
Snowflake recently launched dynamic data masking, an incredibly useful feature for companies and data-centric organizations that have strict security data governance requirements.
This article demonstrates how we implemented data masking at Snowflake by introducing a data masking policy on a VARIANT data type field that holds data in JSON format. We implemented the policy on top of tables and views. Snowflake also supports data masking on external tables and various additional standard file formats such as CSV, Avro,ORC, and Parquet.
Data Masking
Data masking is the process of masking sensitive information without changing the actual underlying data. It is used by companies as one of the key means to ensure that sensitive data is protected properly to meet strict enterprise business and legal rules.
In general, there are several known ways to mask data. Here at Snowflake, we use Snowflake’s Dynamic Data Masking feature to address many of our own security and compliance needs.
Dynamic data masking happens at query runtime, eliminating the need to have a second data source in order to store the masked data. The Dynamic Data Masking feature is a column-level security feature that leverages first-class policy objects to selectively mask data. Snowflake provides a flexible and extensible policy framework that allows customers to define their own authorization logic as declarative policies. Policy owners or data stewards can manage and reuse these policies in a convenient and scalable way.
Dynamic data masking can also be used to hash values on the fly or by using DECRYPT on previously encrypted data with either ENCRYPT or ENCRYPT_RAW, with a passphrase on the encrypted data.
In a previous blog post, we described how we applied masking on structured data. In this post, we show how you can easily apply a masking policy on semi-structured data.
The Semi-Structured Data Challenge
In recent years we have seen increased use of semi-structured data, and the JSON format has become one of the popular file formats. Snowflake provides native support for semi-structured data, and customers can query raw data similarly to querying structured data with substantially similar performance.
The next sections demonstrate the steps we took to build our strategy for masking semi-structured data using Snowflake’s unique approach.
Design Your Approach for Managing Policies
Before creating a masking policy, let’s define the schema that will hold all the objects that are associated with your policies (functions and masking policies). One approach is to create a new database for masking policies and store all policies under one schema. Another option is to create a new schema under each database that you apply the policy to, and store all policies in that schema. In both approaches, make sure to create a policy_admin role that owns the policies. This will add additional control for who can manage and view the policies.
Let’s use the second option of a policy schema under each database:
Create schema your_database_name.policies;Produce the Test Data
Now, let’s produce some test data:
create table users (id number,value variant);
insert into users (id,value)
select 1,parse_json('{"userinfo:main":{"createdtime":1585120336316,"userid":98874442439854,"firstname":"John","lastname":"Smith","email":"[email protected]","phone":"999-999-9999","version":null}}');In the example above, we would like to mask the values in „firstname„, „lastname„, „email„, and „phone„.
Our first step will be to define all the JSON properties that we would like to mask and how the output of masked value will look.
We will use the following function to define the masking columns and masking output:
create or replace function sp_json_masking(v variant)
returns variant
language javascript
AS
$$
V["userinfo:main"]["firstname"] = "**masked**";
V["userinfo:main"]["lastname"] = "**masked**";
V["userinfo:main"]["email"] = "**masked**";
V["userinfo:main"]["phone"] = "**masked**";
return V;
$$;Create the Policy
Now, let’s create the policy that calls the function:
Create or replace masking policy data_mask_variant as (val variant) returns variant ->
case when current_role() in ('SECURITY') then val
else sp_json_masking(val)
End;The policy is using Snowflake’s current_role() function, which simply returns the name of the role in use for the current session. In the example above, we declared in our policy that only the SECURITY role can view PII data. All other roles will see masked data while querying the field in that table.
Apply the Policy
As a final step, let’s apply the policy on the VARIANT column:
Alter table users modify column value set masking policy data_mask_variant; We are done with the initial setup.
Evaluate the Results
Next, let’s evaluate the results:
Use role analyst;
Select value from users;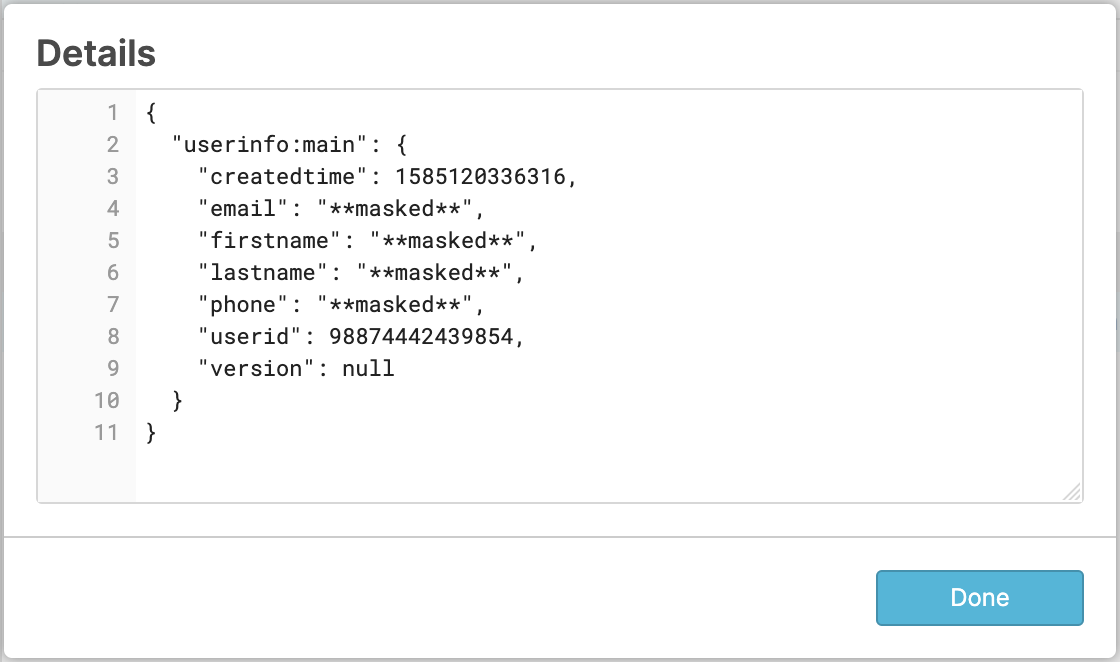
Since the analyst role is not authorized to see unmasked data based on the policy created above, the value output shows firstname, lastname, phone, and email as **masked**.
Or, you can query the subcolumn from the VARIANT field using an unauthorized role to verify that the data is masked:
Select value:"userinfo:main".email as email from users;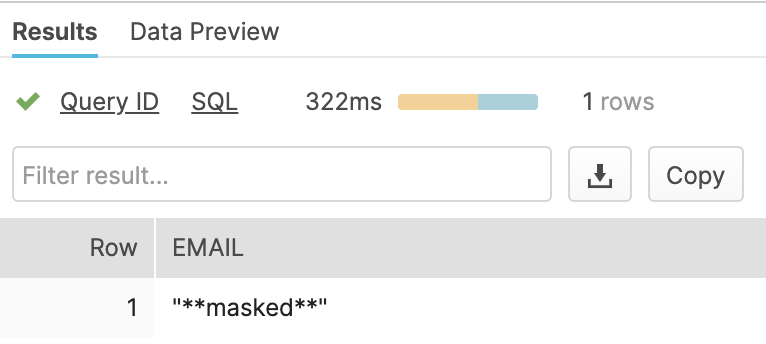
Let’s switch to the role that is authorized to see PII data:
Use role security;
Select value from users; 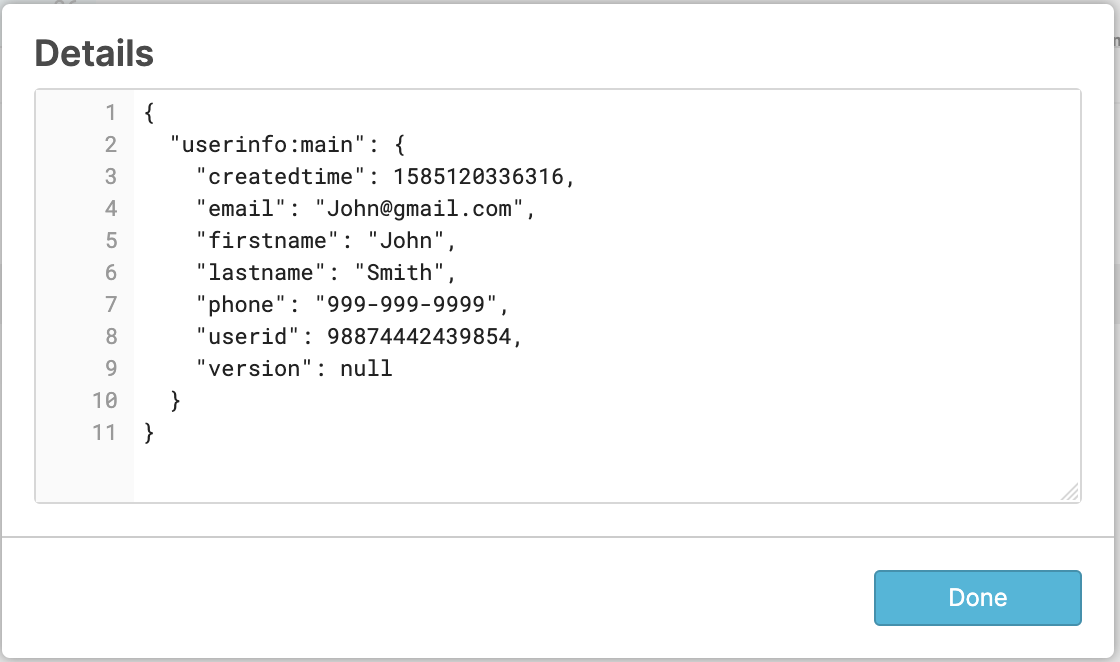
Using the authorized SECURITY role returns unmasked data.
Using the Masking Policies Dashboard
As a best practice, we recommend gathering metadata and metrics about your policies and masked objects. This approach will provide your masking admin with an easy way to find all tables with masking policies, and it will provide a centralized view of the strategy for masking.
Figure 1 shows a dashboard example we created using Snowsight that provides information about the policies and columns we masked. These are the questions the dashboard answers.
- How many masking policies were created?
- How many tables are set with masking policies?
- How many views are set with masking policies?
- How many columns are set with masking policies?
- How many times is each policy implemented on a column or view?
- Which tables or views have a masking policy?
All that information can be retrieved by using the policy.references function, as shown below:
select *
from table(information_schema.policy_references('your masking policy')) 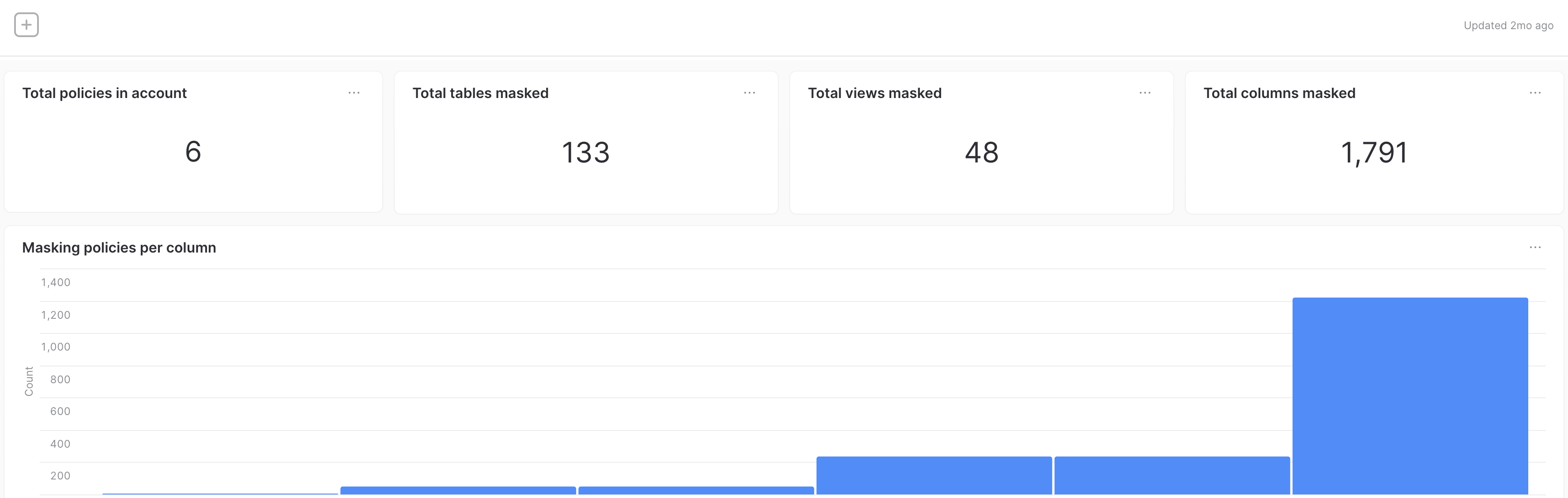
Conclusion
Snowflake provides a simple and comprehensive way to mask your data for structured and semi-structured data. It is easy to apply a masking policy if you know the areas that might contain sensitive information. Using the Snowflake approach for masking data, you can simplify data governance solutions by avoiding structure changes and without changing stored data. Snowflake provides several masking options for tables, views, external tables, and different data formats. One single policy can apply to many columns on different objects. Using Snowflake’s Dynamic Data Masking feature will free up your engineering resources to focus on your business-critical operations.