
Snowflake continues to set the standard for data in the cloud by removing the need to perform maintenance tasks on your data platform and giving you the freedom to choose your data model methodology for the cloud.
We hope you enjoyed our 10-part “Data Vault Techniques on Snowflake” series, and have learned some valuable techniques to try out yourself. We just couldn’t resist writing one more bonus post to share with you, and so we’re adding post number 11 before signing off::
1. Immutable Store, Virtual End Dates
2. Snowsight Dashboards for Data Vault
3. Point-in-Time Constructs and Join Trees
4. Querying Really Big Satellite Tables
6. Conditional Multi-Table INSERT, and Where to Use It
7. Row Access Policies + Multi-Tenancy
9. Virtual Warehouses and Charge Back
11. [BONUS] Handling Semi-Structured Data
Common data vaults have been built on structured tabular data. With Snowflake, you can load semi-structured data (such as JSON and XML) and query it in place. How should we design our Data Vault to cater to semi-structured content?
A reminder of the Data Vault table types:
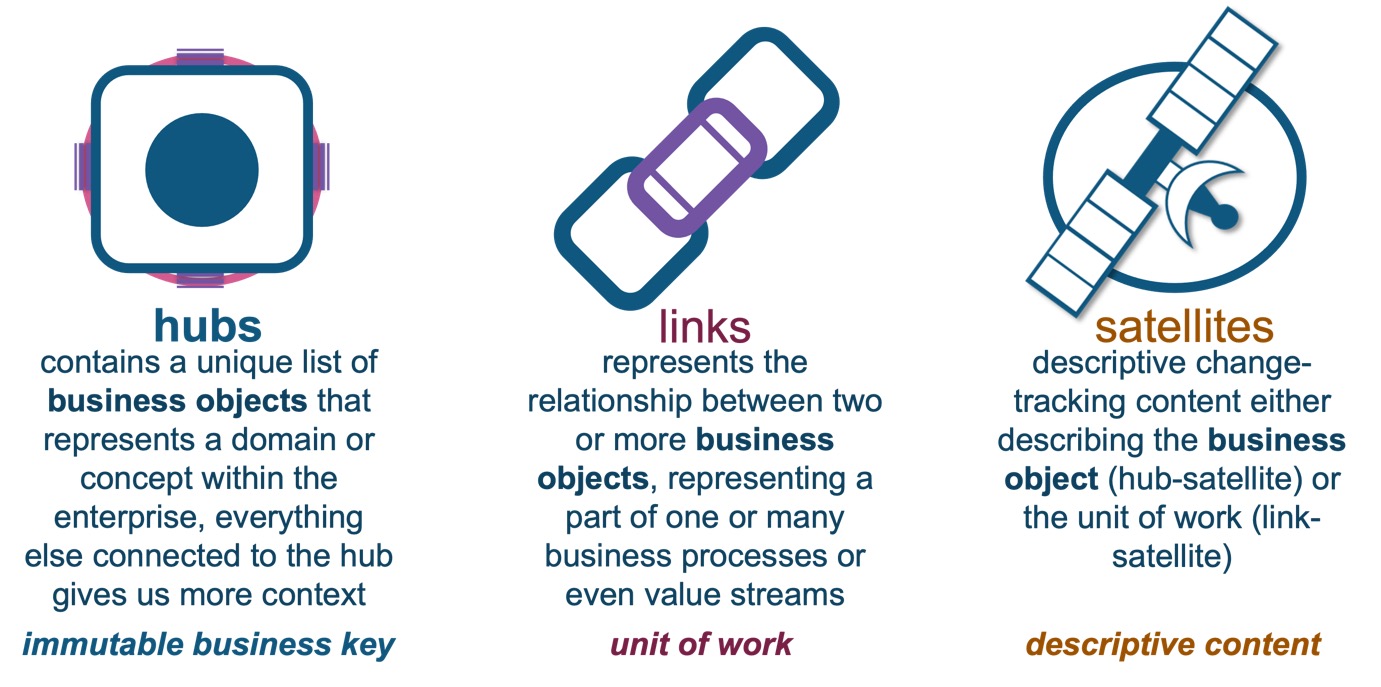
Pay now or pay later—semi-structured data negates the need to preemptively design database structures based on type to store your data. Data producers are free to push data as predefined key-pairs, and it’s the job of data consumers to parse the semi-structured data into a meaningful format, that is, schema-on-read. Other benefits of semi-structured data include:
- No need to define the schema upfront. It should be noted, however, that most BI tools can only process content in a structured format. Therefore, a degree of parsing (data typing) is required before the data is usable by most frontend tools.
- Semi-structured data appears as key-value pairs within documents (or objects), whereas structured data is tabular-defined as rows and strongly typed columns. Not only can you include the typical primitive data types as we see in structured data, but you can natively store complex data types such as lists, dictionaries, and arrays.
- Evolving the schema is easier, more flexible, and scalable. There is no need to migrate the structure from one tabular form to another and define common relational table constructs such as indexes or primary keys and foreign keys.
- Relationships between keys can be embedded within a single semi-structured document, persisting into hub tables where they do exist and omitting them when they don’t.
In the context of Snowflake, semi-structured data is supported in its extended SQL, with the ability to query JSON and XML without pre-parsing the data, all within Snowflake’s VARIANT column data type.
Semi-structured data can be provided as a part of a batch-oriented workload or as a real-time streaming workload. Traditional batch-oriented workloads are file-based and have been the mainstay of data extraction from these source systems for decades as a cheap way (compared to streaming) to push or pull content into an analytical data platform.
Streaming use cases, however, need real-time responses and analysis, and are often predicated on processing near real-time data. This is where it is critical to act on the business event as close as possible to the processing of that event. (For more on this theory, read this O’Reilly post.)
In the context of this post, we will describe considerations that should be made for semi-structured data within the Data Vault context, regardless of whether it’s streaming, micro-batch, or batch-oriented data. At the end of the day, the data will come to rest somewhere and if it is not needed right away, it can certainly be used for future analysis.
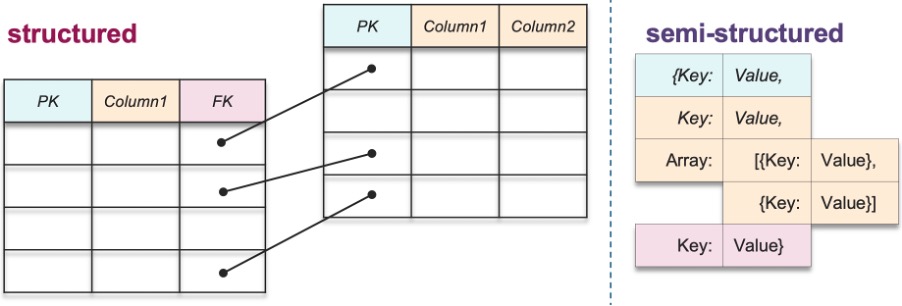
Where do we see semi-structured data?
As you may have heard, the elements of big data include volume, velocity, variety, veracity, and value. With Snowflake’s native support for semi-structured data, you can bring your big data use case from a variety of sources such as:
- Internet of Things (IoT), devices that are connected to the internet (excluding typical devices such as smartphones and computers); for example, smart healthcare devices, vehicle-to-everything (V2X), smart buildings, smart homes and appliances, transportation, etc.
- Web data including clickstream, social media, email, and ride-sharing applications
- Computer logging and monitoring, SIEM (Security Information and Event Management)
- Stock exchange, inventory management, fraud detection
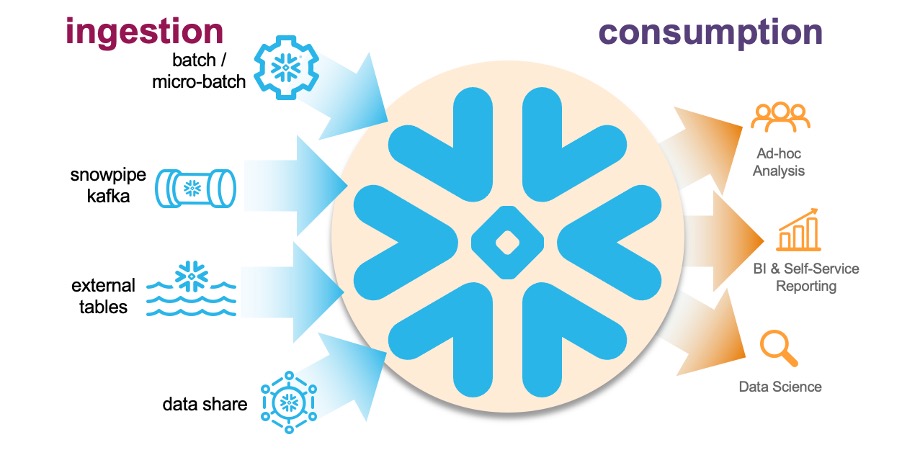
With Snowflake the data ingestion does not need to be in Snowflake’s native tables (although it’s strongly suggested by our team). Semi-structured data can also be ingested through external tables such as Parquet, AVRO, ORC, JSON, and XML. Should you choose to ingest (COPY) into Snowflake’s native tables, look to options such as:
- Use a partner ELT tool to configure and orchestrate data ingestion.
- Use a cloud service provider’s messaging service to trigger Snowpipe to ingest new data.
- Combine Kafka (open source and confluent) or another message/streaming-based tool (for example, Amazon Kinesis) to notify Snowpipe via Snowflake’s Snowpipe REST endpoints.
Does Data Vault support semi-structured data?
Yes, and here are guidelines and considerations when designing semi-structured data used for Data Vault on Snowflake.
Keep semi-structured data within the structured satellite table
To support scalability of Data Vault on Snowflake without the threat of refactoring, you introduce a new Data Vault metadata column, dv_object. This new column will store the original semi-structured data as data type VARIANT. On Snowflake this could be populated with either JSON, XML, array, or object semi-structured content that can be queried in place.
What is the parent entity of the satellite?
A satellite is either the child table of a hub or a link table. Profile the semi-structured content to identify the business keys the descriptive content is based on. If the content is transactional, we are likely going to deploy a link-satellite table. Keep in mind that link tables are designed to serve many-to-many/associative (M:M) cardinality, but can also house explicit or mandatory (1:1 / 1:M) and optional (0..1:1..M) cardinalities within that same link table.
Pre-parse essential content into raw vault satellites
Semi-structured content is slower to query, and if the content is nested or hierarchical, you may need to flatten the content before getting to the attributes you need. As part of the staging step, and because of your data profiling for the essential (for example, critical data elements) attributes, you need to persist those key-pairs as strongly typed structured columns within the same satellite table. These could also be columns that can improve pruning performance on Snowflake.
If the business event to analytical value latency is critical, avoid flattening nested content in staging, and instead allow for the dashboard to pick and flatten the content at query time.
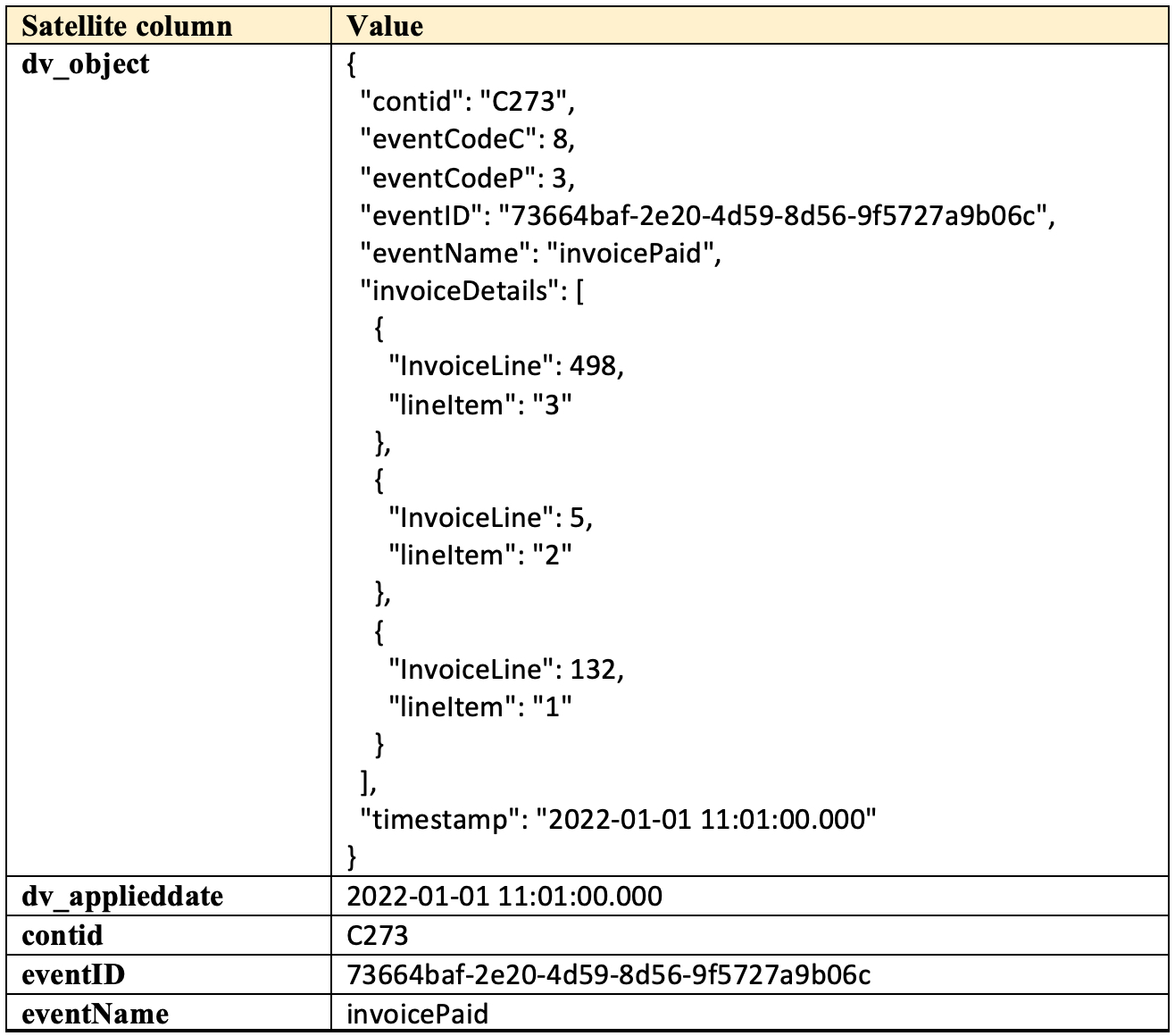
From the JSON in dv_object we have extracted
- The timestamp (business event timestamp) to be used as the applied date column
- The ‘contid’ is the business key, but as you will see below it is an untreated business key, and the treated business key is sent to the hub table
- The eventID, which is an internal id used by the source system
These simple extractions are viewed as hard rules and will make querying the satellite table faster. Notice how we did not flatten the nested content—doing this at ingestion time causes a delay in loading the satellite table.
create or replace view staged.stg_casp_clickstream as
select
value as dv_object
, coalesce(upper(to_char(trim(value:contid::varchar(50)))), '-1') as customer_id
, value:contid::varchar(50) as contid
, 'default' as dv_tenantid
, 'default' as dv_bkeycolcode_hub_customer
, sha1_binary(concat(dv_tenantid, '||', dv_bkeycolcode_hub_customer, '||', coalesce(upper(to_char(trim(customer_id))), '-1'))) as dv_hashkey_hub_customer
, current_timestamp() as dv_loaddate
, value:timestamp::timestamp as dv_applieddate
, 'lake_bucket/landed/casp_clickstream.json' as dv_recsource
, value:eventID::varchar(40) as eventID
, value:eventName::varchar(50) as eventName
from landed.casp_clickstreamDo we pursue creating hash keys or build a satellite table with natural keys only?
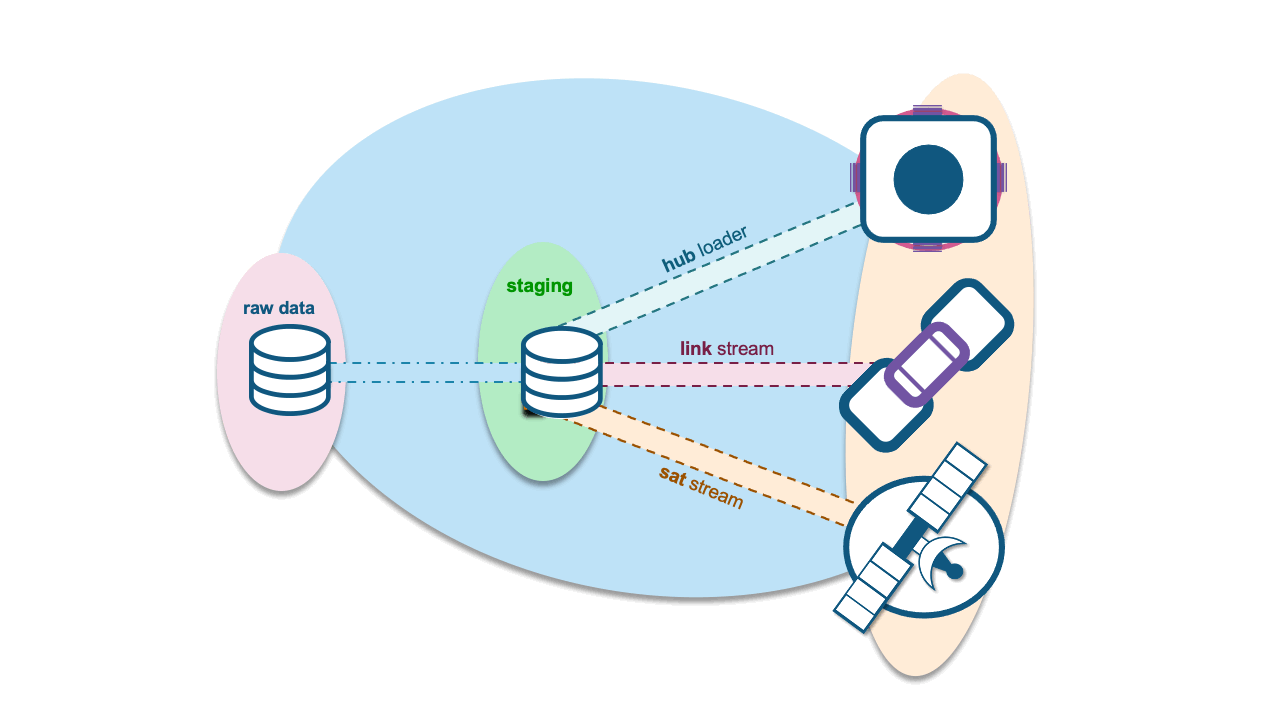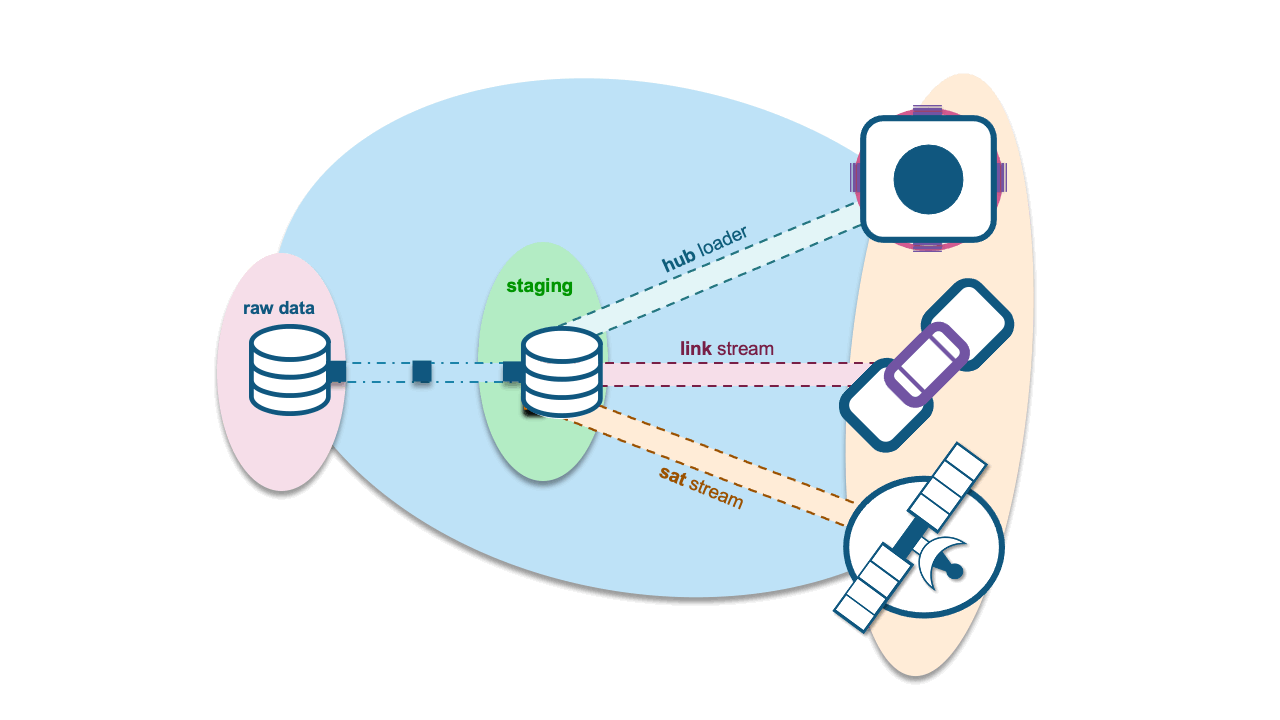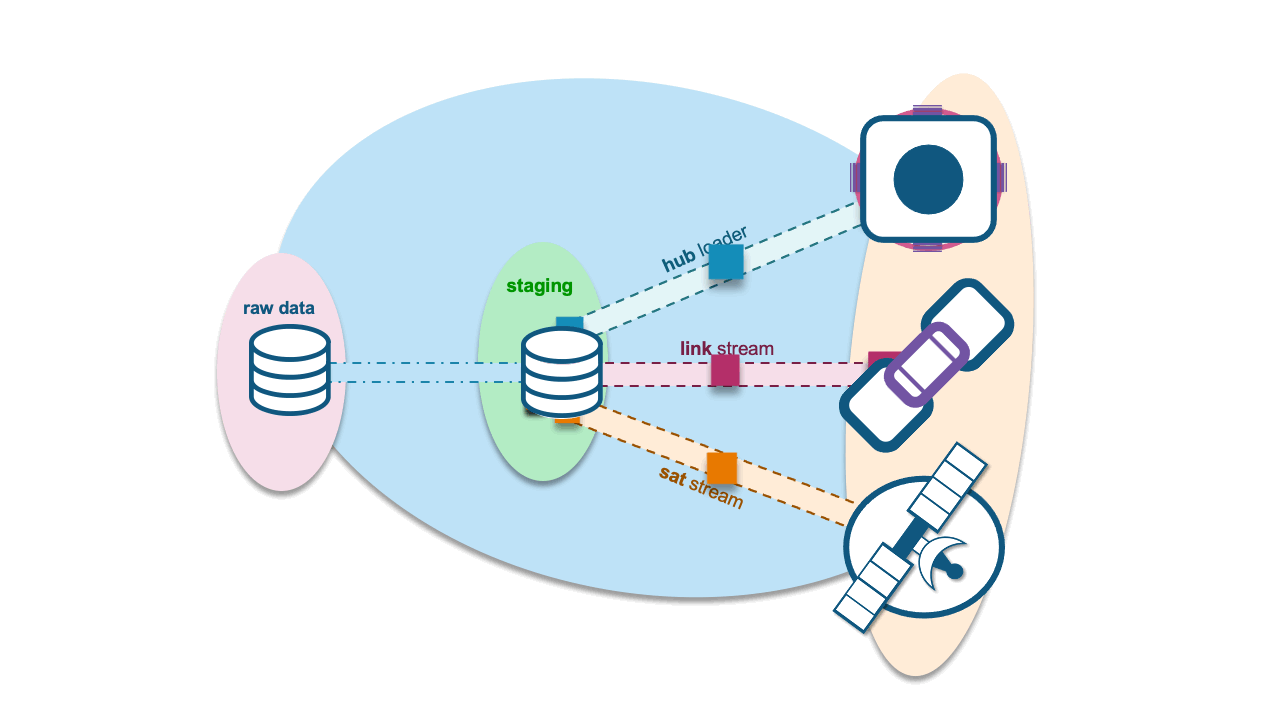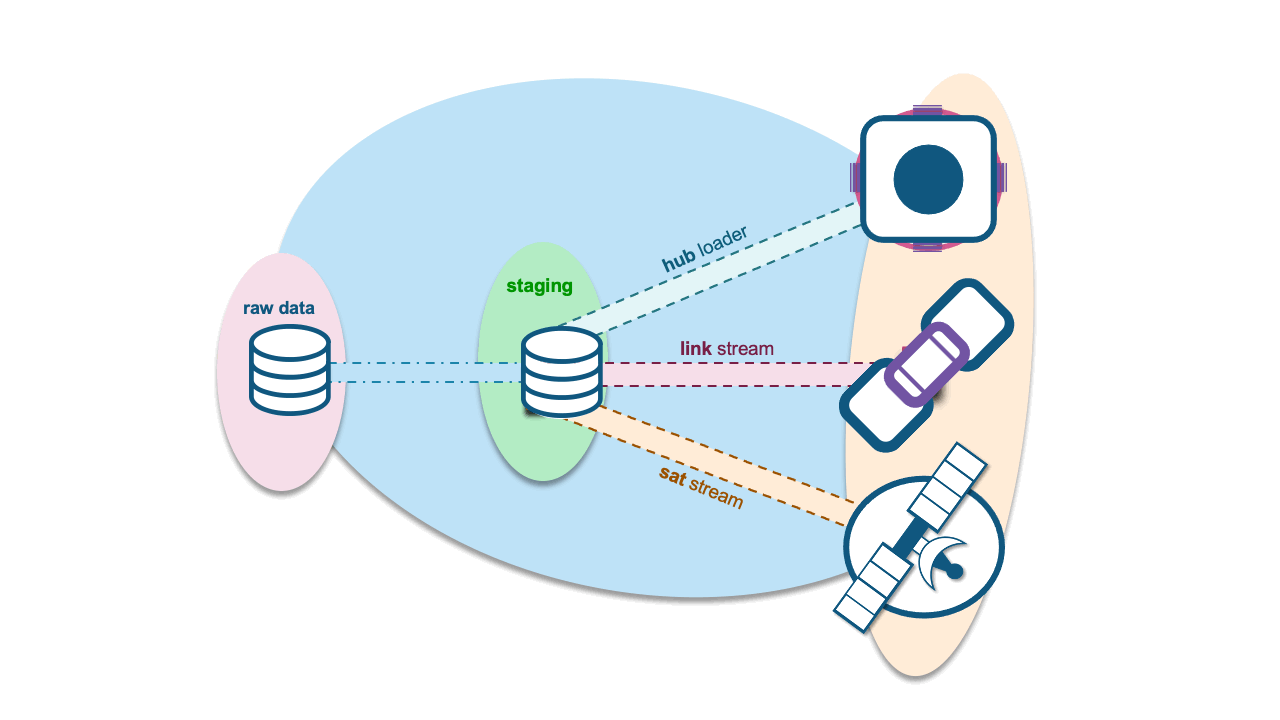
You could do either, if you choose to use natural keys without hash keys, those natural keys must persist in the satellite table to join to all of the respective hub tables. You may choose to do this because you have determined that the act of hashing business keys to produce hash-keys is costly and time-consuming. However, keep in mind this means that queries running on this satellite will essentially need to use more columns to join on.
- A Data Vault should be produced as either natural-key or hash-key based and not a mix of the two. Introducing a mixed architecture pattern essentially means that you must be selective in how you use each table in the Data Vault, which is a bad practice and introduces inconsistencies into the Data Vault experience.
- Using concepts such as business key collision codes and multi-tenant ids means that you must include these columns in every SQL join you perform on Data Vault, which again can lead to an inconsistent experience on the Data Vault.
- We can mitigate the cost of hashing by using Snowflake features such as Streams and Tasks, which we have shown in a previous post can minimize the amount of data being processed into Data Vault, therefore reducing the cost to hash.
Does the semi-structured content include personally identifiable or sensitive content?
An important step when profiling data is identifying sensitivity levels of the content. You have several options to consider here. You can:
- Isolate semi-structured content in a satellite splitting activity and obscure the content from the general business user.
- Use Snowflake’s data masking features to mask semi-structured content in place (using Snowflake’s role-based access control and dynamic data masking). Obscure the entire VARIANT column and only persist the authorized key pairs as structured columns and apply masking/tokenization as hard rules.
- Pre-parse the content before the data is even loaded to Snowflake by hashing/encryption that content in place through crypto shredding. Split the semi-structure content itself between sensitive and non-sensitive content.
Do we load the content to the Data Vault at all?
If this is auditable data about one or more business objects, that answer is yes. The subsequent question is, when do we load the Data Vault? If the Data Vault serves as a bottleneck to a business case, instead of pushing data through Data Vault to serve your real-time needs, you could offload the data into Data Vault asynchronously while it is being served to your real-time customers. The value in loading this data into Data Vault is the auditable history, business context, and the subsequent batch-oriented analysis that the data could serve.

The data is immediately available to the information mart view based on Data Vault, or it can be further processed into a business vault, as shown below:

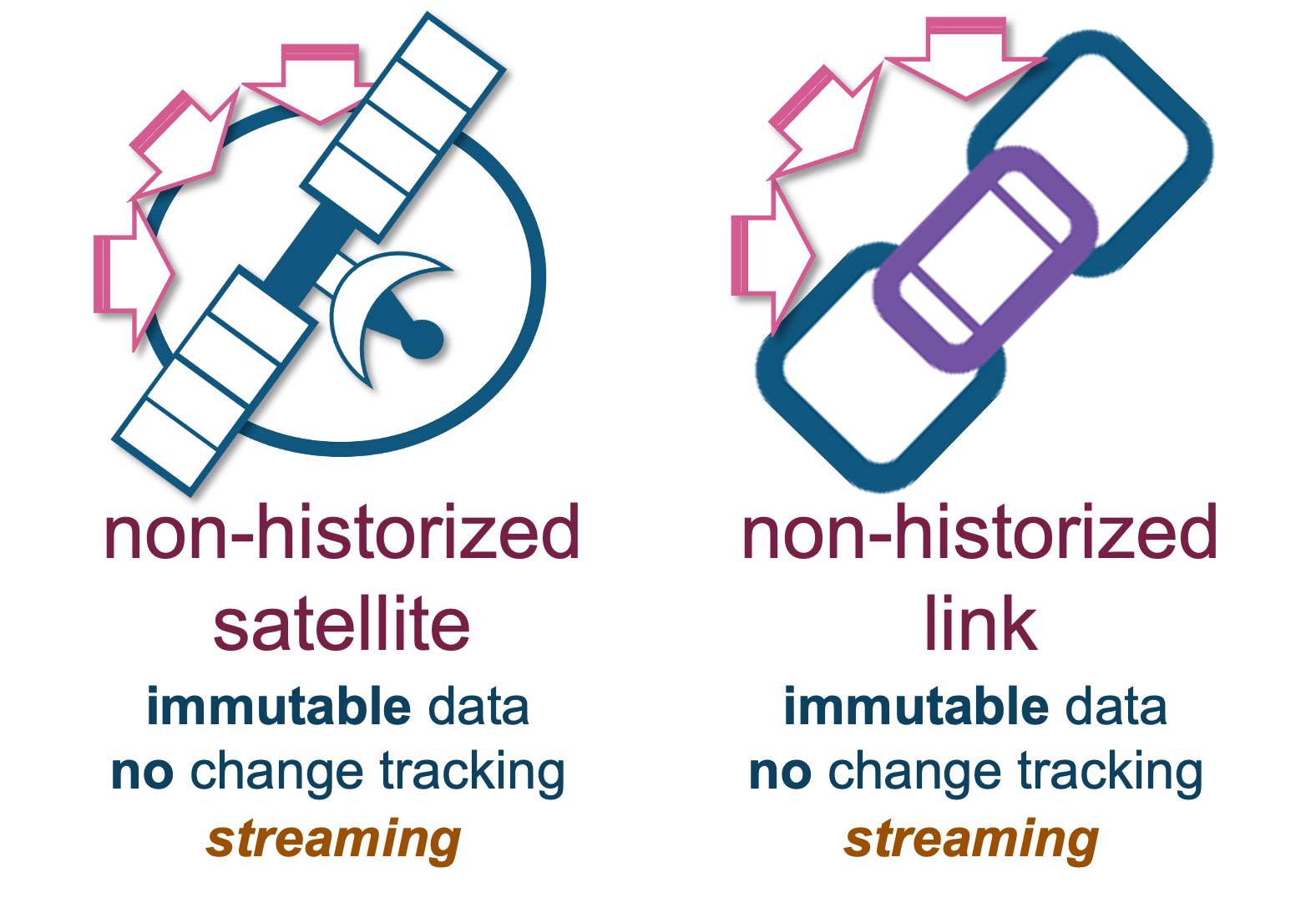
Is the data event-based (immutable)?
Streaming events are always new events. No past updates are permitted and therefore the standard satellite table loader can be avoided. The standard loader checks if new content is different to the current record per parent key in the target satellite table. Because our content is always new, such a check is no longer necessary—we simply load what has arrived. The same replay-ability is possible when using these non-historized satellite or link table (see image below) loads in combination with Snowflake data pipelines (streams and tasks) and because we INSERT without needing to check if the record is new, the target satellite table will also not need to have a record-hash (hashdiff) column. This also makes the applied timestamp in a streaming context the business event timestamp.
Is the content overloaded?
An overloaded data source is the result of combining far too many business processes into a single data file. In such a situation we look to remedy the issue by pursuing a solution that we will rank from the most preferred to least preferred option, starting with:
- Solve it at the source: Operational reality may mean that this path is not feasible, or at least not prioritised yet.
- Solve it in staging: A routine within staging or before staging must be designed and built to filter out the essential from the overloaded content but it does mean it is a point of maintenance on the analytics team to pursue. Build error traps, keep all content somewhere to remain auditable with overloaded content persisted in its own satellite table. Minimise duplication of data.
- Solve it using a business vault: This is always the least preferred option. This will result in the need to maintain and manage more tables and introduce more tables to join.
What about late arriving data?
Streaming ingestion and late-arriving data are a different beast from dealing with late-arriving batch data. This is best handled by the platform itself through streaming concepts such as windowing, watermarking, and triggers (to name a few). A link in the reference section at the end of this post provides more details on how this works, but ultimately it is not something a Data Vault is expected to manage.
How do you test semi-structured data?
Finally, if the automated test framework we described in an earlier post were to be executed after every load, it would introduce unnecessary latency between business events and analytical value. Instead, streaming content reconciliation between what was landed and what was loaded should be checked on a scheduled basis (for example, once a day). This can be further optimized by using Snowflake Streams to compare only new content in the landed area against only new content in the target Data Vault tables.
Querying semi-structured data
With the content prepped for efficient querying, the semi-structured data can evolve freely without impacting the integrity of the satellite table. Nested arrays can be queried in place, or we can look to use a business vault to flatten out the content so that you hide this querying complexity from the business end-user.

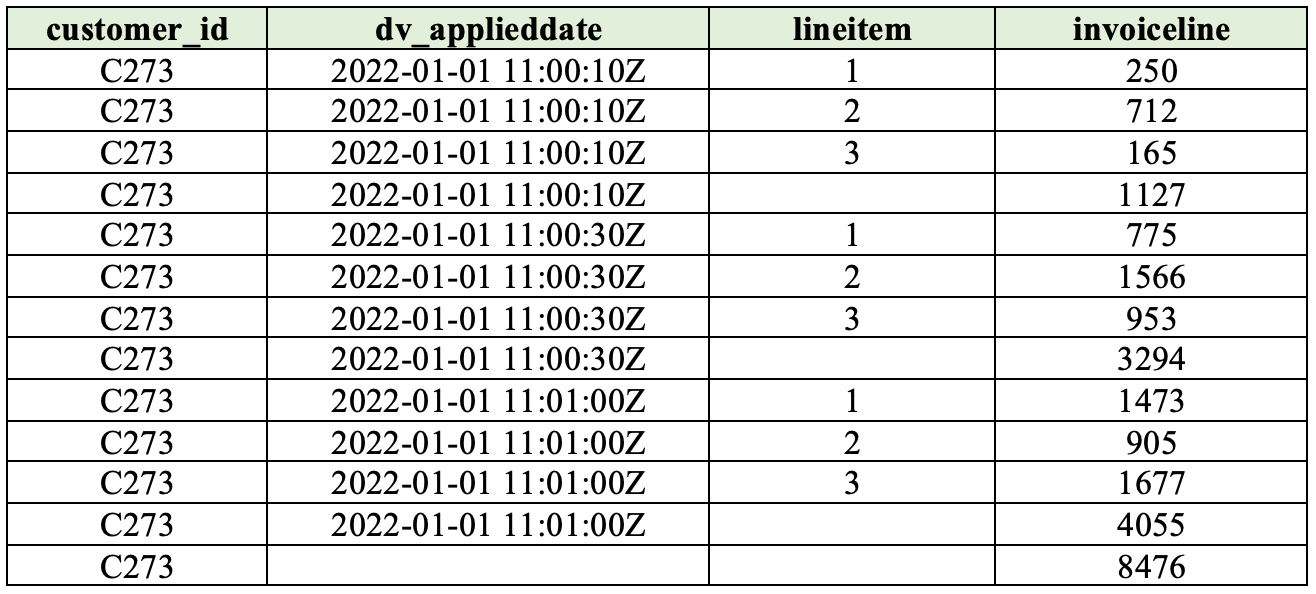
To query nested arrays in place, we can use Snowflake’s lateral flatten operation:
with flatten_content as (
select s.customer_id
, s.eventid
, s.eventname
, s.dv_applieddate
, flt.value:lineItem::int as lineItem
, flt.value:InvoiceLine::int as InvoiceLine
from datavault.sat_nh_casp_clickstream s
, lateral flatten(input => dv_object:invoiceDetails) flt
)
select customer_id
, dv_applieddate
, lineItem
, sum(InvoiceLine) as InvoiceLine
from flatten_content
group by rollup (customer_id, dv_applieddate, lineItem)
order by customer_id, dv_applieddate, lineItem;Output:
It all comes down to auditability and efficiency
In this post we have shown a pragmatic framework for loading and querying semi-structured data within Data Vault on Snowflake. Load it into Data Vault now or load it later, but regardless it should live in the Data Vault somewhere. This ensures the source of the facts is accessible from a single data platform and relatable to the overall enterprise data model.


