
We took our first step toward the adoption of Apache Arrow with the release of our latest JDBC and Python clients. Fetching result sets over these clients now leverages the Arrow columnar format to avoid the overhead previously associated with serializing and deserializing Snowflake data structures which are also in columnar format.
This means you can fetch result sets much faster while conserving memory and CPU resources. If you work with Pandas DataFrames, the performance is even better with the introduction of our new Python APIs, which download result sets directly into a Pandas DataFrame. Internal tests show an improvement of up to 5x for fetching result sets over these clients, and up to a 10x improvement if you download directly into a Pandas DataFrame using the new Python client APIs.
Performance Benchmarks
The following charts show the results of some of our internal benchmarks comparing client driver versions that use the new Arrow format to previous versions that did not:
Figure 1. JDBC fetch performance benchmark for JDBC client version 3.11.0 versus 3.9.x
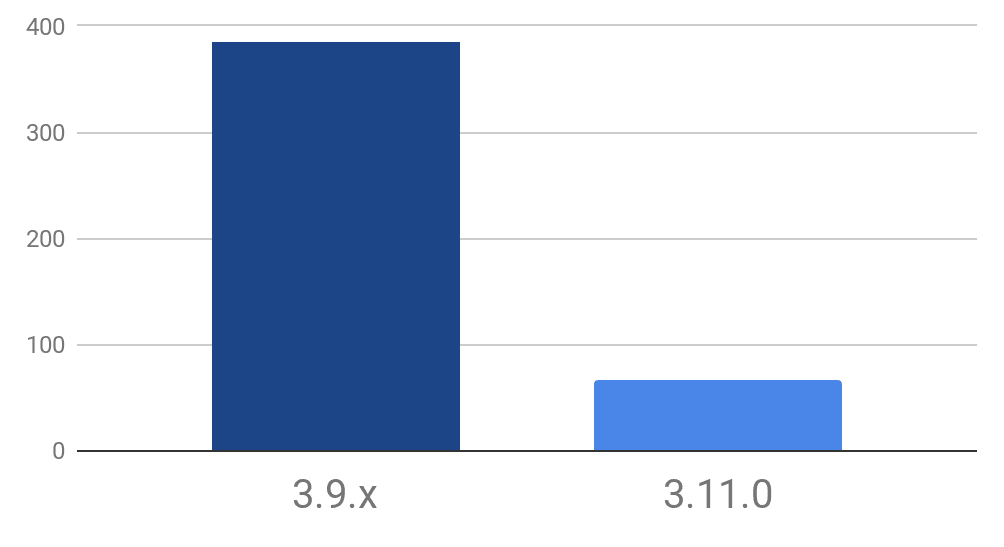
Figure 2. Python fetch performance benchmark for Python client version 2.1.1 versus 2.0.x
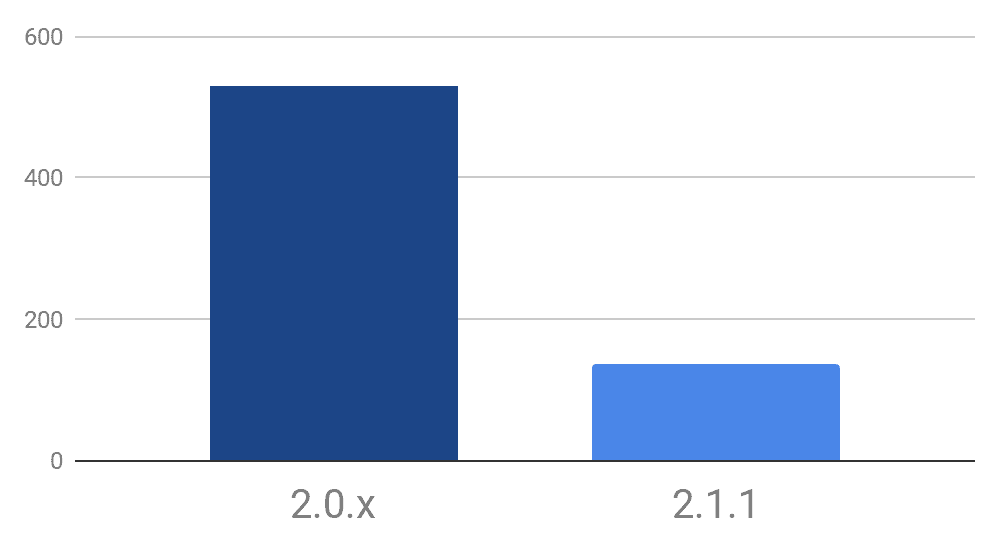
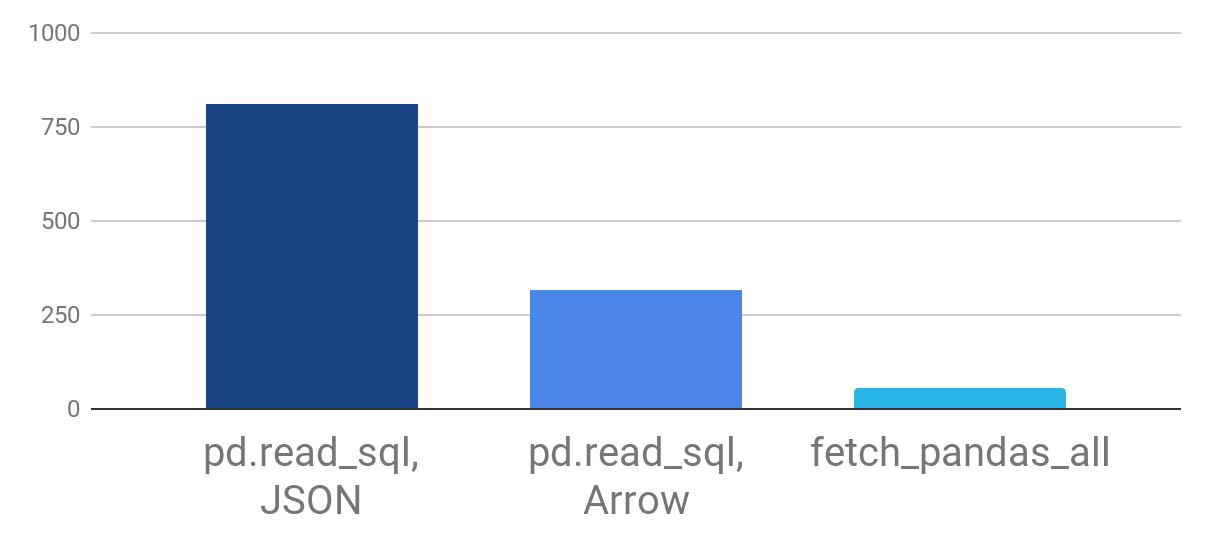
Figure 3. Pandas fetch performance benchmark for the pd.read_sql API versus the new Snowflake Pandas fetch_pandas_all API
Getting Started with the JDBC Client
Download and install the latest Snowflake JDBC client (version 3.11.0 or higher) from the public repository and leave the rest to Snowflake. (Note: The most recent version is not always at the end of the list. Versions are listed alphabetically, not numerically. For example, 3.10.x comes after 3.1.x, not after 3.9.x.)
You must use JDBC version 3.11.0 or higher to take advantage of this feature. Check our Client Change Log for more details.
Getting Started with the Python Client
Download the latest version of the Snowflake Python client (version 2.2.0 or higher).
To take advantage of the new Python APIs for Pandas, you will need to do the following:
- Ensure you have met the following requirements:
- Snowflake Connector 2.2.0 (or higher) for Python, which supports the Arrow data format that Pandas uses
- Python 3.5, 3.6, or 3.7
- Pandas 0.25.2 (or higher); earlier versions may work but have not been tested
- pip 19.0 (or higher)
- Install the Pandas-compatible version of the Snowflake Connector for Python:
pip install snowflake-connector-python[pandas]
3. Use the new APIs:
Example:
ctx = snowflake.connector.connect( host=host, user=user, password=password, account=account, warehouse=warehouse, database=database, schema=schema, protocol='https', port=port) # Create a cursor object. cur = ctx.cursor() # Execute a statement that will generate a result set. sql = "select * from t" cur.execute(sql) # Fetch the result set from the cursor and deliver it as the Pandas DataFrame. df = cur.fetch_pandas_all() # ...
Example:
ctx = snowflake.connector.connect( host=host, user=user, password=password, account=account, warehouse=warehouse, database=database, schema=schema, protocol='https', port=port) # Create a cursor object. cur = ctx.cursor() # Execute a statement that will generate a result set. sql = "select * from t" cur.execute(sql) # Fetch the result set from the cursor and deliver it as the Pandas DataFrame. for df in cur.fetch_pandas_batches(): my_dataframe_processing_function(df) # ...
Refer to the following page for more details.
Next Steps
We are excited to take this first step and will be working to implement Apache Arrow with our remaining clients (ODBC, Golang, and so on) over the next few months.