
FoundationDB is now open source. After years of in-house development, this distributed, scalable and transactional key-value store is available to all. But what you may not know is that Snowflake has been using and advancing FoundationDB since 2014, when we first adopted it as our metadata store. What’s the outcome and why should you care?
FoundationDB has proven to be extremely reliable. It is a key part of our architecture and has allowed us to build some truly amazing and differentiating features. As Snowflake has grown from a handful of customers in 2015 to more than 1000 recently, FoundationDB has continued to advance and scale with us.
Collectively, our metadata store is miniscule in size when compared to the warehoused data of our customers. The read and write patterns of our metadata are more akin to online transaction processing (OLTP) than usage patterns of an analytic data warehouse or online analytical processing system (OLAP) that is Snowflake. For these purposes our metadata store requires:
- Very high frequency of tiny reads and writes at sub-millisecond latency
- Support for metadata storage that significantly varies in access patterns, volume, and size
- Good performance for reading small data ranges
Running Snowflake as a data warehouse-as-a-service requires high availability even during software upgrades. As a result, multiple versions of the service can be deployed at the same time. And services accessing metadata must be able to handle multiple version of metadata objects.
While selecting a metadata store, we prefer key-value stores for the simplicity and flexibility they bring to schema evolution. Also, our cloud services expect the underlying store to be ACID compliant. FoundationDB fits these requirements perfectly. It supports triple replication of data for availability and has a change-in-value notification feature called “watch”.
Snowflake’s cloud services layer is composed of a collection of stateless services that manage virtual warehouses, query optimization, transactions and others, as shown in Fig. 1. To perform their tasks, these services rely on rich metadata stored in FoundationDB. For high availability, we not only triple replicate the metadata but also store it across multiple cloud availability zones. Sensitive metadata is encrypted, using our key management infrastucture.
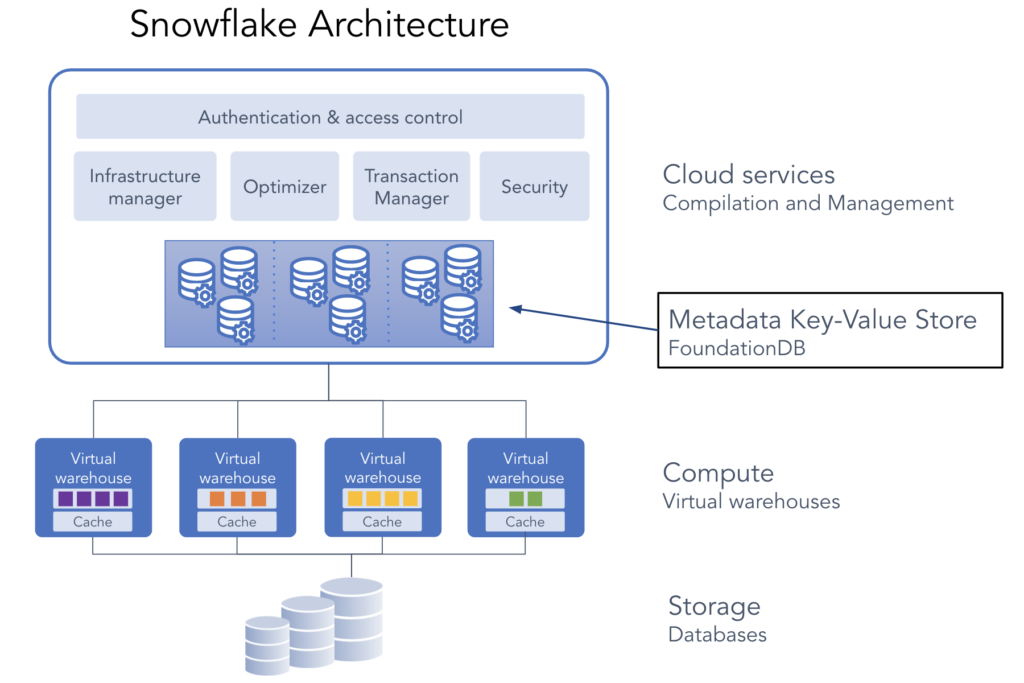
To make it easy to add new metadata objects, we built an object-mapping layer on top of key-values. Schema definition, evolution and metadata versioning are done by this layer as well. User-visible objects, such as catalog definitions, users, sessions, access control, copy history and others all have metadata backing them. Every statement executed has a metadata entry, along with statistics of its execution. Transaction state and lock queues are also persisted in FoundationDB. In fact, lock queues are implemented using the watch feature mentioned earlier. A data manipulation statement is enqueued on a resource’s lock queue, and a FoundationDB watch notifies the statement when the statement reached the front of the resource’s queue. There is also user-invisible metadata such as data distribution information, servers and encryption keys.
When we built Snowflake, we built not just a traditional data warehouse, but also a cloud service. Features such as worksheets and billing, which are traditionally decoupled from the data warehouse, are central to Snowflake’s cloud offering. Every aspect of Snowflake leverages metadata. As a result, we designed an amazing set of new features as purely metadata operations.
For instance, metadata enables the zero-copy clone feature, which allows cloning tables, schemas and databases without having to replicate the data. Metadata for each table keeps track of the set of micro-partitions that belong to the table at each version. The clone operation simply copies the record of micro-partitions, at a specific version, to the freshly cloned table. Also, metadata enables time travel by providing access to prior versions of micro-partitions.
A powerful feature such as Snowflake Data Sharing is also achieved by a metadata-only operation. The data share object is created containing references to the source and destination catalog objects and access control objects. Data sharing does not copy data from the provider, it exposes the data to the consumer via the data share object.
When compiling a query we prune out micro-partitions to scan by analyzing data distribution metadata, thus improving performance. In some cases, the optimizer can answer a query without reading any data from the table but by simply evaluating the data distribution metadata.
In the future, you can expect even more cool features enabled by Snowflake’s metadata and powered by FoundationDB. Snowflake’s engineering team looks forward to contributing to FoundationdDB open source and collaborating with its community.