake’s new client result format. This saves time in data reads and also enables the use of cached query results.
Benchmark results: Cacheable, speedy reads with Apache Arrow
In this benchmark, we ran a Spark job that reads the data in the LINEITEM table, which has a compressed size of 16.3 GB in Snowflake. The table is a standard TPC-H LINEITEM table. We first captured the increased throughput as a result of the more-efficient columnar binary data format by performing a raw new read from the Snowflake table.
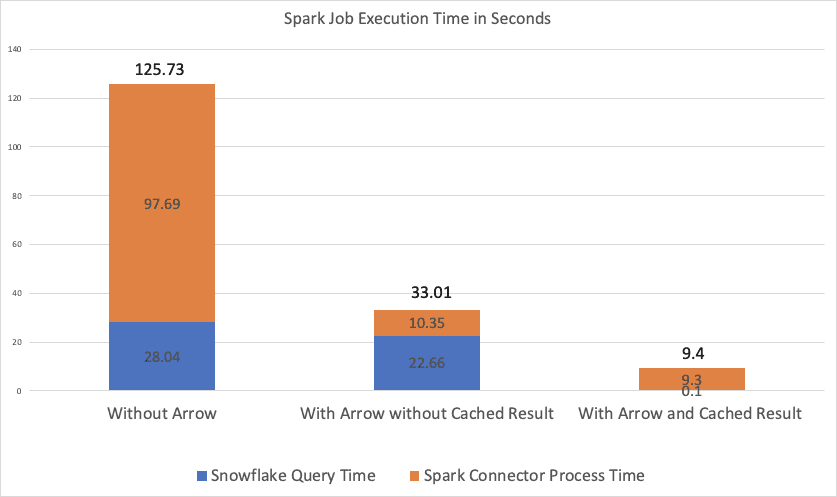
We saw an immediate 4x improvement in the end-to-end performance of this Spark job. This improvement is due to a 10x performance improvement in the time spent by the Spark Connector to fetch and process the results of the Snowflake query.
In addition, Snowflake has a query-result cache for repeated queries that operate on unchanged data. By storing results that may be reused, the database can avoid recomputation and simply direct the client driver to read from the already computed result cache. In previous versions of the Spark Connector, this query result cache was not usable. Beginning in version 2.6.0, the Spark Connector will issue pushdown jobs to Snowflake using direct queries; this means that the Spark Connector is able to take full advantage of the query result cache. We also saw this benefit in our benchmark results, which are shown below. With cached reads, the end-to-end performance for the Spark job described above is 14x faster than when using uncached CSV-format reads in previous versions of the Spark Connector.
We ran a four-worker Spark cluster with AWS EC2 c4.2xlarge machines, Apache Spark 2.4.5, and Scala 2.11. The Snowflake warehouse size was 4X-Large. The Snowflake deployment’s cloud and the Spark cluster deployment were in the same cloud region: US-West-2 (Oregon). The following chart shows the results:
Scala Code Used for the Benchmark Test
The following snippet shows the code used for the benchmark test with Arrow. Configuring “use_copy_unload” as “true” can test the performance without Arrow.
import net.snowflake.spark.snowflake._
// Snowflake Spark Connector options
// The default value of "use_cached_result" is "false".
// It is "true" means to disable this feature.
val sfOptions: Map[String, String] = Map(
"sfSSL" -> "on",
"sfUser" -> "<snowflake_user_name>",
"pem_private_key" -> "<private_key>",
"use_copy_unload" -> "false",
"use_cached_result" -> "true",
"sfDatabase" -> "<snowflake_database>",
"sfURL" -> "<snowflake_account>.<snowflake_cloud_domain>",
"sfWarehouse" -> "snowflake_warehouse",
"partition_size_in_mb" -> "60"
)
// Test table is TPCH LINEITEM which has 600M rows.
// Its compressed size in Snowflake is 16.3GB.
val sourceTableName = "LINEITEM"
val sourceSchema = "TPCH_SF100"
val df = sqlContext.read
.format("net.snowflake.spark.snowflake")
.options(sfOptions)
.option("dbtable", sourceTableName)
.option("sfSchema", sourceSchema)
.load()
// Clear cache before any test
sqlContext.clearCache()
// Execute cache() and show(1) to read all data into cache
// and show one row. The time to show one row can be ignored.
// The DataFrame execution time is regarded as the reading time.
val startTime = System.currentTimeMillis()
df.cache().show(1)
val endTime = System.currentTimeMillis()
val result_msg = s"read time: ${(endTime - startTime).toDouble/1000.0} s"
println(result_msg)
GETTING STARTED WITH ARROW SUPPORT IN SNOWFLAKE CONNECTOR FOR SPARK
The Arrow format is available with Snowflake Connector for Spark version 2.6.0 and above and it is enabled by default. For more details, see the Snowflake Connector for Spark documentation.