
Snowflake is the data backbone for thousands of businesses, enabling data access and governance needed to deliver value. Interactive use cases in some data applications and embedded analytics, however, pose a particular challenge. Traditionally, you needed an additional caching layer to provide the required speed and throughput these solutions require—which also increased costs and architectural complexity.
Today, we’re thrilled to announce that we’ve improved our elastic performance engine to support these interactive use cases. This update, now available in public preview, includes dramatic increases in concurrency, throughput, and faster execution.
During the private preview, HUMAN, a cybersecurity company, was able to simplify its architecture and migrate its interactive dashboards to Snowflake. This increased data freshness from hours to minutes and brought down the peak latency of queries from more than a minute to less than two seconds. At Snowflake BUILD 2021, Swati Baradia, VP of Platform Engineering at HUMAN, shared how its human verification engine proactively processes trillions of interactions to identify bots and prevent digital advertising fraud, and how it can surface more information for customers in dashboards for their own personalized insights.
“Snowflake has allowed us to build an ecosystem where all captured data is available within 20 minutes of the time it was created—which is down from more than two and a half hours previously,” Baradia said. “The data freshness allows us to detect active threats sooner.”
The California Department of Public Health (CDPH) and California Department of Technology (CDT) also used improvements in concurrency and latency during their work on the California Digital COVID-19 Vaccine Record portal, ensuring that millions of California residents could receive their records quickly. The CDT shared the portal code on GitHub, and it was subsequently used by Colorado and other states.
Improving Concurrency and Latency: How We Did It
We achieved these improvements for interactive use cases by:
- Redesigning our core engine dealing with concurrent query processing
- Optimizing frequently used data access patterns, including point lookups and aggregations
Point lookups are queries where a user is searching for a small number of records by a search key and other predicates. For example, a user might search for web page clicks using a session ID and a time range.
On the other hand, aggregations are operations such as counting, summing up, or calculating a maximum, and can come with or without a grouping. Examples of aggregations include counting the number of web page clicks for a specific session ID and counting the number of web page clicks for the session ID, but grouping them first by the page URL.
To help customers build new interactive workloads and improve existing ones, we analyzed every part of our query processing infrastructure to optimize for latency and concurrency.
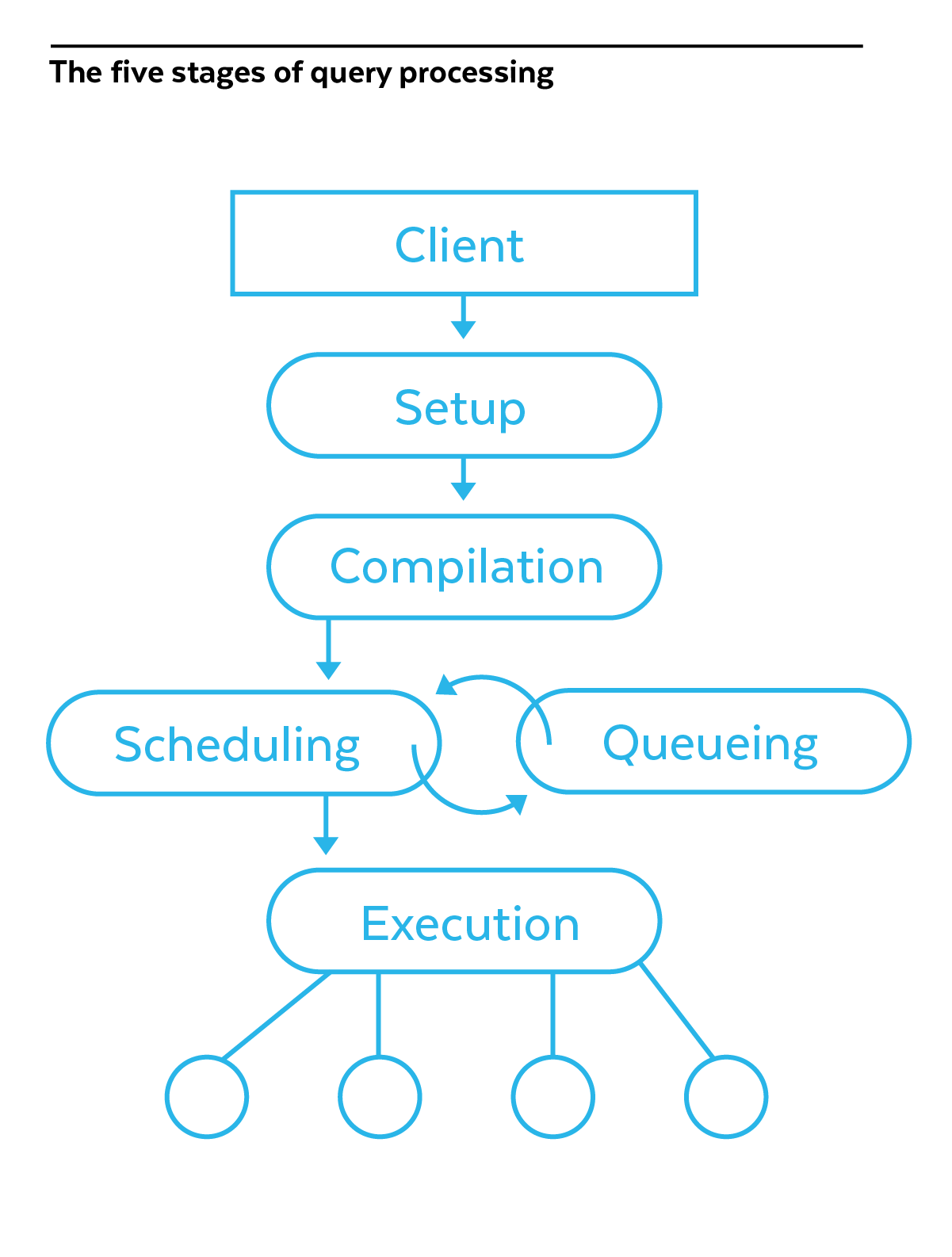
Queries in Snowflake go through the following phases (see Figure 1):
- Setup: After a client application sends the query to Snowflake, we allocate initial resources.
- Compilation: The query statement gets parsed and we create a plan to execute the query.
- Scheduling: Snowflake checks if there are enough resources in the virtual warehouse to execute the query. If there are, the query transitions to the Execution phase. Otherwise, the query gets queued.
- Execution: In this phase we access data, join tables, filter data by predicates, and perform aggregations. The results get returned to the requesting client application.
- Queueing: A query might spend some time in the queueing phase if there are no free resources to execute it, and move back to Scheduling for another attempt at execution.
Figure 1: The five stages of query processing
Our biggest changes were in the scheduling phase, where we sped up metadata access and fine-tuned our algorithms for allocating execution resources. This significantly improved our concurrency, especially in multi-cluster warehouses. We also reduced the startup time of queries—something that is particularly relevant for short-running queries that take less than 100 milliseconds. Compilation time was reduced by up to 15% for most queries and we optimized our execution of IF-THEN-ELSE statements and string comparison operations, reducing their execution times by up to 50%. While these improvements benefit all types of queries and all kinds of workloads running in Snowflake, they are exceptionally effective for interactive use cases dominated by short-running queries and high levels of concurrency.
Our latency and concurrency improvements also amplify the benefits of Snowflake’s Search Optimization Service. The Search Optimization Service significantly reduces the latency of point lookup queries, and when combined with our concurrency improvements, can deliver fast lookups even when there is a high level of concurrency in the warehouse.
By the Numbers: A Closer Look at Performance
To verify the improvements in interactive use cases, we assessed Snowflake’s performance before and after the changes. We used the 10 TB TPC-DS data set with tables containing store sales, returns, and inventory, and we defined three types of queries (global aggregation, grouping and aggregation, and point lookup) to evaluate our performance. These queries were run with varying date, store, and other parameters to prevent the reuse of Snowflake’s result set caches, making it a more demanding test. The largest table in the 10 TB data set was Store_Sales containing 29 billion records.
As is customary in real-life interactive use cases, our queries accessed data in a time range narrower than the full five years of store sales. This allowed Snowflake to cache some of the previously accessed data in its local data cache, speeding up parts of the query lifecycle. Overall, about 320 million records of Store_Sales were cached locally.
Query 1: Global Count (Aggregation)
What it does: Sums up sales for all stores for a single day.
select sum(ss_quantity), sum(ss_list_price), sum(ss_sales_price), sum(ss_net_profit)
from store_sales, date_dim
where ss_sold_date_sk = d_date_sk
and d_date = $randomDate
Query 2: Grouping and Counting (Aggregation)
What it does: Breaks down sales by store for 100 stores over 30 days.
select ss_store_sk, sum(ss_quantity), sum(ss_list_price), sum(ss_sales_price), sum(ss_net_profit)
from store_sales, date_dim
where ss_sold_date_sk = d_date_sk
and d_date between $randomDate and ($randomDate + 30)
and ss_store_sk between $randomStore and ($randomStore +100)
group by ss_store_sk
Query 3: Point Lookup
What it does: Finds a specific sale record for a particular product and ticket number.
select ss_ticket_number, ss_store_sk, ss_quantity, ss_list_price, ss_sales_price, ss_net_profit
from store_sales
where ss_ticket_number = $randomTicketNumber
and ss_item_sk = $item_sk
We ran the test suite before turning on the performance improvements and enabling the Search Optimization Service, then redid the test runs with them enabled. In both cases, we observed latency and throughput at an ever-increasing number of client connections, starting with eight clients and going up to 80. In an actual interactive dashboard, this would be equivalent to many hundreds of simultaneous dashboard users.
Quantifying the Latency Improvements
The extent of improvement was impressive. Before, query latency of all three queries tended to increase as we added more load to the virtual warehouse. After our improvements, the same virtual warehouse—without additional resources—was able to maintain the same speed even at the highest concurrency levels.
The latency of the “Global Count” Query 1 decreased from 1.1s to 0.25s (a 4x reduction) at the highest concurrency level (80 threads), shown in Figure 2. The latency of “Group and Count” Aggregation Query 2 decreased from 1.25s to ~0.5s, a 2.7x reduction (see Figure 3).
Figure 2: Latency of Aggregation Query 1 at different concurrency levels, May 2021 vs. Nov. 2021

Figure 3: Latency of Aggregation Query 2 at different concurrency levels, May 2021 vs. Nov. 2021

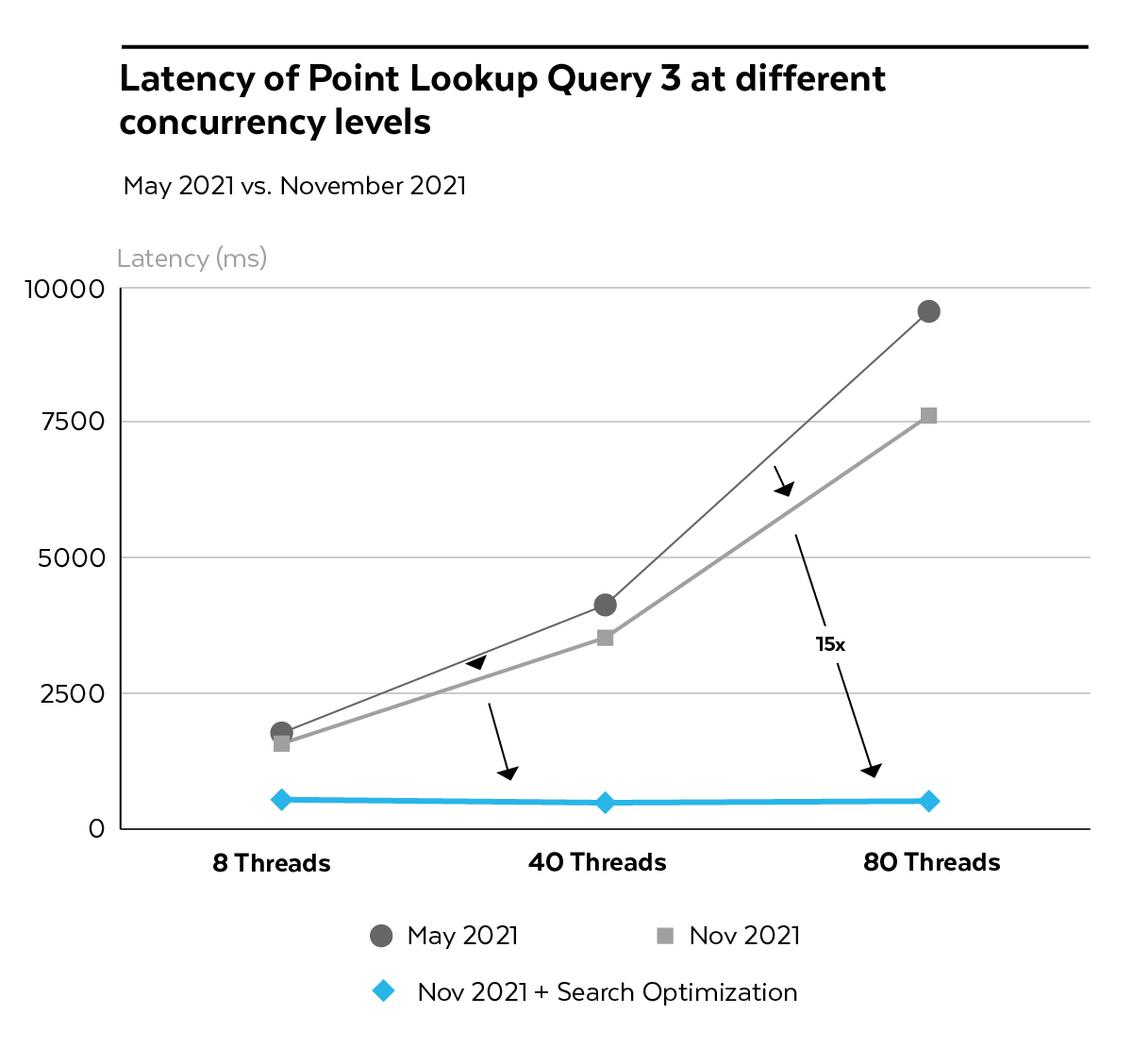
Without our recent optimizations, the Point Lookup Query 3 could take more than 5s at high levels of concurrency. With concurrency optimizations turned on, query duration was up to 20% lower across all concurrency levels. Once we enabled the Search Optimization Service on the Store_Sales table, we achieved an almost constant latency of 0.5s independent of the number of clients (see Figure 4).
Figure 4: Latency of Point Lookup Query 3 at different concurrency levels, with and without Concurrency and Search Optimizations, May 2021 vs. Nov. 2021
Quantifying the Throughput Improvements
Throughput was also positively impacted when we applied both the improved engine and the Search Optimization Service. Without these enhancements, the warehouse throughput would increase only moderately even as a larger number of clients submitted queries (see Figure 5).
After the updates, the throughput of Aggregation Queries 1 and 2 increased almost linearly as more clients issued queries. Query 1 had a throughput of 317,000 queries per hour (QPH), which represented a 3.7x increase (see Figure 5). Query 2 had a throughput of 176,000 QPH, or 2.1x more than before (see Figure 6).
Figure 5: Throughput of Aggregation Query 1 at different concurrency levels, May 2021 vs. Nov. 2021

Figure 6: Throughput of Aggregation Query 2 at different concurrency levels, May 2021 vs. Nov. 2021

Similarly to latency, the throughput of our Point Lookup Query 3 benefited by up to 30% from our concurrency improvements alone, peaking at 40,000 QPH. The real breakthrough came from enabling the Search Optimization Service, with throughput growing to 180,000 QPH, a 6.3x increase compared to May 2021 (see Figure 7).
Figure 7: Throughput of Point Lookup Query 3 at different concurrency levels, with and without concurrency and Search Optimization Service, May 2021 vs. Nov. 2021

Join the Public Preview: Get Started Today
Since our initial announcement in June 2021, almost 100 customers have tried the Private Preview of the latency and concurrency improvements. Today, we are launching the first set of these improvements broadly in Public Preview.
To benefit from these core engine improvements, you’ll need to operate in one of four deployments where the improvements are enabled by default, including:
- AWS ap-southeast-1 (Singapore)
- AWS eu-west-1 (Ireland)
- AWS eu-central-1 (Frankfurt)
- Azure West Europe
Virtual warehouses in other deployments will be automatically upgraded to benefit from these improvements in the first half of 2022. If you want to enable a virtual warehouse in a different deployment, ask your Snowflake account team for support.
If you would like to compare the performance of your warehouse before and after enabling these improvements, review our guide for querying the Account Usage views.
Stay tuned for more updates—we are continuously working to improve Snowflake performance and pass those benefits to our customers!