
This is the second post in a series about data modeling and data governance in the cloud from Snowflake’s partners at erwin. See the first post here.
As you move data from legacy systems to a cloud data platform, you need to ensure the quality and overall governance of that data.
Until recently, data governance was primarily an IT role that involved cataloging data elements to support search and discovery. But in this digital age, data and its governance are the responsibility of the entire organization. Data keepers (IT) and data users (the rest of the organization) must be able to discover, understand, and use data to drive opportunities while limiting risks.
Think of it this way: The right data of the right quality, regardless of storage location or format, must be available to only the right people for the right purpose.
Making this imperative a reality requires an ongoing strategic effort. It requires enterprise collaboration and enabling technology that provides a holistic view of the data landscape, including where data lives, who and what systems use it, and how to access and manage it. Data governance is necessary but also complicated, so most enterprises have a difficult time operationalizing it.
Over time, the desire to modernize technology leads organizations to acquire many different systems with various data entry points and transformation rules as data moves into and across the organization. These tools range from enterprise service bus (ESB) products, data integration tools, ETL tools, procedural code, APIs, FTP processes, and even BI reports that further aggregate and transform data. All these diverse metadata sources form a complicated web and make it difficult to create a simple visual flow of data lineage and impact analysis.
Organizations in different sectors have contended with regulations such as HIPAA, SOX, and PCI-DSS for several years. But passage of the EU’s GDPR and its stringent penalties for noncompliance thrust data governance into the spotlight, forcing most organizations to reevaluate their approaches and tooling. Although enterprises have made improvements, they still rely on mostly manual processes for data cataloging, data lineage, and data mapping, and they grapple with the challenges of deploying comprehensive and sustainable data governance.
The problem is few organizations know what data they have or where it is, and they struggle to integrate known data that is in various formats and numerous systems, especially if they don’t have a way to automate those integration processes. But when IT-driven data management and business-oriented data governance staff work together in terms of personnel, processes, and technology, they can make decisions and determine impacts based on a full inventory of reliable information.
Data Modeling Is Foundational to Data Governance
Although data modeling has always been the best way to understand complex data sources and automate design standards, modeling today enables true collaboration within an organization because it delivers a visual source of truth for everyone, including data management and business professionals, to follow so they can conform to governance requirements.
Data modeling is also the best way to visualize metadata, and metadata management is the key to managing and governing your data so you can draw intelligence from it. Visualizing goes beyond harvesting and cataloging metadata by enabling all data stakeholders to break down complex data organizations and explicitly understand data relationships.
The latest release of erwin Data Modeler (erwin DM) has a new user interface and a lot of new functionality, including native support for Snowflake. It also now includes erwin DM Scheduler that enables you to define and schedule reverse engineering (RE) jobs in advance and run them without interrupting your erwin DM usage.
In addition, erwin now offers erwin DM Connect for DI, an integration between erwin DM and the erwin Data Intelligence Suite (erwin DI). This offering enables you to sync data between erwin DM and erwin DI using the erwin DM Mart Administrator as an interface, thus maintaining a single metadata and glossary source.
Data Governance for Snowflake’s Cloud Data Platform
The erwin DI Suite interacts with third-party tools through erwin Data Connectors, which include erwin Standard Data Connectors and erwin Smart Data Connectors.
erwin Standard Data Connectors
erwin Standard Data Connectors connect to any JDBC-compliant source to scan basic metadata that standard JDBC calls provide; however, many native erwin Standard Data Connectors are included out of the box. These native connectors improve performance and breadth of metadata extracted from source systems.
The latest release of erwin DI Suite natively scans Snowflake databases to document the data-at-rest structures. The erwin native Snowflake Standard Data Connectors automatically scan and ingest metadata from Snowflake into erwin DI, enabling data mapping to and from Snowflake structures.
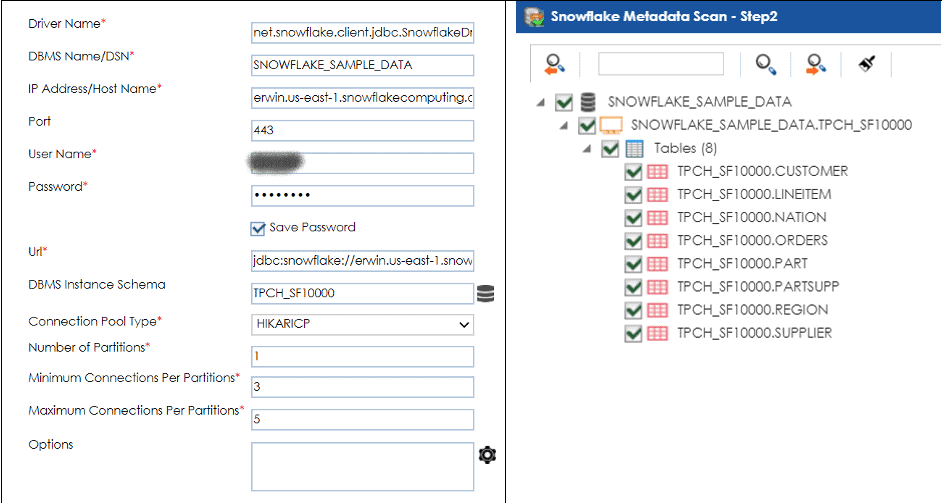
After you have configured and connected to the Snowflake database using the proper JDBC credentials, you can harvest metadata. The scanned metadata is housed in the metadata manager under a Snowflake source type. Standard technical metadata is captured, such as datatype, length, precision, and scale. You can extend this metadata with additional fields such as definitions, business-specific user-defined fields (UDF), sensitivity-level indication, and even association to business terms defined in the business glossary manager, which helps enable data democratization. (Data democratization will be covered in a future blog.)
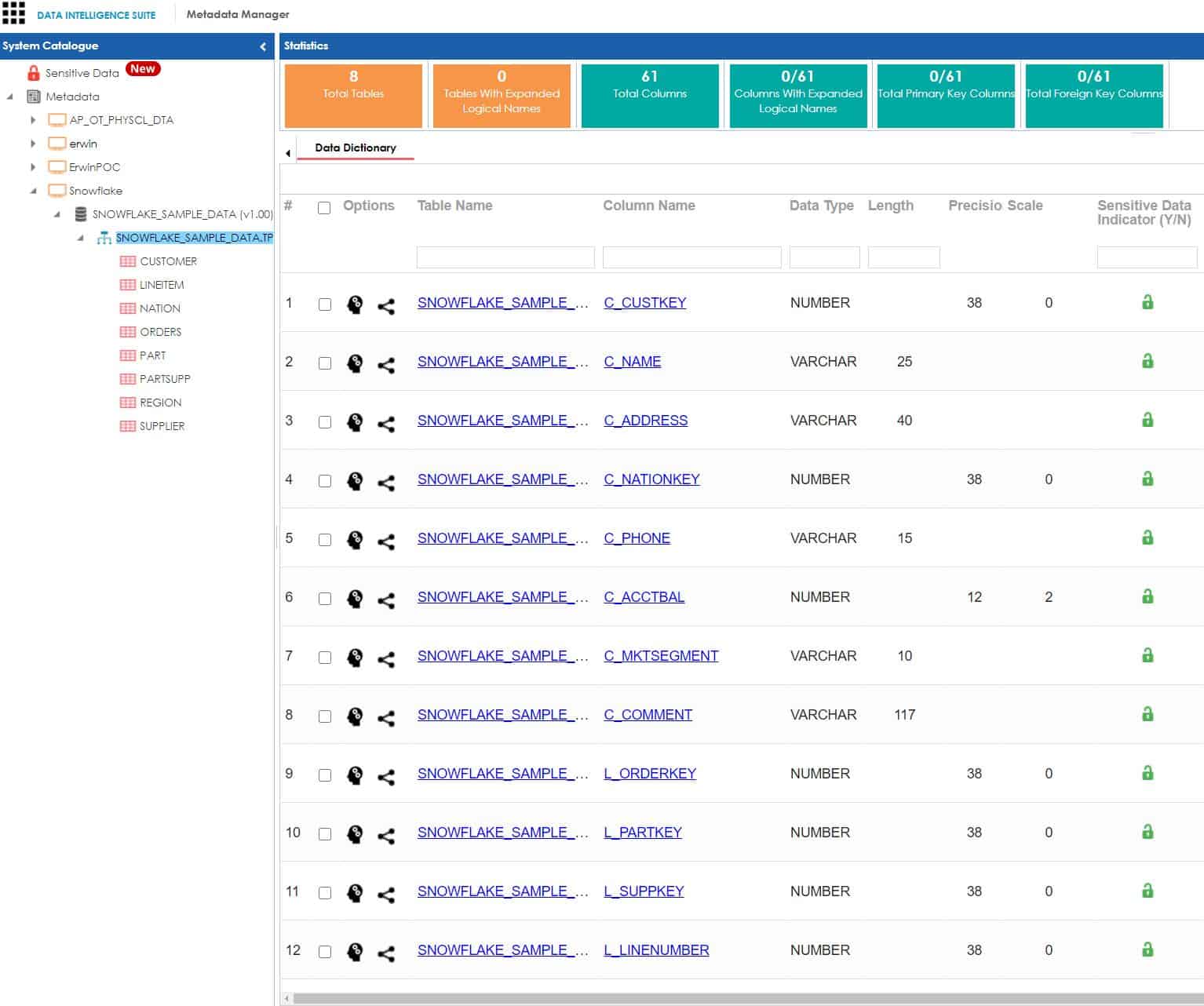
Step-by-step instructions to configure, connect to, and scan Snowflake metadata into erwin DI can be found in the erwin Bookshelf.
erwin Smart Data Connectors
erwin Smart Data Connectors enable organizations to automatically connect, catalog, and document end-to-end lineage across many third-party technology platforms. A data governance program can achieve the fastest time to business value using erwin automation and the intelligence preconfigured into each erwin Smart Data Connector.
The automation framework embedded in erwin DI is owned, developed, and supported by erwin. It includes the industry’s largest library of smart data connectors to scan and auto-document ETL, ELT, BI, and procedural source code for lineage and impact analysis. These auto-documentation processes are incrementally updated and configured to a client’s production release cycle so that erwin DI is always in sync with the production environment.
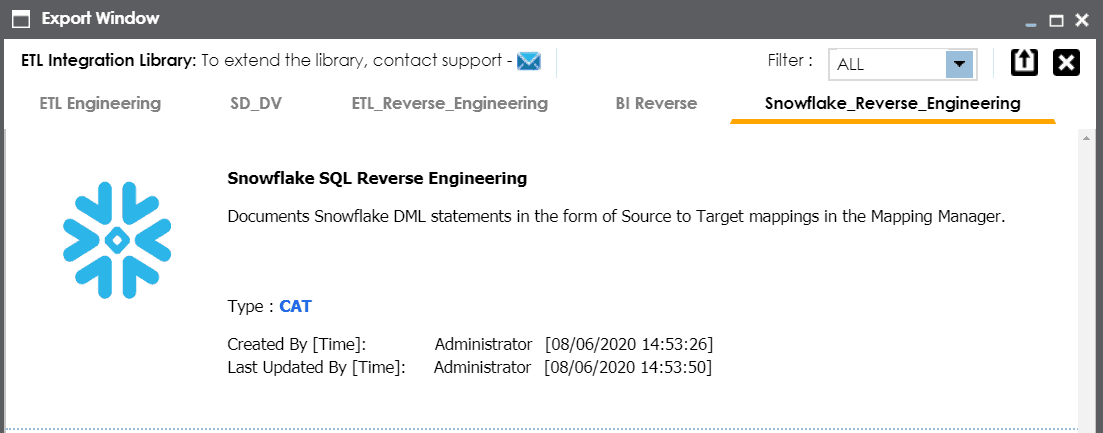
The Snowflake SQL Reverse Engineering Smart Data Connector parses Snowflake DML statements into source-to-target mappings within the erwin Metadata Manager module of erwin DI. These mappings are used to generate lineage analysis reports that can trace data in motion across the Snowflake environment.
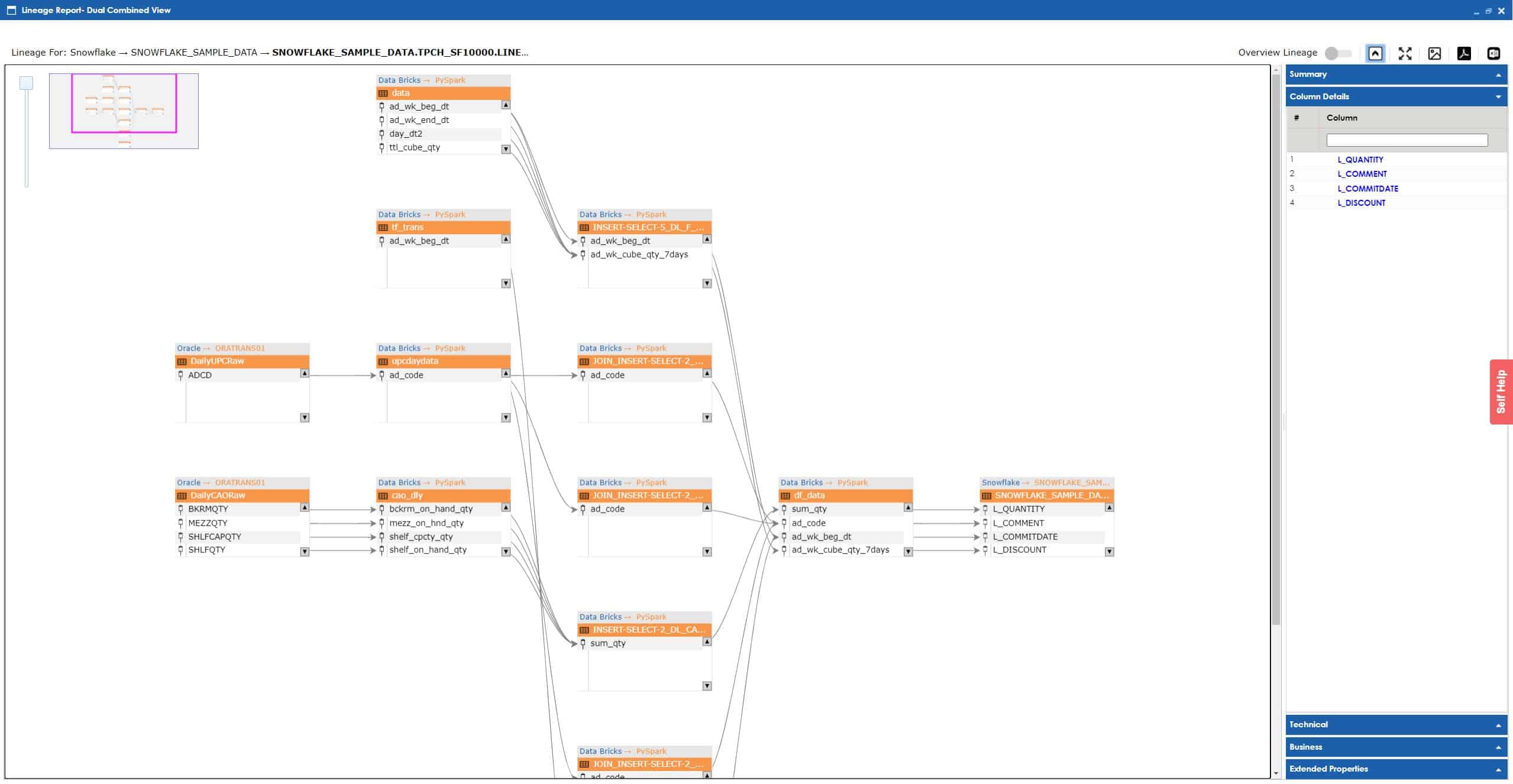
erwin Smart Data Connectors can integrate with any tool that provides an SDK. The SDK can exist in the form of XML or JSON flat file exports, API integration, or direct database repository connectivity. No matter what form the Snowflake DML exists in, it can be documented automatically by applying erwin Smart Data Connectors. Examples include Apache Airflow, Talend or other ETL tools, or direct Snowflake SQL embedded in Python scripts. Utilizing the right combination of erwin Smart Data Connectors, the lineage documented from your Snowflake environment can be incorporated into the lineage of the enterprise sources feeding into Snowflake’s cloud data platform for true end-to-end visibility of data movement.
To see erwin DI Suite integration with Snowflake in action, go to the erwin website to request a free demo.
About the guest blogger: John Carter serves as Director of Automation Engineering at erwin and has been in the IT industry for more than 20 years. He is the leader of erwin’s Managed Automation team, helping their clients develop smart solutions for auto-documentation, code-generation, and other metadata-driven automation initiatives.



