
“The features you use influence more than everything else the result. No algorithm alone, to my knowledge, can supplement the information gain given by correct feature engineering” —Luca Massaron, Data Scientist
Snowflake continues to set the standard for data in the cloud by removing the need to perform maintenance tasks on your data platform and giving you the freedom to choose your data model methodology for the cloud.
A 2016 data science report from data enrichment platform CrowdFlower found that data scientists spend around 80% of their time in data preparation (collecting, cleaning, and organizing of data) before they can even begin to build machine learning (ML) models to deliver business value. Collecting, cleaning, and organizing data into a coherent form for business users to consume are all standard data modeling and data engineering tasks for loading a data warehouse. Just as a dimensional data model will transform data for human consumption, ML models need raw data transformed for ML model consumption through a process called “feature engineering.” It’s a vital step when building ML models in order to ensure that the data is in a good shape for the model to be successful and for it to perform efficiently once its’ deployed.
Data Vault explicitly defines a set of standards called “hard rules” to automate data extraction, cleaning, and modeling into raw vault tables. Data Vault’s “soft rules” are those auditable transformations that use raw (and other business vault) data artifacts whose outcomes are loaded into a business vault based on the same business entity and unit of work as raw vault. Data Vault as a practice does not stipulate how you transform your data, only that you follow the same standards to populate business vault link and satellite tables as you would to populate raw vault link and satellite tables.
In this blog post we will use what we have learned in this Data Vault blog series to support the data preparation requirements for ML on Snowflake, using Data Vault patterns for modeling and automation.
- Immutable Store, Virtual End Dates
- Snowsight Dashboards for Data Vault
- Point-in-Time Constructs and Join Trees
- Querying Really Big Satellite Tables
- Streams and Tasks on Views
- Conditional Multi-Table INSERT, and Where to Use It
- Row Access Policies + Multi-Tenancy
- Hub Locking on Snowflake
- Out-of-Sequence Data
- Virtual Warehouses and Charge Back
- Handling Semi-Structured Data
- Feature Engineering and Business Vault
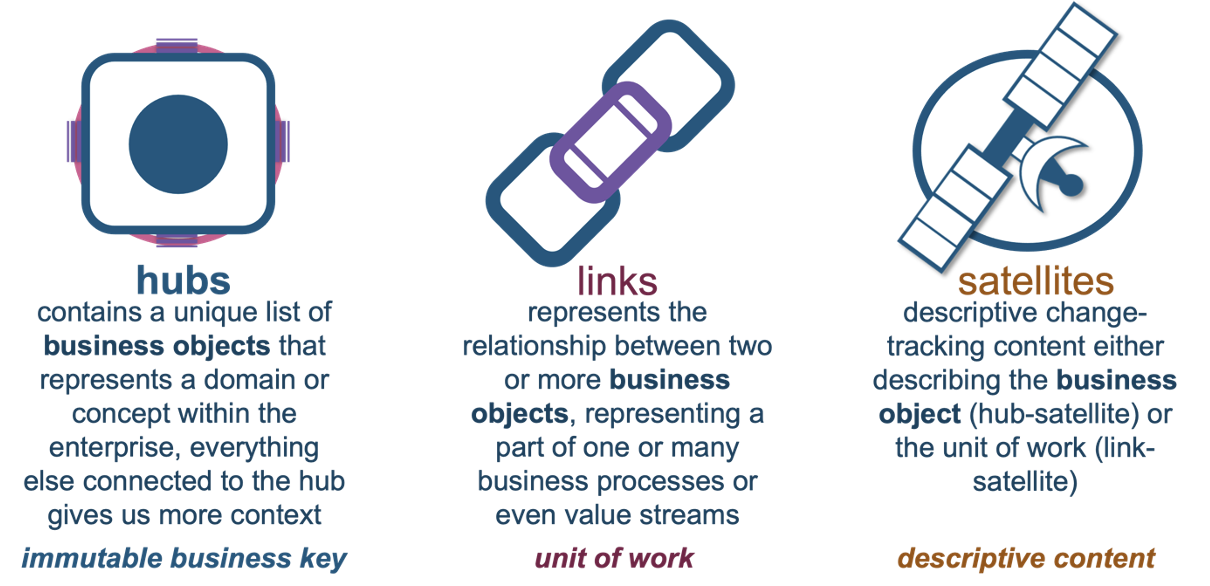
A reminder of the Data Vault table types:
To visualize how Data Vault can support ML, let’s evaluate where data management fits into a workflow of a typical ML project.
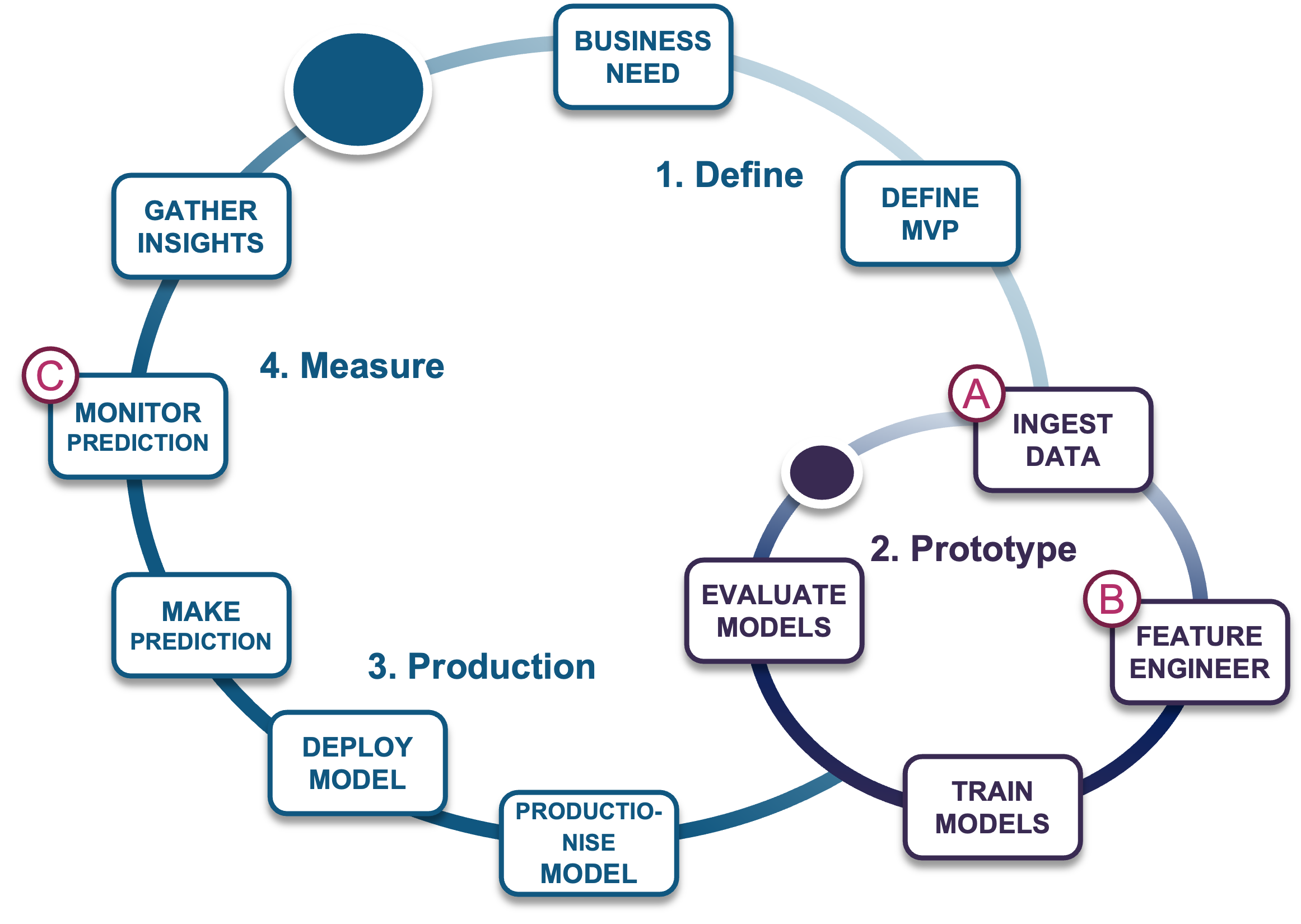
Once a business need is defined and a minimal viable product (MVP) is scoped, the data management phase begins with:
- Data ingestion: Data is acquired, cleansed, and curated before it is transformed.
- Feature engineering: Data is transformed to support ML model training.
- Trained models: ML models are deployed into production while predictions are monitored for ML model performance.
As your data science team grows, more ML pipelines are needed to support this cycle; the risk of deploying redundant, non-standard ML pipelines grows and the overall efficiency of the data science practice suffers as well. For this reason, a new data management for ML framework has emerged to help manage this complexity: the “feature store.”
Feature store
As described in Tecton’s blog, a feature store is a data management system for managing ML feature pipelines, including the management of feature engineering code and data. The feature store enables teams to share, discover, and use highly curated sets of features to support ML experiments and deployment to production.
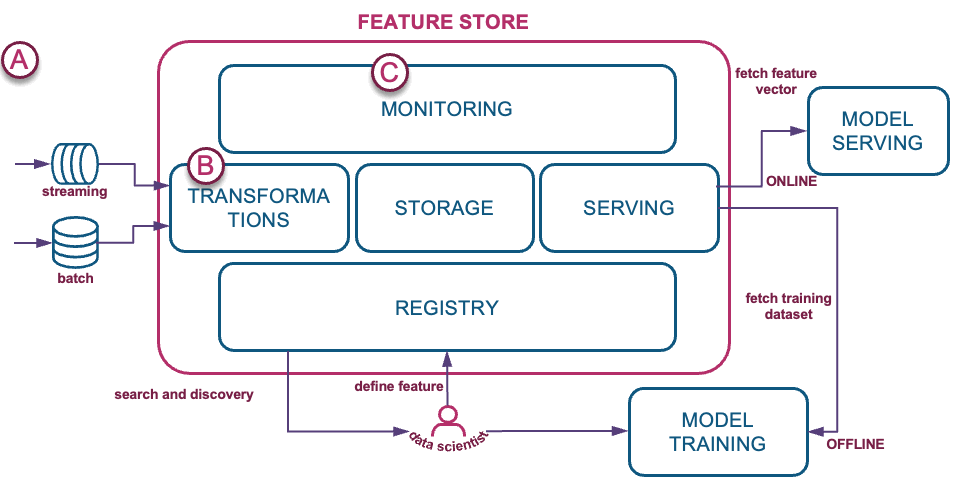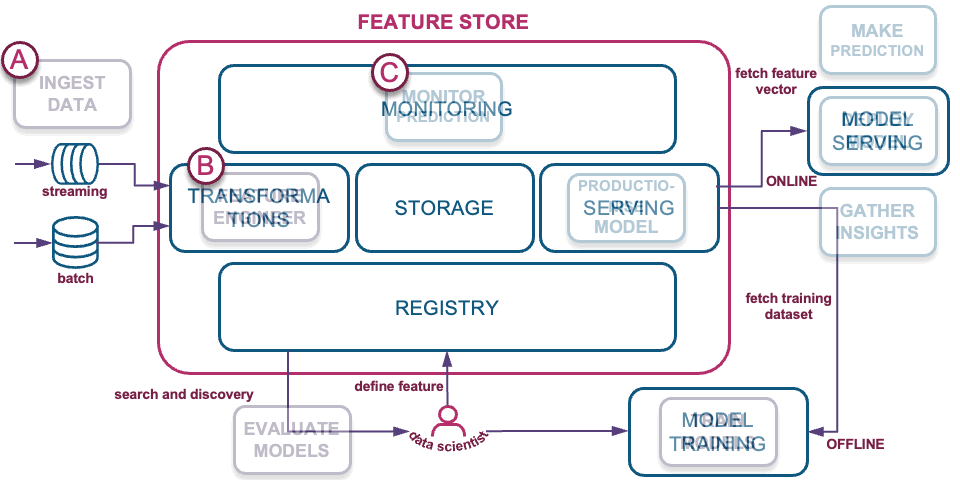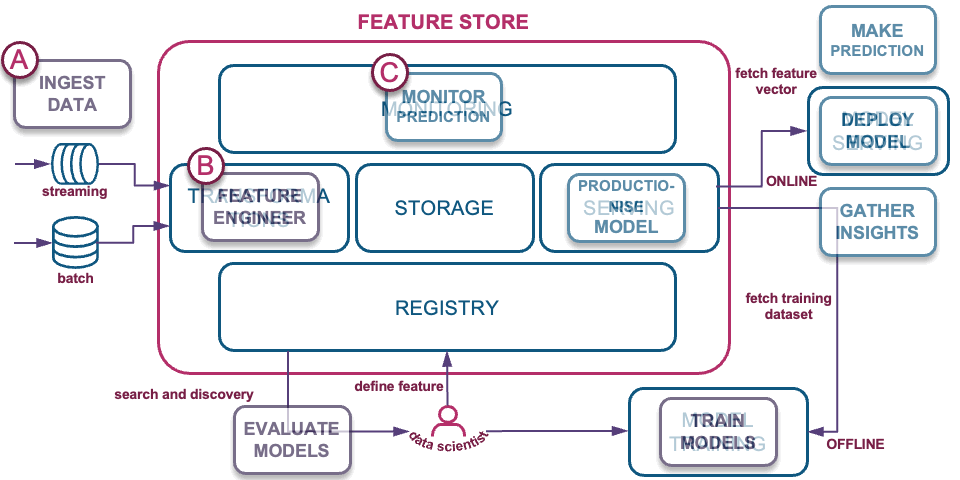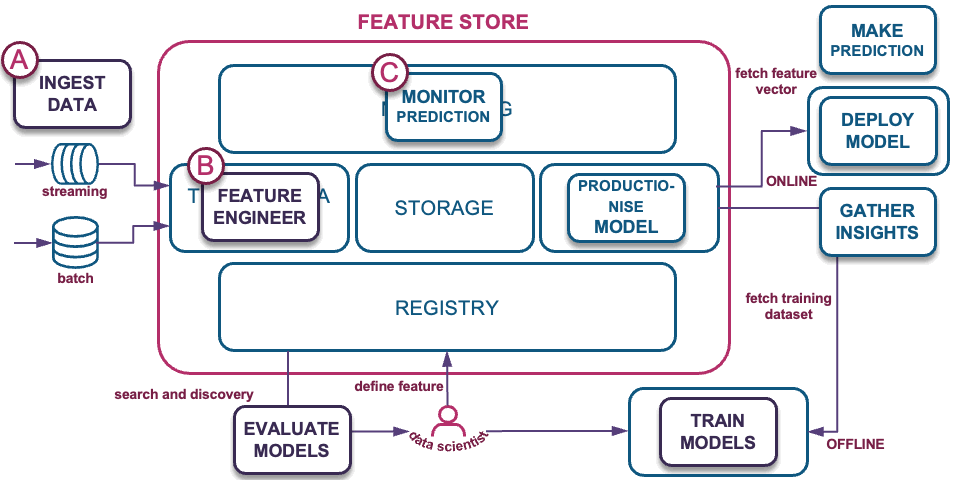
So is this similar to data engineering pipelines into a data lake/warehouse? Yes, feature stores are part of the MLOps discipline. Let’s review how Data Vault on Snowflake supports the data model components of a feature store:
A) Ingest RAW data into a modeled raw vault
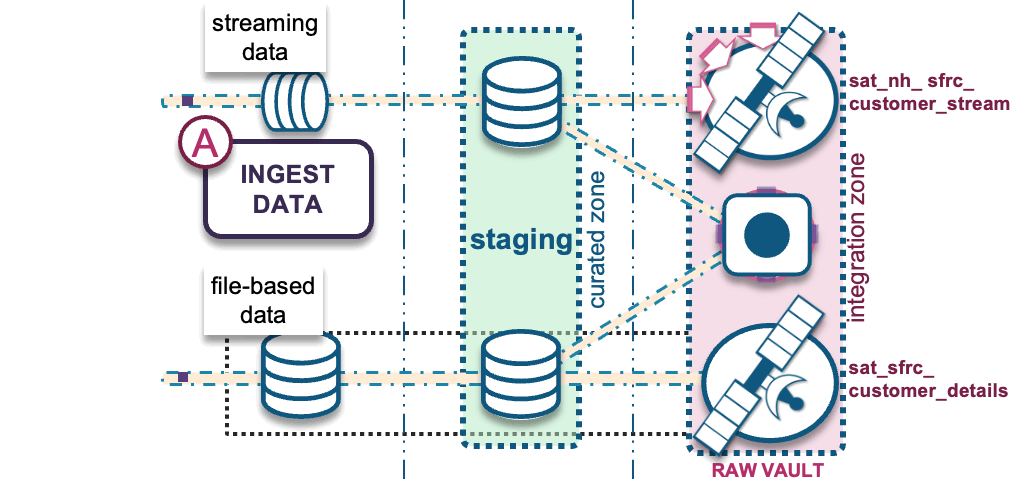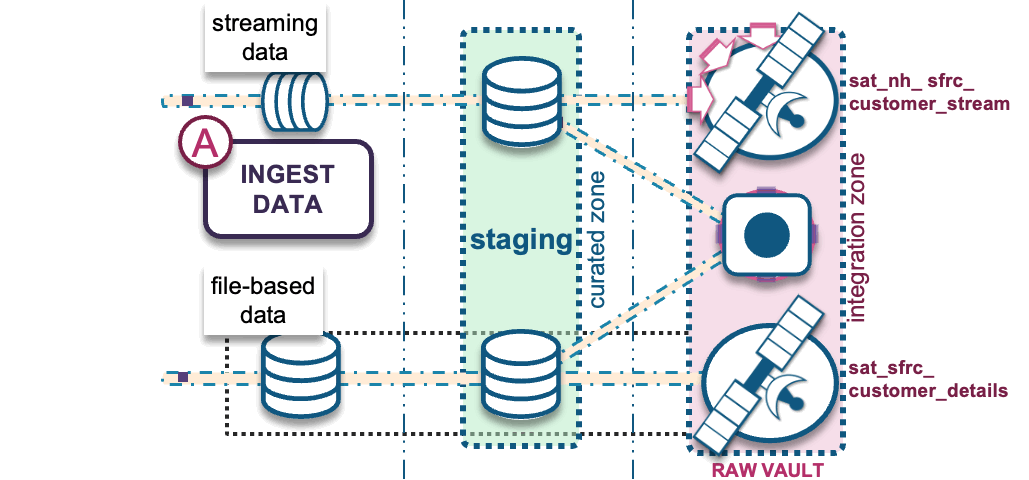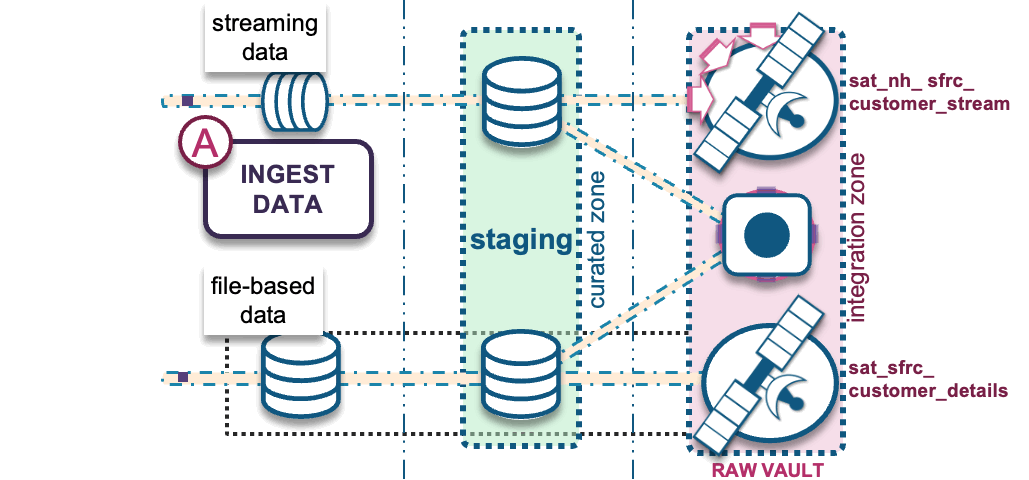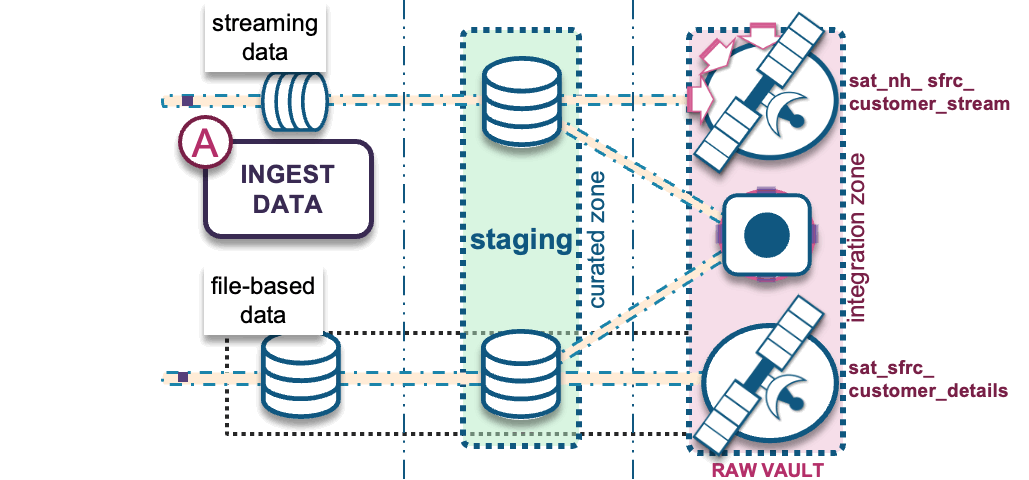
through the following options:
- File-based batch COPY into Snowflake: This can be automated using a partner ELT/ETL tool, which will execute a Snowflake COPY command to convert a supported file format into a traditional Snowflake table.
- Snowpipe micro-batch into Snowflake: Either triggered through a cloud service provider’s messaging service (such as AWS SQS, Azure Event notification, or Google Pub/Sub) or making calls to Snowpipe’s REST API endpoints. Use Snowflake’s native Kafka Connector to configure Kafka topics into Snowflake tables.
- External table registration and consumption as:
- Parquet: A popular column-oriented data file format for analytics
- AVRO: A serialization format for data under streaming pipelines
- ORC: An optimized row-columnar file format designed for Hive
- Iceberg: An open table format specifically designed for analytical queries. The table is stored underneath as Parquet, but to the user the format’s manifest allows for advanced analytical functions and simplified querying. It even has a time-travel feature like Snowflake tables do, and it will be supported within Snowflake’s internal named stage soon.
Snowflake can also ingest external tables from on-premises data sources via S3-compliant data storage APIs.
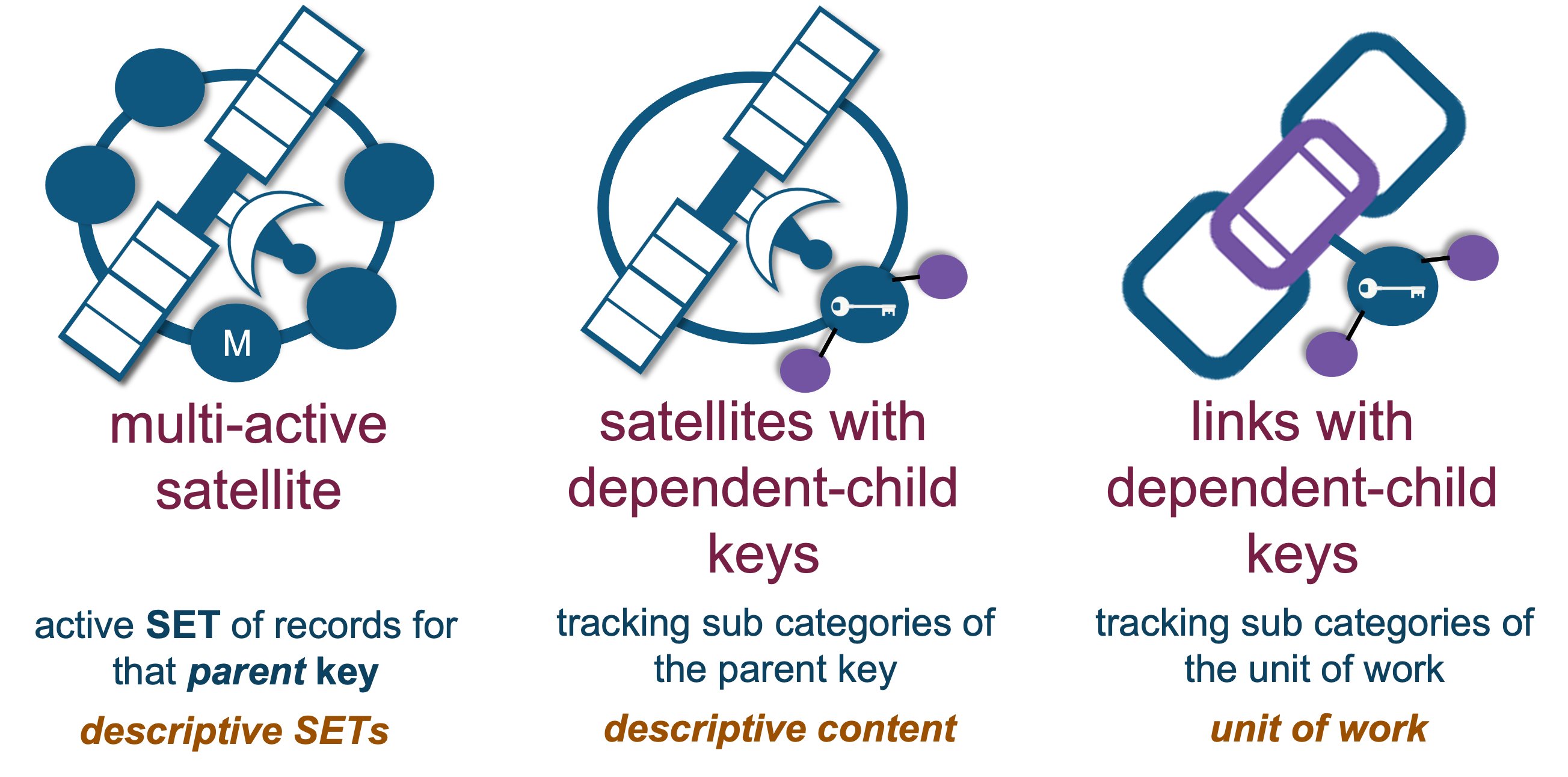
Batch/file-based data is modeled into the raw vault table structures as the hub, link, and satellite tables illustrated at the beginning of this post. But they can also be modeled into the following table structures based on the grain of the data being ingested and modeling requirements, such as:
Snowflake has recently introduced:
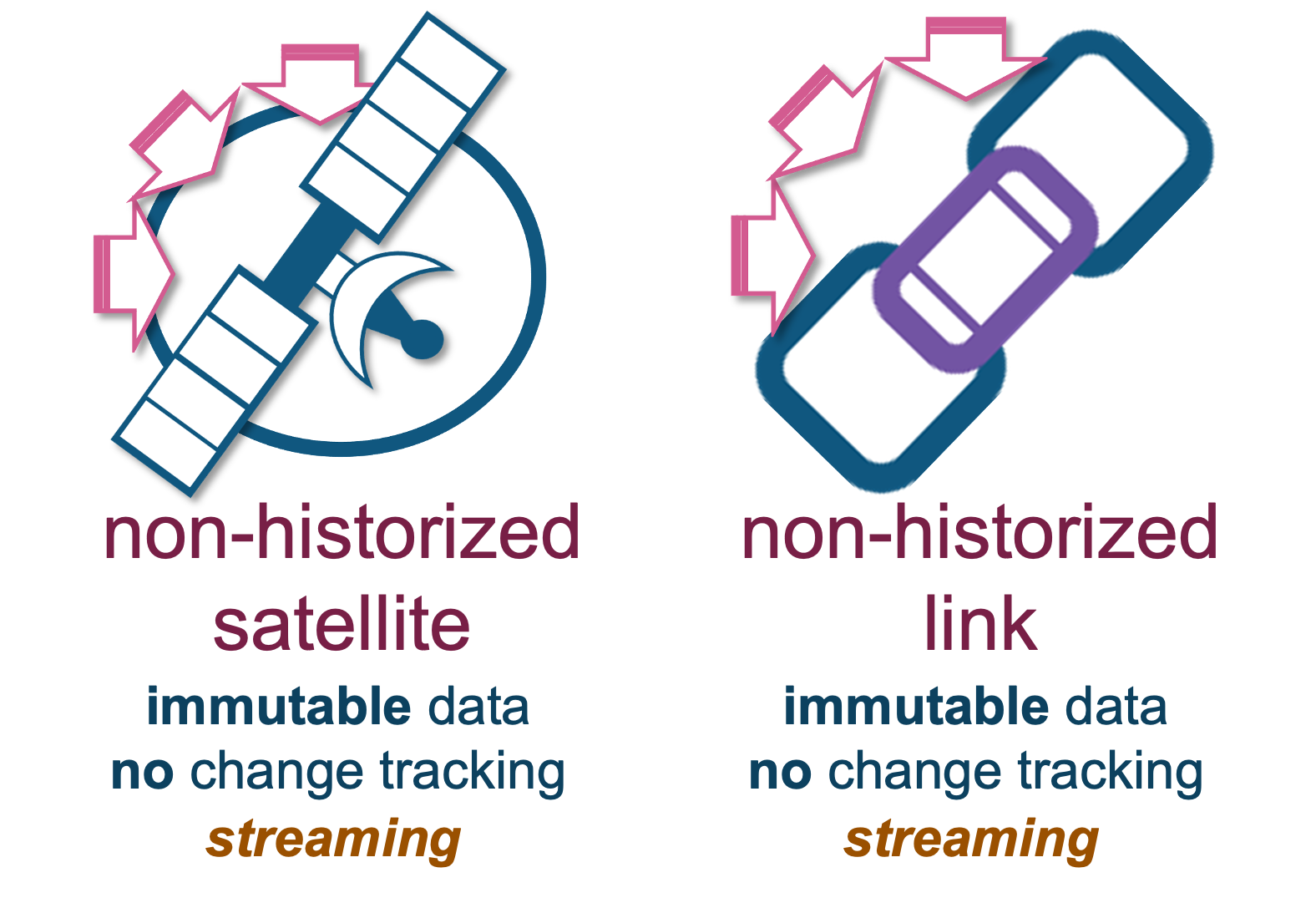
- Streaming API for Snowpipe: Real-time rowset inserts of records into Snowflake tables without the need to first stage the data as files.
Should the need arise, raw vault also supports real-time ingestion into non-historized link and satellite table structures; these differ from the previously noted Data Vault table types because the content we receive here is always a change, and therefore there’s no need to check that the incoming data is a true change—it always is.
Now that we know how to get data into Snowflake, let’s turn our attention to feature engineering options within Snowflake.
B) Transformations – Feature engineering into business vault
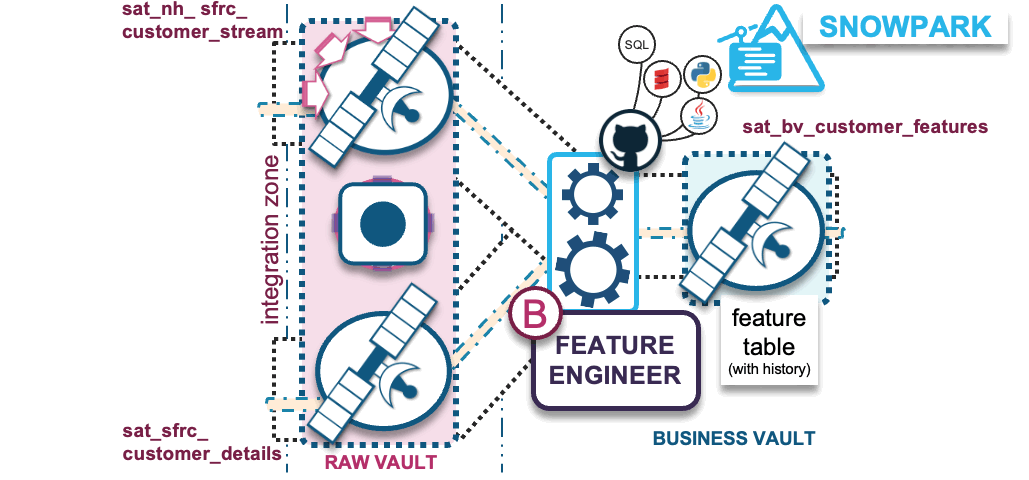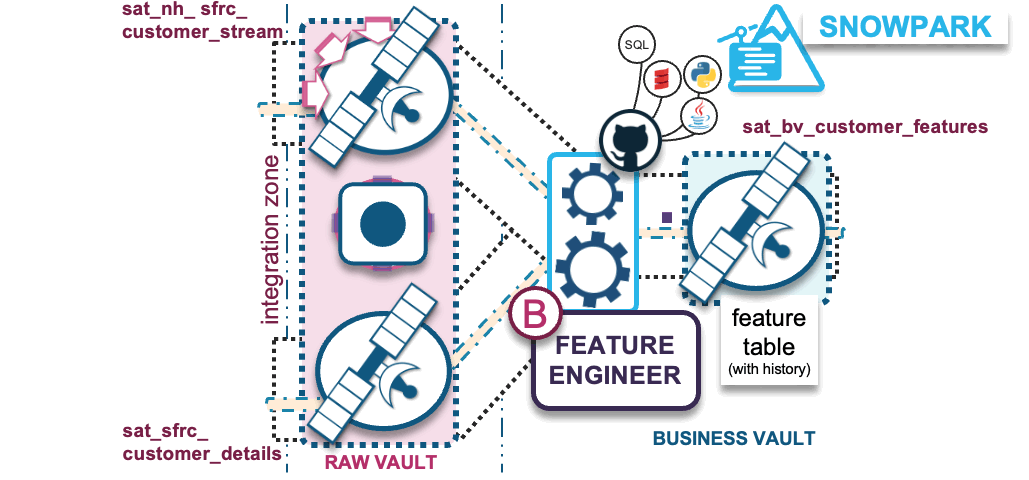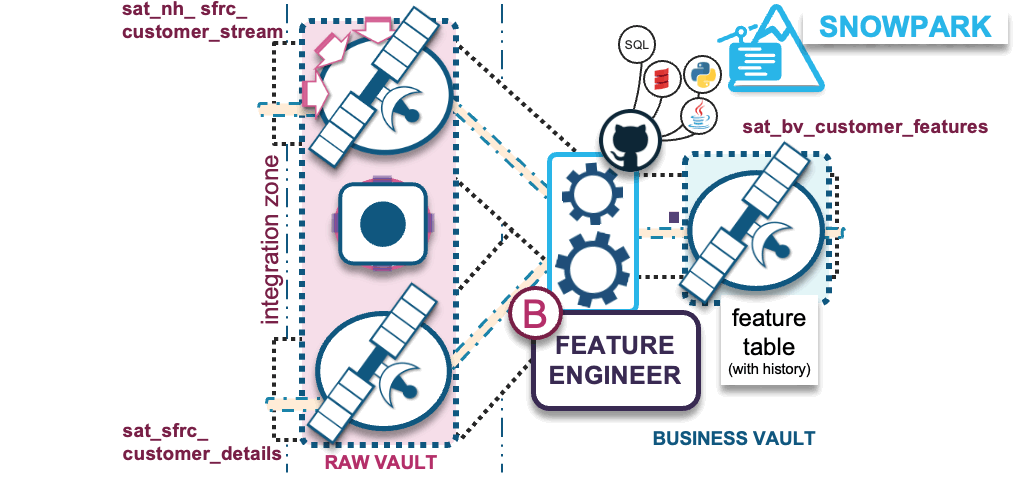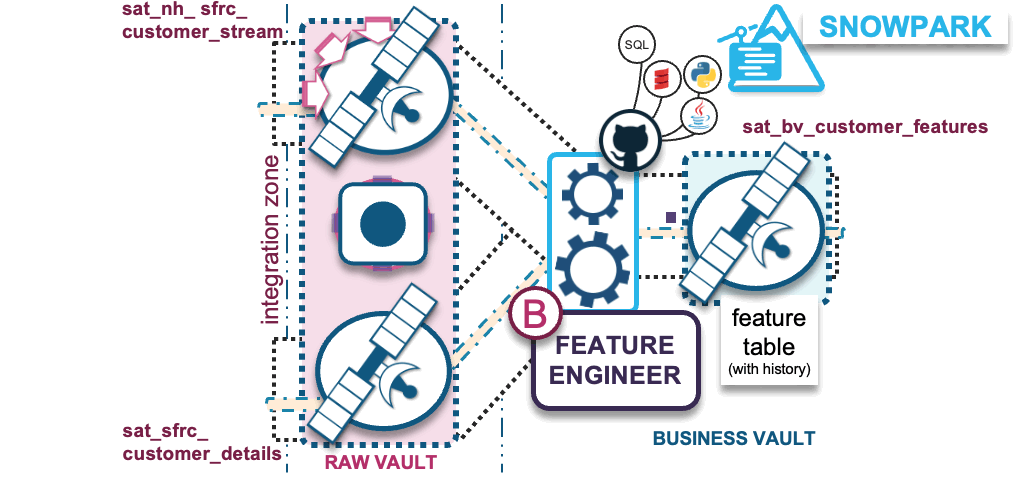
The purpose behind a business vault is to affordably augment existing business processes with additional intelligence to:
- Complete the business process as the business sees it, as opposed to how the source-system business model (raw data) sees it.
- Derive auditable facts and metrics (aka features) while reusing the same automation, auditability, and agility offered by raw vault table and loading patterns.
The transformations we apply under feature engineering prepares the data for ML model training. The reusable and shareable (by more than one ML model) feature values stored in business vault will aggregate raw data into meaningful/useful features (shape of data); these can be over varying time-windowed aggregations such as counts, min and max values, average, median, mean, standard deviation, etc.
The non-shareable and non-reusable feature values will not be stored in business vault because they have a point-in-time state such as:
- Numerical or categorical imputation (handling missing values)
- Log Transforms
- One-hot encoding
- Binning… oh my!
Features and feature engineering (such as business vault satellites) depend on:
- A single raw data source; a single raw vault satellite table = single source-system data source based on either a business object or unit of work (hub or link tables respectively)
- Multiple raw data sources (joining raw vault satellite tables)
- A combination of the above
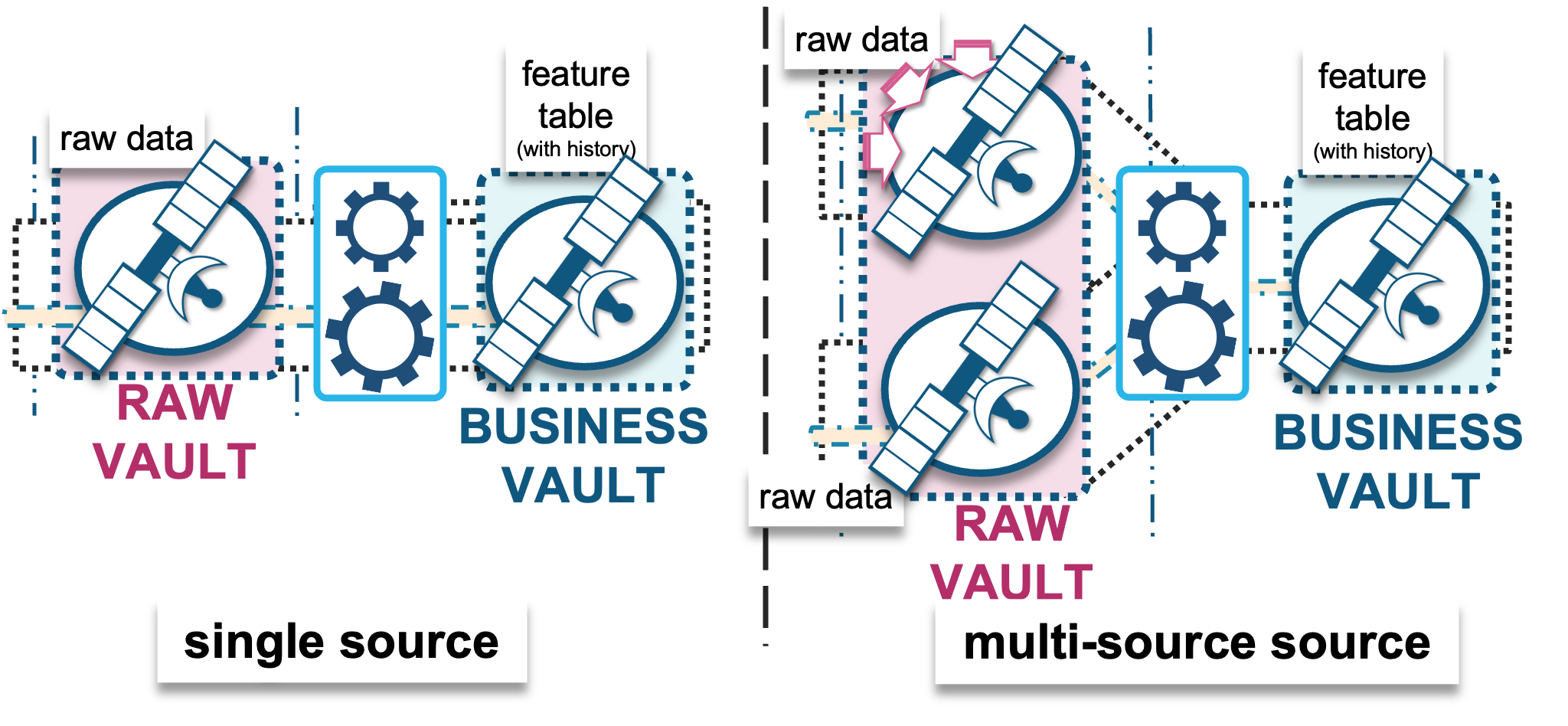
Using raw and business vault satellite table structures as separate entities ensures:
- Audit history, because we have a history of raw and engineered feature data.
- Agility and scalability, because since they are separate satellite tables, a change to one table does not affect the other unless it is explicitly requested to do so.
- Automation, because the same loader patterns are used for both and the same metadata tags are expected from both, meaning the applied date timestamp in the business vault will match up with the raw date timestamp where it came from.
Let’s explore that last point a little more closely…
Data versioning
Raw vault stores the business process output in its applied state as raw hub, link, and satellite tables. The timestamp of that business object’s state is what in Data Vault is referred to as the applied date timestamp, and as data is landed to be ingested into raw vault, a load date timestamp is also recorded per record to denote when that record enters the Data Vault. This means Data Vault is bi-temporal, and every record in every Data Vault table carries the applied timestamp (business process outcome state timestamp) and the data platform load timestamp. This also means if a correction must be applied from the source system, you can load the new corrected state into Data Vault and the load timestamp will be of a newer timestamp—this will be referred to as a newer version of that same record. There is no need to unload or delete content in Data Vault; simply load the new version and the version number is synonymous with the load date timestamp.
The same concept is applicable to business vault—you can version the feature code in git to reload and supersede the data loaded into business vault. New deltas are detected in business vault in one of or a combination of the following situations:
- The data the feature code is based on has changed (raw or other feature data).
- The feature code (soft rule) has changed.
A requirement of (feature) soft rule code is that it must be idempotent. If neither of the above conditions occurred and we re-run the transformation and load the same data, then the outcome must be the same every time; i.e., we do not load any new records by applied timestamp because we have already loaded them before.
Furthermore, the business vault satellite must carry the same applied date timestamp as the raw vault data it is based on, and a change in the business rule is recorded in the satellite table’s record-source column as a business rule name and version.
Of course, this is optional. You can (if you so desire) rely on Snowflake’s Time Travel feature and your chosen version control software to rollback and replay feature logic and reload the soft rule outcomes, but these will be limited to Time Travel’s configurable 90-day window. By using the Data Vault’s bi-temporal approach, the data loads and data selection are seamless and no refactoring is required. This approach ensures a full audit of what happened, even if a reload occurred and in fact the feature version can be recorded in the satellite table’s record source column value.
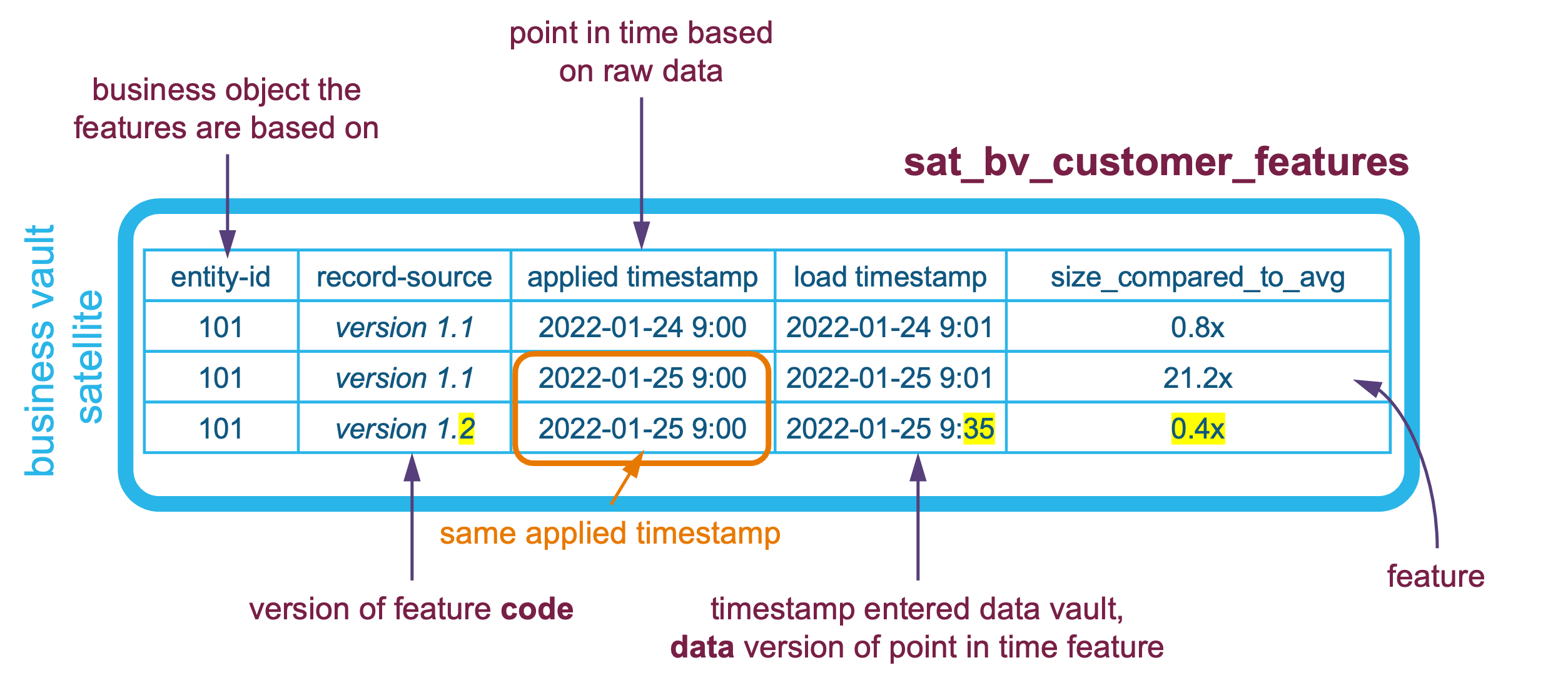
Feature set structure
Business vault artifacts are nothing more than the same table structures as raw vault, except the table is storing the outcomes of derived (soft rule) based on raw and other business vault content, which in our case are features and feature sets (aka feature grouping). Business vault therefore can be made up of:
- Satellite tables: Single row of applicable features at a point in time
- Satellite tables with one or more dependent child keys—this is when a sub-category is needed per business entity
- Multi-active satellite tables: When a SET of records are applicable at a point in time.
- Link tables: When constructing a relationship between participating entities as the unit of work as the business sees it, or what is needed (in our case) to support ML experiments. This differs from how the source-system has defined the unit of work, and may in fact be deterministic relationships between business entities based on soft business rules.
- An effectivity satellite table: By extension, if the business vault link table needs a way to track which is the current relationship record by a driver key, then a business vault effectivity satellite may be required. At the same time, the effectivity satellite can be expected to support the tracking of multiple relationships being active per driver key (or keys). Learn more about this Data Vault artifact here.
Depending on your need, a feature set (satellite) can be supported by:
- A wide table structure: Typically found under stable feature sets or feature sets dedicated to specific ML models. Each column is strongly typed as VARCHAR or NUMERIC (or other structured) column data types.
- A tall table structure: Using Snowflake’s VARIANT data type, features are stored as key-value pairs, which makes the management of features flexible and impervious to schema drift/evolution.
- A combination of both wide and tall.
Schema drift on a wide table structure needs an ALTER TABLE statement, whereas the tall table structure does not. As described in my earlier semi-structure satellite table post, some degree of flattening of the semi-structured data is required to keep the performance of using the table optimal if you need to retrieve the feature-vector (latest-value) efficiently.

This leads to another important concept in feature engineering that Data Vault’s standard loading patterns support:
Backfilling
With raw vault supporting the business vault, this means we can also use raw vault to backfill business vault features where needed. Feature backfilling is a common requirement for building up history to support quality ML model training from a point in time. When such an operation is desired, the Data Vault asks only that backfilled data carry an indication of where those backfilled records came from by recording it as such in the record source column of that record.
Also, keep in mind that the applied date timestamp should reflect the raw and/or business vault applied date timestamps (where the feature came from), but will have the same load date timestamp to show that the backfill occurred as a onetime load.
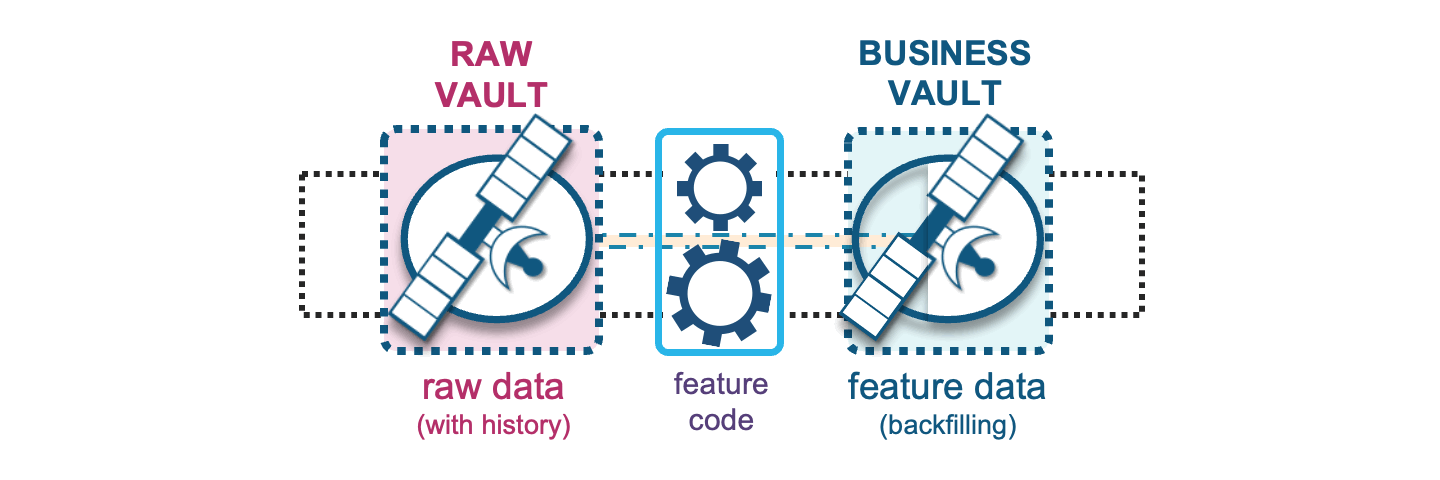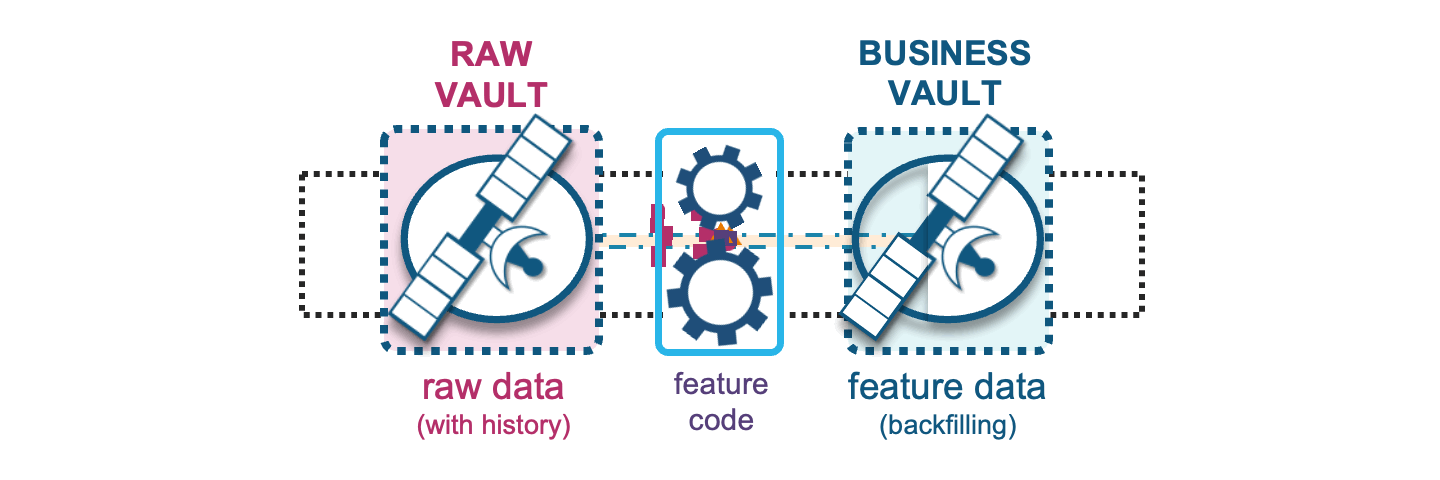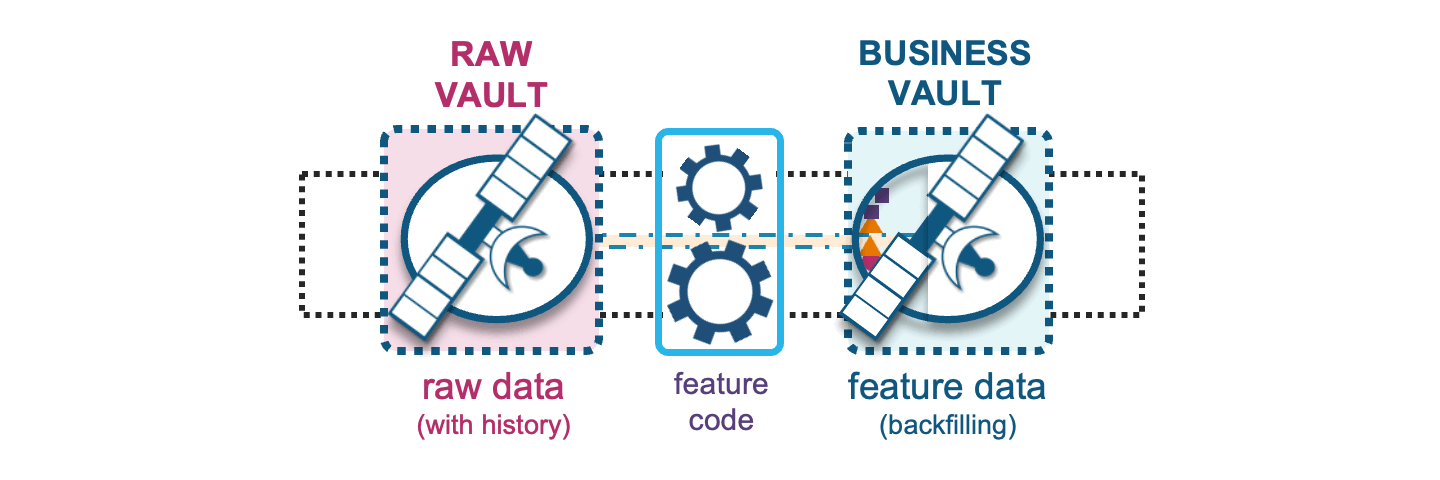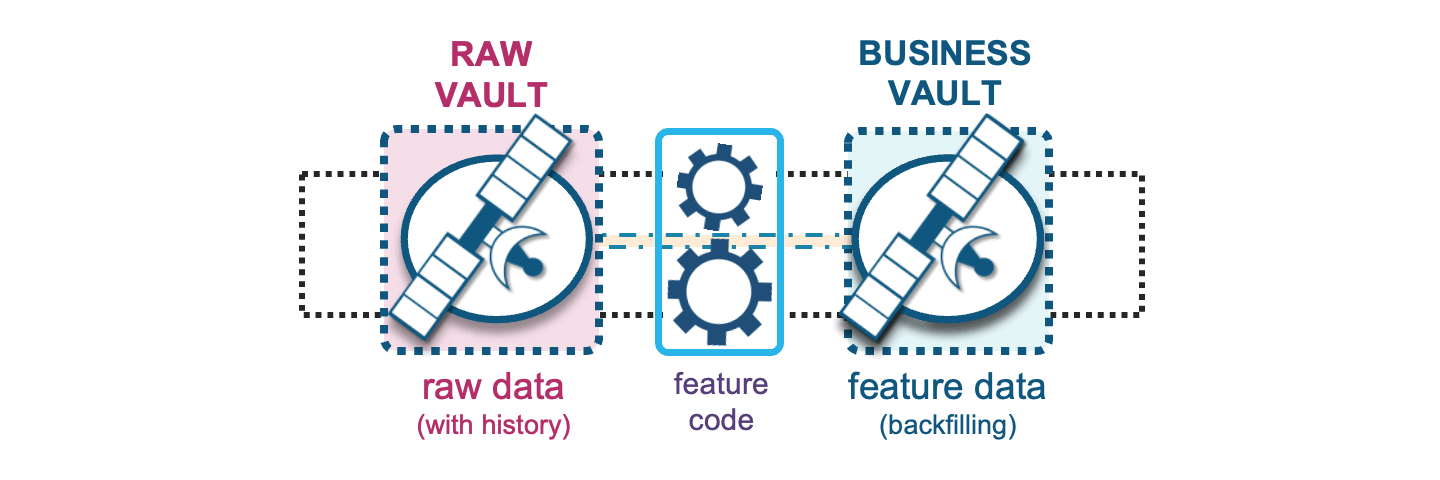
Now that we have the width and depth of feature data available, an ML model will be selective of what it needs from the feature table(s) as training, validation, and test data sets.
Feature training using information marts
In a Data Vault-based architecture, information marts are by default deployed as views. The same information mart data modelling technique is used to select the features you need to support an ML model as a feature view. Also, the same logarithmic and managed window concepts utilized in PIT and bridge tables discussed in earlier articles can be used to support this to produce feature views based on snapshots of the underlying data in the data vault.
As a refresher, these table and view structures are:
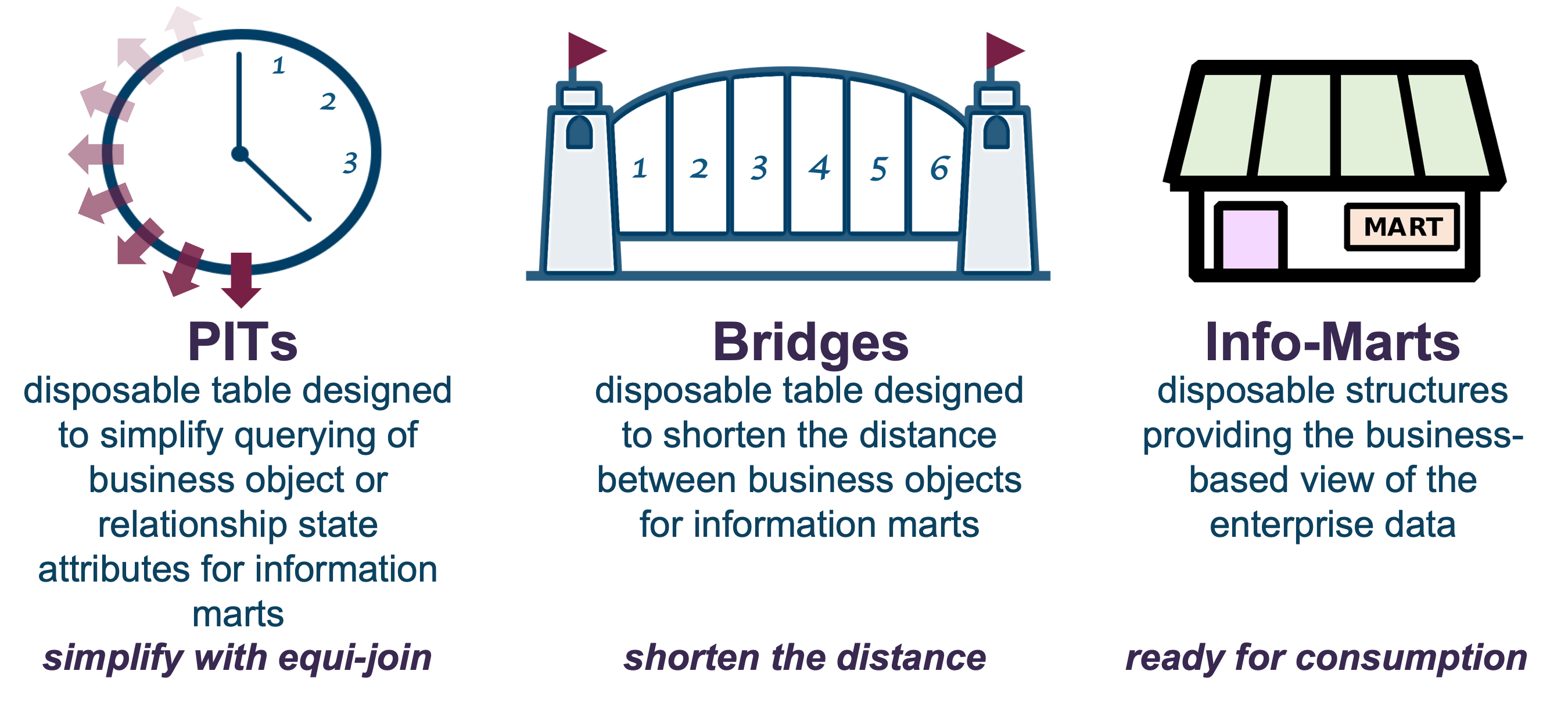
Using a snapshot-based table structure like PITs and bridges splits the feature views historically into a data set used for ML model training, and a data set to test that ML model where predictions have not yet been made. Meanwhile, data can be continually loaded into the underlying Data Vault constructs of hub, link, and satellite tables, but because the PITs and bridges used for feature selection haven’t had their keys and load dates updated, the feature views will still be based on the same snapshotted data.
If we were to rely on Snowflake clones of Timeravel periods of the business vault satellite, we would end up with all data up to that time-travel timestamp; whereas a PIT is instead constructed by a PIT window (start and end applied timestamp snapshot).
Feature engineering within Snowflake
Raw and business vault artifacts are the historized business process outcomes at a point in time. Raw vault does not dictate how those business process outcomes were calculated at the source system, nor does business vault dictate how the soft rules were calculated based on raw data.
What this means is that there is a separation of concern between feature transformation (code) and the table structure (data) storing those generated features, and since we have the latter in place, it does not matter how the former is executed.
Enter Snowpark!
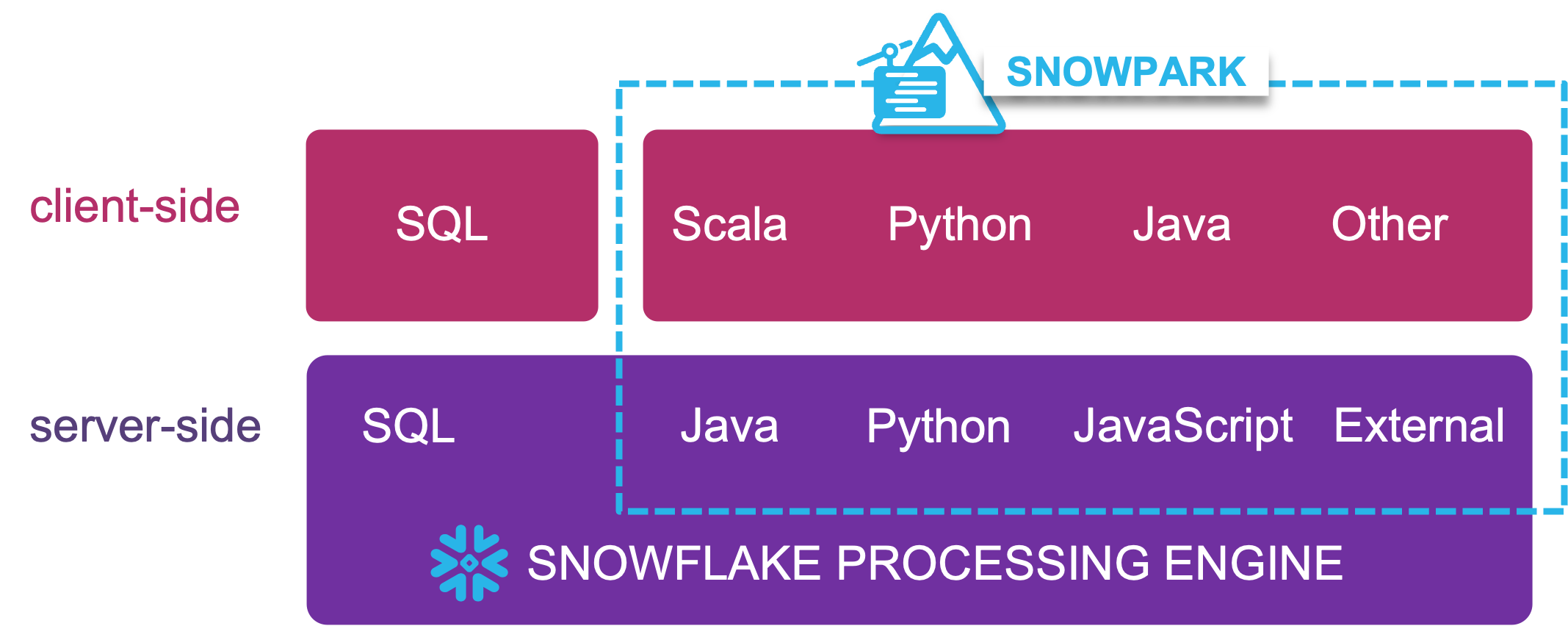
Snowpark is a feature-rich and secure framework for running transformations (feature engineering) and ML algorithms that are otherwise not possible when using SQL alone in Snowflake. By adding the ability to run your Java, Scala, and Python within the platform, you no longer need to rely on external programming interfaces to run your transformations/algorithms. The only requirement in terms of Data Vault is that the output of your transformations be stored in a business vault link or satellite table as we have described above.
With transformations and model training performed within Snowpark, you not only reduce the latency needed to produce features and inferences, but you simplify your overall architecture as well. The friction of data movement is reduced. In addition, by using our “set and forget” framework described in this article, the entire orchestration can be managed by Snowflake as well. Snowflake’s support for unstructured data also means you can annotate and process images, emails, PDFs, and more into semi-structured or structured data usable by your ML model running within Snowflake.
C) Model prediction monitoring
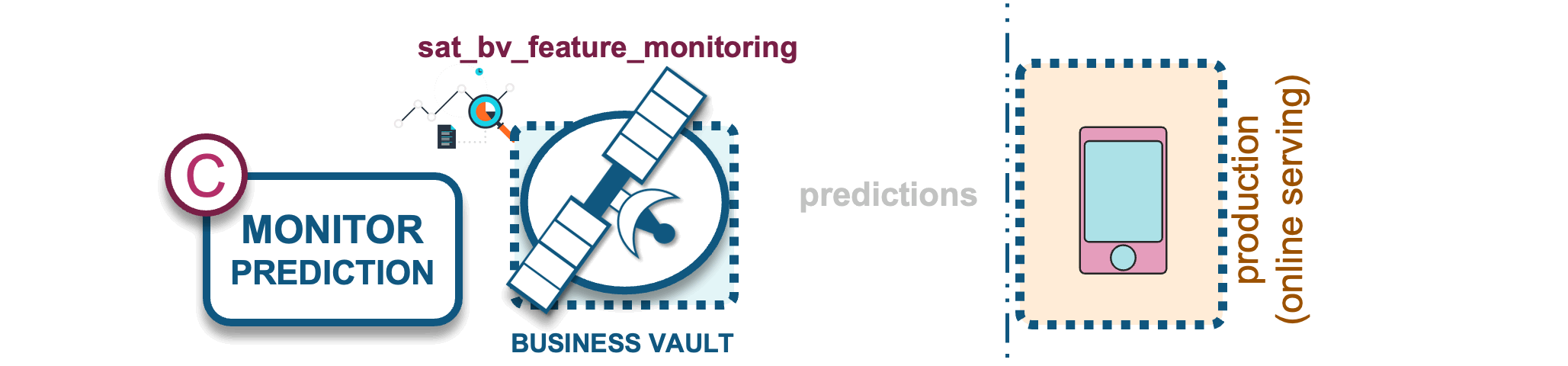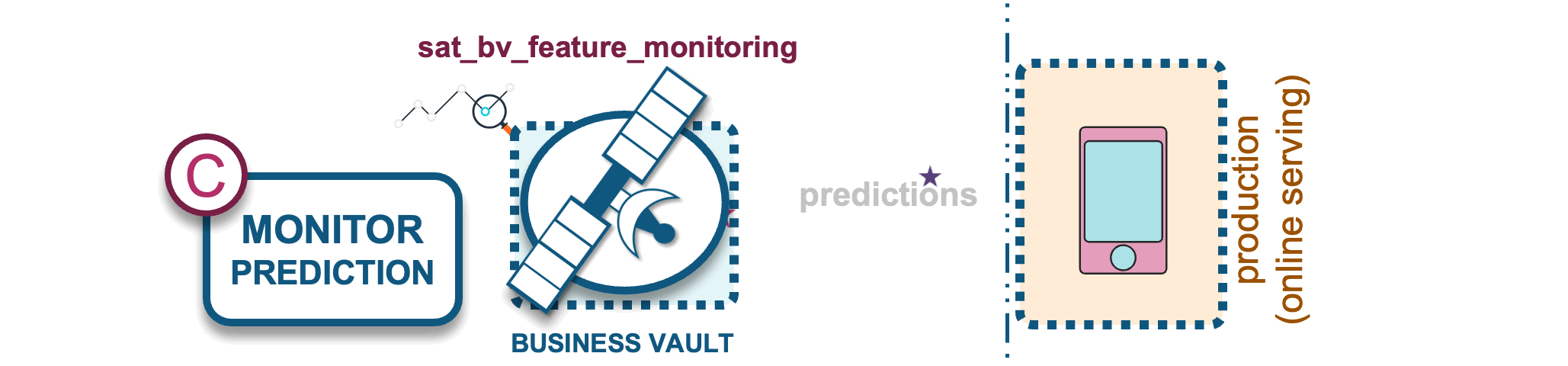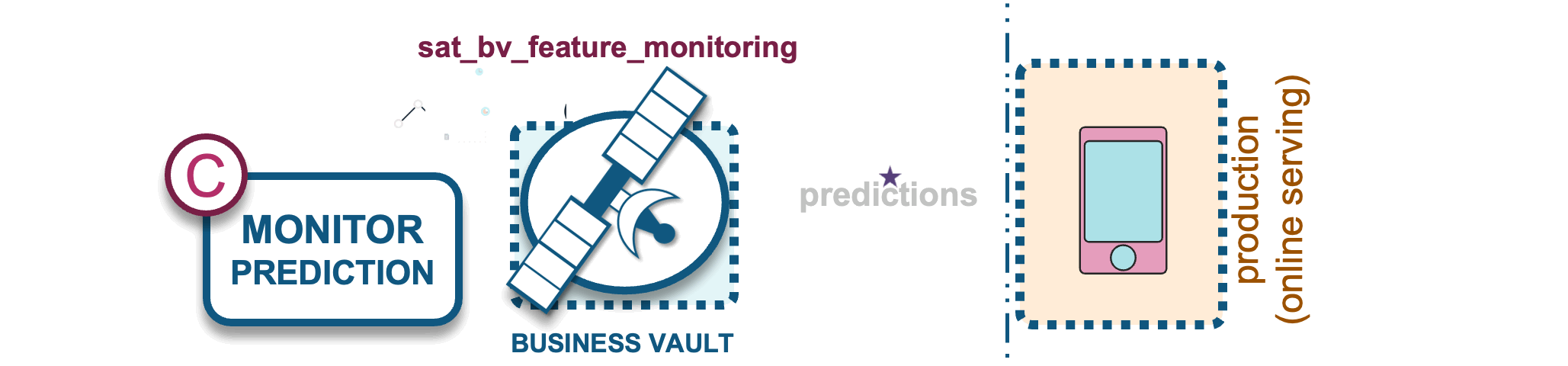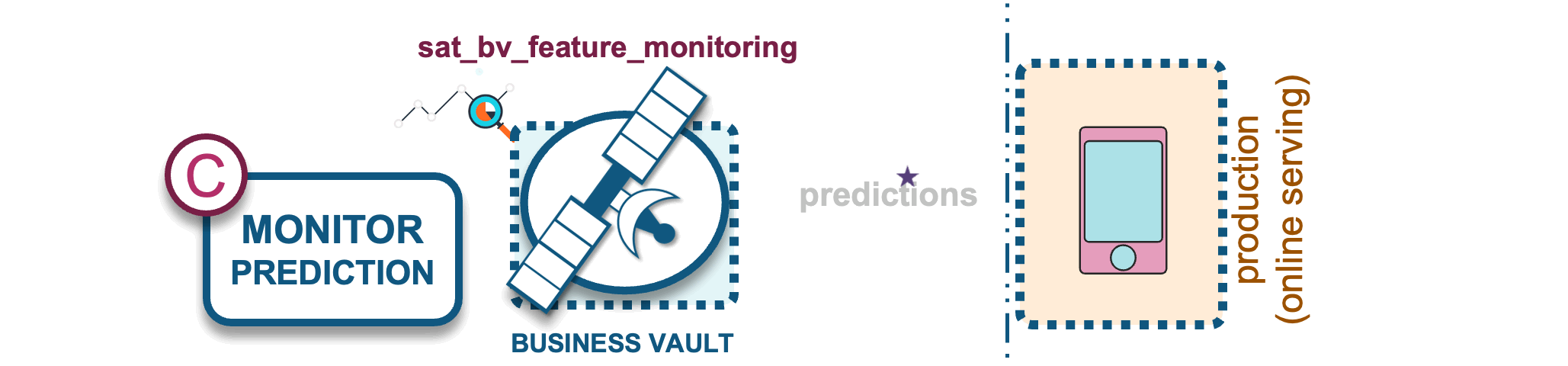
ML models require constant monitoring, as their performance can degrade due to several factors that cause the model outcome to skew:
- Concept drift: The statistical properties of the target variable (prediction) changes in unforeseen ways.
- Data drift: The statistical properties of the predictor variable (model input) changes in unforeseen ways.
To better understand drift, read this blog post.
A business vault satellite table will be used to store ML model predictions to support this analysis.
To complete our story, we will touch on a very important suite of features natively supported on Snowflake.
Data governance
As a data management framework, feature stores must consider data privacy and data governance. Snowflake natively supports:
- Dynamic Data Masking: Based on a policy role, you design who gets to see non-redacted or redacted columns data. This also includes the ability to base masking on an adjacent column within the same table/view. These methods can be applied to structured and semi-structured data as well.
- Tokenization: Using the same policy-based application of data masking, but with the options of obfuscating the content using partner software external to Snowflake.
- Row Access Policies: A popular method of allowing access to specific data rows based on functional roles.
- Auto-Classification: Using Snowflake’s trained semantic model, applying this system procedure classifies identifying and quasi-identifying columns with tags denoting probability and confidence you can use to apply masking or tokenization to.
- Anonymization: Applying k-anonymity or data hierarchies to anonymize sensitive data while still making it usable for ML model training.
Once the above are defined, they are reusable, and from a data transformation and selection perspective they are transparently applied. A Snowflake role without the required access simply will not see sensitive data because nothing within Snowflake can be executed or accessed without a role, which is a way to associate work to a virtual warehouse and access to the database and schema objects itself.
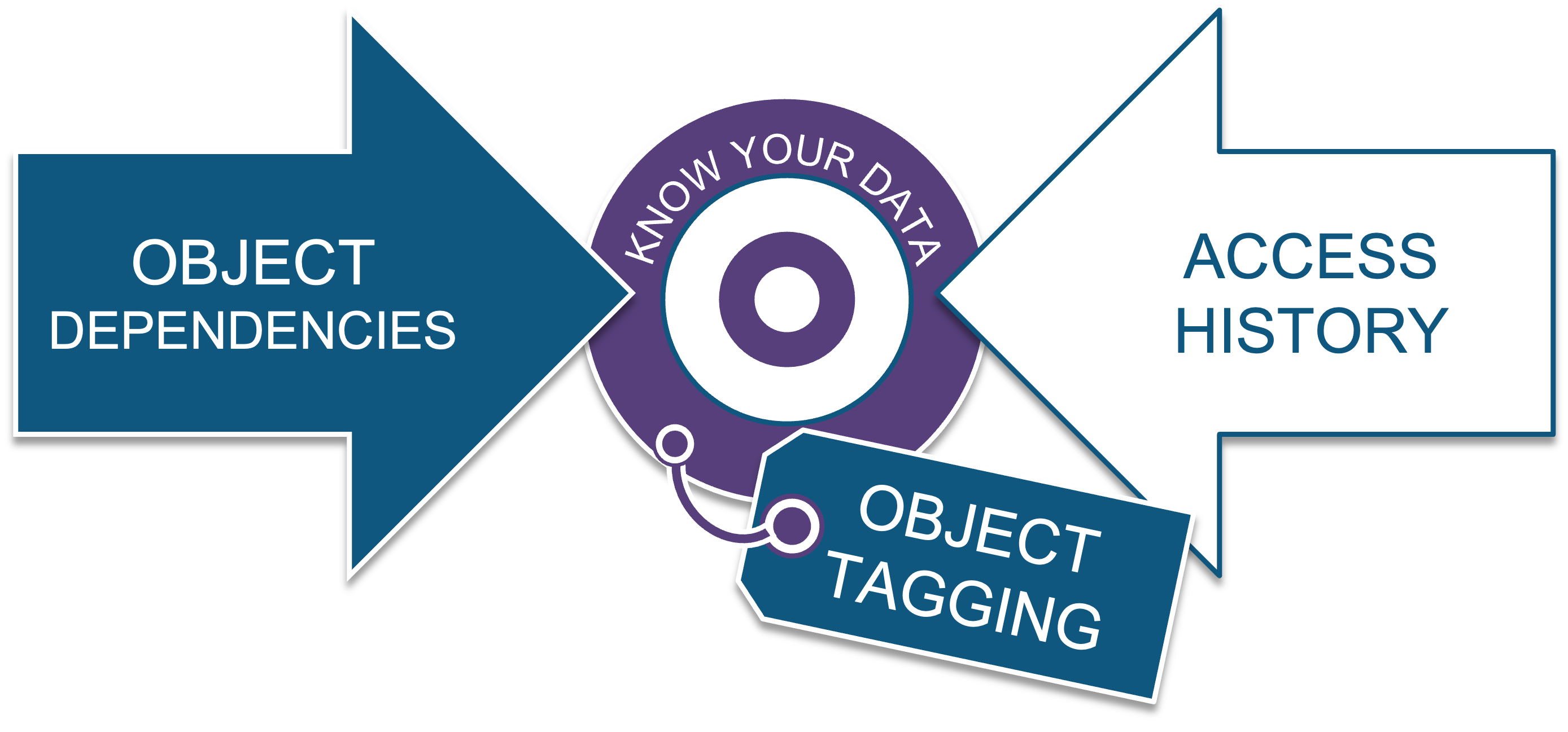
In addition, Snowflake also provides impact analysis and data provenance through:
- Object dependencies: Used primarily for impact analysis, this recursive view is useful for understanding what downstream or upstream objects in a lineage will be affected by any changes you introduce to your data objects.
- Access History: This recursive view tracks every data object accessed by any role, and it also tracks what data objects were created by that access down to the column level, and what policy was in place when the content was accessed.
- Object Tagging: A dynamic method for grouping Snowflake objects into cost-centers and for applying masking policies as well.
In addition to all this, Snowflake provides a robust set of observability views to track all the information you need. These are accessible with account usage and organization usage schemas and within the information schema in every database you create.
Data Vault for data science
“There is no AI without IA” – Seth Earley, AI thought leader
Feature stores are a framework for managing and operationalizing feature data requirements for ML models, and they have overlapping capabilities of a data warehouse. This means you can leverage the same agility, automation, and audit guarantees used in the Data Vault approach on Snowflake, along with your data engineering best practices. Snowflake’s capabilities continue to lead the industry and strive for as little data movement as possible.
Your data science workload can even be augmented or sourced from data providers in Snowflake Marketplace or as direct data shares from your data partners. Not to mention the ever-expanding business cases being supported by managed, connected, or native application frameworks using Snowflake. Combined with Snowflake’s industry-leading standards for data governance and platform security, you can rest assured that your data science model deployment scales at Data Cloud scale.
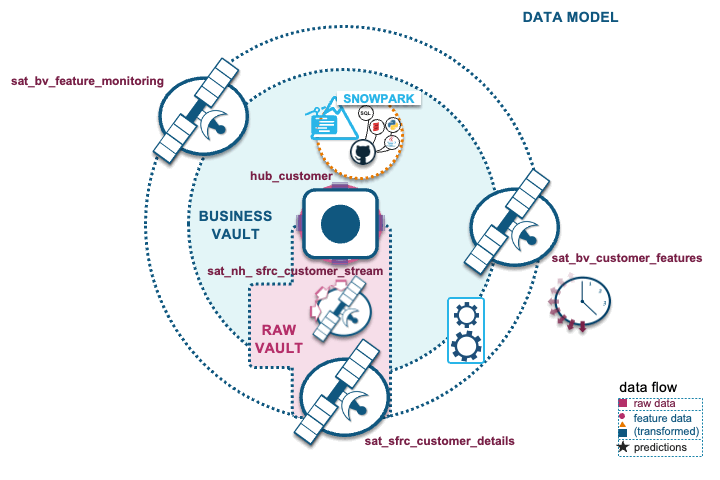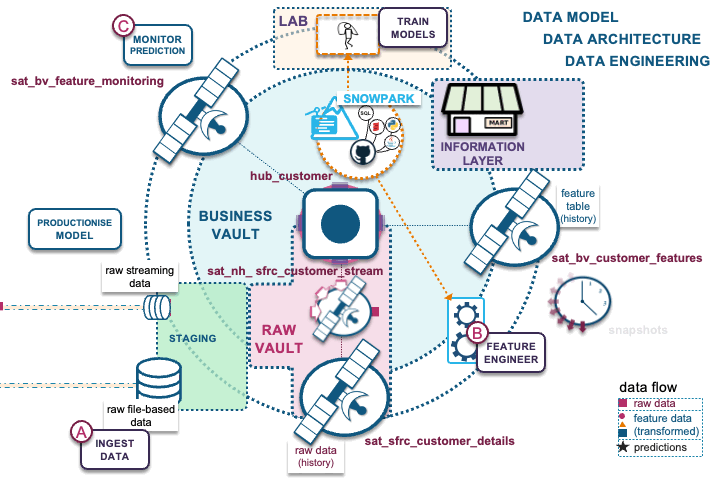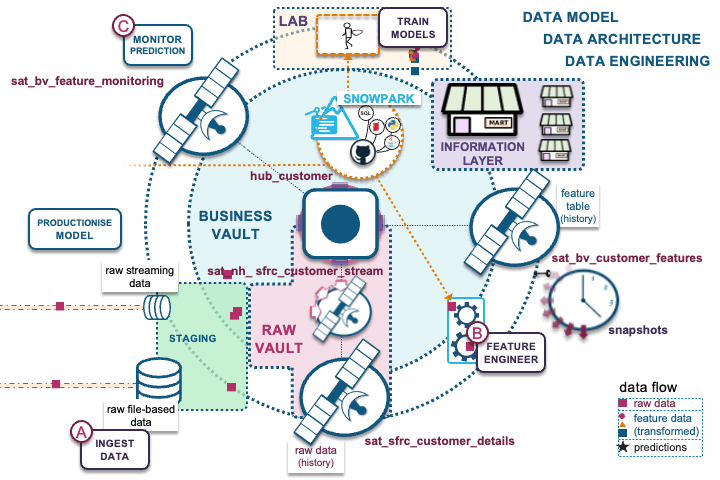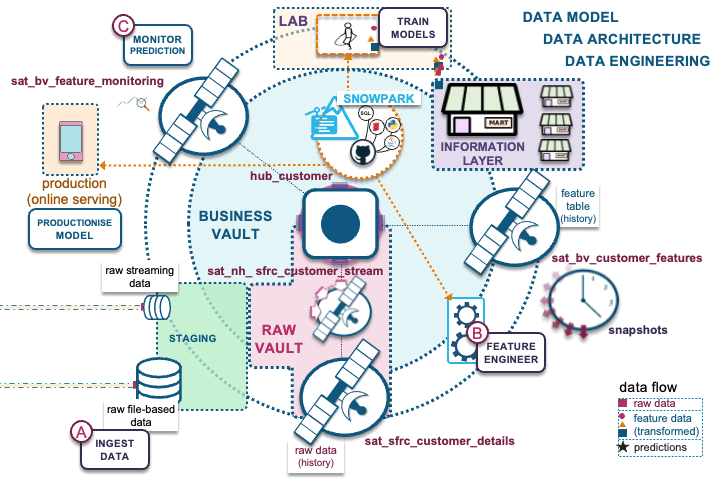
Note that this blog post does not cover the full suite of capabilities of a feature store, or the requirements needed for a full MLOps implementation, but includes the data management components of the Data Vault methodology you can reuse for your feature store on Snowflake.
References
- Data Vault and Domain-Driven Design https://medium.com/snowflake/1-data-vault-and-domain-driven-design-d1f8c5a4ed2
- Ask a Data Scientist: Data Leakage https://insidebigdata.com/2014/11/26/ask-data-scientist-data-leakage/
- The Playbook to Monitor Your Model’s Performance in Production https://arize.com/blog/monitor-your-model-in-production/
- What Is Feature Engineering: Importance, Tools, and Techniques for Machine Learning https://towardsdatascience.com/what-is-feature-engineering-importance-tools-and-techniques-for-machine-learning-2080b0269f10