One of the oldest challenges in data warehousing is getting data into the data warehouse without getting in the way of other queries and workloads. In this Snowflake Challenge, we’re going to demonstrate how Snowflake makes that possible with concurrent load and query.
What’s the Challenge
In a traditional data warehouse, all workloads compete to use the same resources. As a result, ETL processes like loading and data transformation can severely impact the response time of interactive workloads and vice-versa. To avoid this, ETL processes are carefully scheduled to run during « idle » windows (e.g. overnight) in order to avoid resource contention.
However, it’s increasingly difficult to find such windows because programmatic jobs and geographically distributed teams are making « idle » windows hard to find. Also, users are increasingly unwilling to wait 24 hours to get access to new data–the sooner you can analyze new data, the sooner you can react to what it tells you. Shortening the data pipeline takes on even more importance with increasing numbers of applications that incorporate analytics, making it unacceptable to load new data only once per day.
Overcoming this challenge would make it possible to dramatically shorten the time from data to insight while completely eliminating the resource management headache.
Why Traditional Data Warehouses Have this Challenge
ETL processes are generally resource-intensive operations because reading external data and writing it to the data warehouse’s storage layer require significant I/O and network bandwidth. Further, converting the data into the data warehouse’s optimized internal format (e.g. columnarizing, compressing, calculating statistics, etc.) requires significant CPU bandwidth.
In a traditional data warehouse, all workloads that run concurrently are competing for the same network, I/O, and CPU resources. As a result, running multiple workloads in parallel impacts performance of those workloads. Even workload management doesn’t solve the problem—it gives you control over which workload gets priority, but that just changes which workload sees the biggest slowdown.
The challenge is rooted in the fundamental architectures of traditional data warehousing. In the shared-nothing MPP (massively parallel processing) architecture used by most traditional data warehouses, data is partitioned across a set of nodes in a cluster.
![]()
When two workloads need to access the same data, they need to run on the nodes storing that data and hence compete for the same network, I/O, and CPU resources. Although some systems allow addition of nodes, that’s a significant configuration change that isn’t practical to do frequently—it requires data to be fully repartitioned across the cluster, an operation that consumes significant network and I/O resources such that it can take hours or even days to complete before the new nodes can be fully utilized. That operation typically cannot be done fully online—at best, the cluster needs to go into a read-only mode until repartitioning is complete. Even then, adding more nodes doesn’t really solve the problem—workloads are still competing for the same resources in the cluster even when there are more resources.
In the shared-disk architecture used by data warehouses such as Oracle, the I/O subsystem is shared by all of the nodes in the cluster. That means that even with additional nodes, an I/O intensive workload like ETL will consume a significant share of I/O bandwidth, which in turn slows down other concurrent workloads.
![]()
How Snowflake Addresses the Challenge: Concurrent Load and Query
Snowflake was built with a unique new architecture that makes it possible to solve this challenge. Snowflake’s unique multi-cluster, shared data architecture makes it possible to allocate multiple independent, isolated clusters for processing while sharing the same data. Each cluster (we call them “virtual warehouses”) can both read and write data, with full transactional consistency ensured by Snowflake’s cloud services layer. The size and resources of each virtual warehouse can be chosen independently by the user based on the characteristics and performance requirements for the workload(s) that will run on each virtual warehouse.
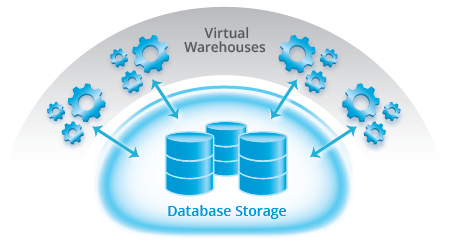
Snowflake ensures that transactions executed on different virtual warehouses are globally ACID, even when the same data is accessed concurrently. Readers always read the latest consistent version of data such that new or updated data is visible only once a transaction that modifies data has committed. This read consistency is ensured globally across all virtual warehouses without locks and without contention.
Each virtual warehouse can also be created, suspended, resumed, and dropped at any time without unloading and reloading data, making it possible to use a virtual warehouse only for as long as it is needed.
This unique architecture makes it possible to run multiple workloads concurrently without performance impact. Each workload, for example an ETL workload and an analytic workload, can have its own isolated resources even while operating against the same databases and tables. Not only does that mean that the ETL workload does not impact the performance of an analytic workload, but also each virtual warehouse can be sized specifically for the needs of its workloads—the virtual warehouse for ETL can be sized to provide large amounts of I/O bandwidth while the virtual warehouse for analytics can be sized to provide necessary CPU and memory resources.
Further, each virtual warehouse can be run only when needed—the virtual warehouse for ETL can be resumed only when the ETL workload needs to run, as can the virtual warehouse for analytics. You don’t need to pay for virtual warehouses when you aren’t using them.
How we Demonstrated It
To demonstrate Snowflake’s approach, we created two virtual warehouses:
- A virtual warehouse named ETL_WH to run the ETL process
- A virtual warehouse named ANALYTIC_WH to run other queries
Using ANALYTIC_WH, we kicked off a JMeter script that simulated 10 concurrent users repeatedly running a series of analytic queries against a 10 TB database names SALES.
Once that workload was executing, we used the ETL_WH to load 1 TB of new data into the same set of tables being accessed by the analytic query workload. Once the data load was completed, the same warehouse refreshed some materialized aggregates and recomputed some reports. At the end of that work, the ETL job committed, making all changes to the data in the SALES database visible to the analytic workload. To watch for performance impact, we monitored the queries / second completed by the analytic warehouse using JMeter.
We captured all of this in the video below. As you can see, running the ETL and analytic workloads concurrently had no impact on the performance of the analytic workload—both workloads are isolated by virtue of Snowflake’s architecture, even when they access the same data set.
We Want to Hear from You
We’re interested in hearing your thoughts on this challenge, and in hearing about your data warehousing challenges. Join the conversation here, and stay tuned for future challenges!