
Organizations that hold personal information must make sure that it is properly governed to meet compliance requirements and mitigate risk. But first they need to classify information as personal to know where that personal information resides in their Snowflake account. Once they know where it is, they can track it with System Tags, audit who has access to it, and also put in place policies to make sure that it is only accessible to those who require access. However, many organizations struggle to classify their data because they rely on slow, error-prone, and manual processes or third-party tools that are more than they need, too expensive, and may extract a sample of this information out of Snowflake in order to classify it, increasing risk for the organization. To remove these issues, we released Data Classification into public preview in February 2022.
We are excited to announce that Snowflake’s native Data Classification is now generally available on AWS and Azure, and soon GCP. We have made a number of performance and accuracy improvements with the deployment of a new model, and we also added support to classify simple variant columns and output the result of all columns. To access the latest version of data classification, you will need to opt in to the June 2022 behavior change release (see here). In this blog post, we will share some best practices to help you get the most out of Snowflake’s native Data Classification, but first it’s helpful to understand how data classification works to use it effectively.
How it works
After invoking the extract_semantic_categories function on a table, view, or external table to be classified, a uniformly random sample of rows is taken. It is possible to specify the sample size, but it cannot be larger than 10,000. The sample size is limited to 10,000 because a sample of this size is typically more than enough to determine the category of a column, especially if the data is relatively dense, clean, and canonicalized. The sample data is then analyzed in two ways: The cells in each column are compared against matchers and the column names are checked for matching substrings. These two analyses then form features that are inputs into a pre-trained machine learning model. The model then returns the predictions for each column as two System Tags, an associated probability, and any alternates.
Matchers refer to a variety of techniques that we use to analyze cell values. For example:
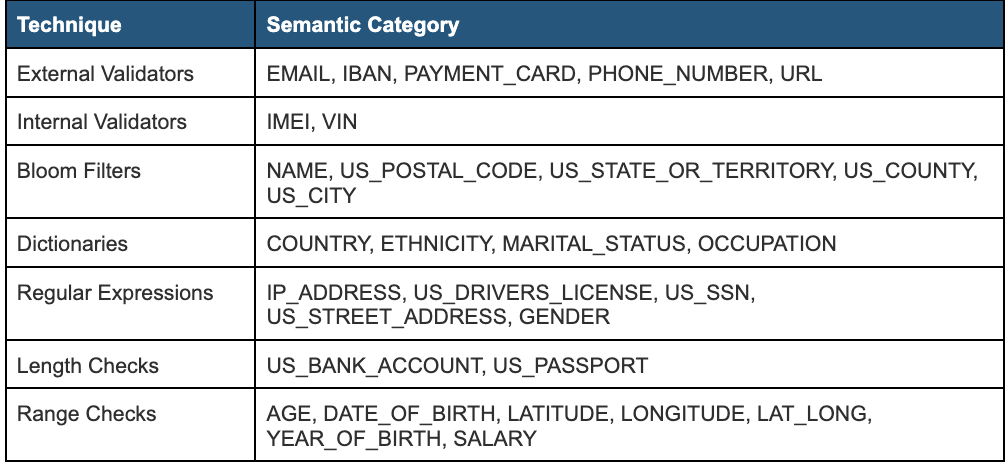
Each category for the supported data type is run against the associated matchers, and the results are then passed in as a feature to the model. For example, if the cells are emails, the EMAIL matcher will be 1 and the other categories will be zero. In another example, let’s say we have a column with a nine-digit integer, it will match US_SSN and US_PASSPORT and those matchers will return values less than 1 but not strong enough on their own to determine the category of the column. Therefore, we utilize column name substring matching.
For each category we support a variety of substrings in column names that help the model determine the category, especially if the signal from the cells is not strong enough as in the nine-digit number case above. Substrings are not case-sensitive and can be a part of the column name separated by an underscore, space, dash, or period, or it can be the entire column name. For example, the supported substring for email is “email”; therefore, the column name can be “email” or “customer_email” or “email-address” or “customer.email.information” or “customer email”. The table below lists the supported substrings for each semantic category.

The following categories currently require the substrings to match:
- us_bank_account
- us_drivers_license
- us_passport
- phone_number
- us_ssn
- age
- date_of_birth
- latitude
- longitude
- year_of_birth
- salary
The reason we require it for these specific categories is because the cell matching alone does not provide a strong enough signal. If you recall the nine-digit number earlier, the only way for the model to distinguish between a passport and a Social Security number would be the column name. These categories have similar issues. There is no way for the model to know if a column with integers between 0 and 100 are ages or the number of movies a person has watched over the last year without some additional context given by the column name.
Tips for getting the most out of Data Classification in Snowflake
Now that you know how classification works, we are going to provide some best practices to get the most out of data classification.
Use Snowflake-provided metadata to search, prioritize, and perform impact analysis.
You may have thousands of tables and don’t know where to start. Using views and metadata in your Snowflake account, you can query various objects to determine how to take action.
We recommend starting with tables, views, and external tables that are accessed the most often. You can determine that by querying access history. An additional step you can take is to query for specific column names that you think may indicate personal information by using SHOW COLUMNS.
After you have classified highly accessed objects and potentially personal information based on column names, you can then start to classify the dependencies, and you can find those by querying the Object Dependencies View.
In many organizations, personal information is grouped together so the next step would be to classify all the objects in the schemas where personal information was found.
If your organization has tagged databases or schemas, you could also query the Tag Reference View to find those and determine if the tables in those databases or schemas require classification.
Use descriptive column names.
Column names, while not required for classifying most categories, are very helpful to improve accuracy and in some cases are necessary to classify certain categories. We recommend publishing a guideline for column naming conventions for your organization that takes into account the listed substrings.
Use data types that will aid in cell matching.
For example, AGE is expected to be a NUMBER.
Flatten your table first to classify VARIANT columns.
If you want to classify VARIANT columns that are in JSON or XML format, first flatten your table. We do support classifying simple variants, which are columns that have a VARIANT data type but contain a single data type such as VARCHAR or NUMBER, by casting those columns to those types and then analyzing, but we recommend using appropriate data types (see above).
Save to a temporary table.
Save the results of the EXTRACT_SEMANTIC_CATEGORIES function to a temporary table to review and revise the results before applying the tags with the ASSOCIATE_SEMANTIC_CATEGORIES stored procedure. This temporary table can also be flattened to more easily consume the JSON output.
Create a history of classification results.
Once the tags have been applied, it is useful to retain these results in a table to compare with subsequent runs of data classification. This will help identify changes in the data, and we recommend checking the underlying data to see if sensitive data was inadvertently put in the wrong location. Additionally, this table can function as a data catalog.
Use the right-sized warehouse.
Data classification processing time scales with the number of columns. We recommend that for tables with fewer than 100 columns, a SMALL warehouse; if processing time is not a concern, then an X-SMALL is also an option, but note that processing times may be increased by up to 50%. For tables with columns between 100 and 300, we recommend a MEDIUM warehouse, and a LARGE warehouse for tables with more than 300 columns.
Inspect non-classified columns.
After running classification
select table_name, table_catalog from snowflake.account_usage.columns c
where not exists(select * from snowflake.account_usage.tag_references t
where c.column_id = t.column_id)
and deleted is null
group by table_name, table_catalog;Next steps
As of the June 2022 behavior change release, Data Classification is generally available for Enterprise or Business Critical Snowflake accounts in all regions of AWS and Azure, and soon GCP. To start using these capabilities, simply enable the behavior change release on your Snowflake account as described in this documentation. If you have feedback about the feature, please let us know!
