
Today, Snowflake is announcing the general availability (GA) of the External Tables feature.
Snowflake launched the External Tables feature for public preview at the Snowflake Summit in June 2019. It is one of the key features of the data lake workload in the Snowflake Data Cloud.
External Tables Address Key Data Lake Challenges
External tables were built to address the challenges with data lakes for two primary use cases:
- To augment an existing data lake. Many organizations started using data lakes a few years ago. They have spent a considerable amount of resources designing, implementing, and fine-tuning their data lake architectures on cloud storage services like AWS S3, Azure Data Lake Storage, or Google Cloud Storage. But they love the simplicity and rich functionality of Snowflake, and they want to use Snowflake to augment their existing data lake, rather than replace it. The External Tables feature enables that use case. Customers can use external tables to query the data in their data lake without ingesting it into Snowflake. Customers can also choose to create materialized views on external tables to speed up the query performance significantly.
- Ad-hoc analytics. Customers often use external tables to run ad-hoc queries directly on raw data before ingesting the data into Snowflake. Ad-hoc queries help them evaluate data sets and determine further actions.
Figure 1 shows a sample architecture of using External tables as a query engine to analyze files in an external data lake.
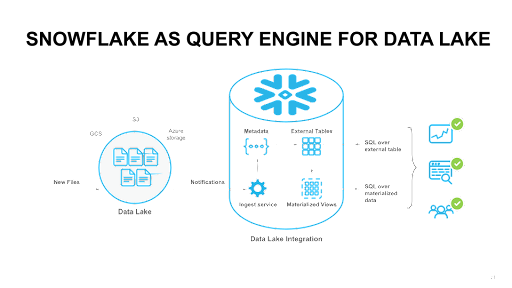
Figure 1: Using external tables and materialized views as a query engine in data architecture
“Snowflake’s external tables and materialized views play a critical role in ARC’s data architecture. Their functionality enables our organization to easily connect our data lake with our products, providing a seamless and performant experience to access the breadth of ARC’s global air travel data,” said Airlines Reporting Corporation’s (ARC) Solutions Architect, Mostafa Ghazi.
Vectorized scanners for parquet files
The External Tables GA comes with a new vectorized scanner for parquet files, which is eight times faster than the previous, non-vectorized parquet scanner. The new vectorized scanner is designed to take advantage of parquet’s columnar file format. We did benchmarking of Snowflake with the previous parquet scanner and the vectorized scanner on TPC DS 10TB data set and the 102 queries that come with it. Tests demonstrated an 8X scan performance improvement and a 2X query performance improvement over the non-vectorized parquet scanner.
Data sharing of external tables
This launch also includes the ability to share external tables. Figure 2 shows a sample data architecture that uses the power of data sharing and materialized views to create a self-service analytics platform.
In this sample architecture, the platform team manages the data lake and the external tables that query the data sets in the data lake. The team shares the external tables with other business units, which in turn can choose to keep them as external or create materialized views for business critical data sets.
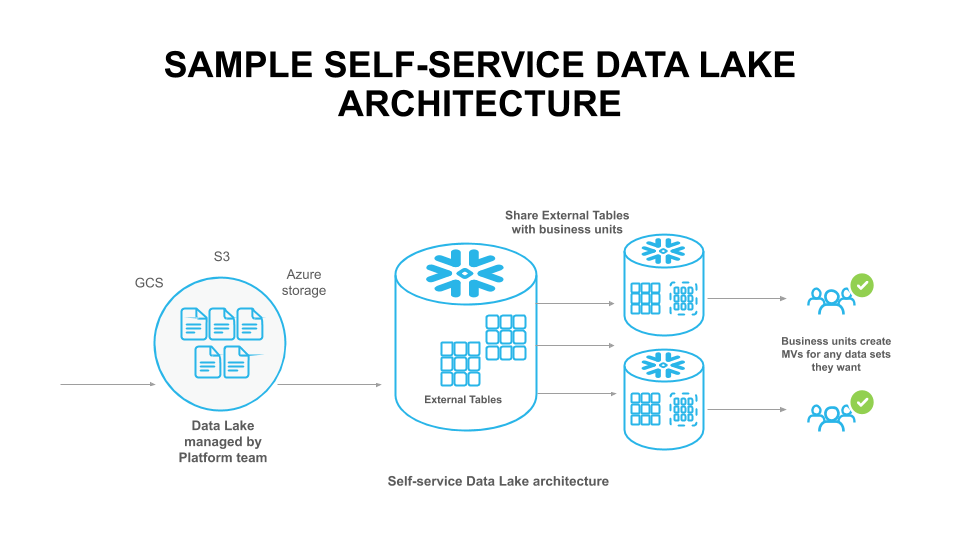
Figure 2: Building a self-service data lake architecture using data sharing of external tables.
“External tables with data sharing allow us to get direct access to data that before was siloed in the data lake. Analytics teams can pick and use any available data directly in Snowflake without having to go through lengthy data movement requests or extra engineering overhead.”said Electronic Arts Data Solutions Architect Ventsislav Petkov.
Customers can also use external tables to build a transformation pipeline for their data lakes. An example of such a pipeline is shown in Demo: How to use Snowflake as a transformation engine.
Streams on External Tables for Data Engineering
This launch also includes the ability to create streams on external tables. Streams and Tasks are powerful building blocks to build data pipelines. Streams track the new file registrations for external tables, so that actions can be taken on newly added files to the data lake. Figure 3 shows a sample data architecture that uses streams on external tables and tasks to build a data engineering pipeline.
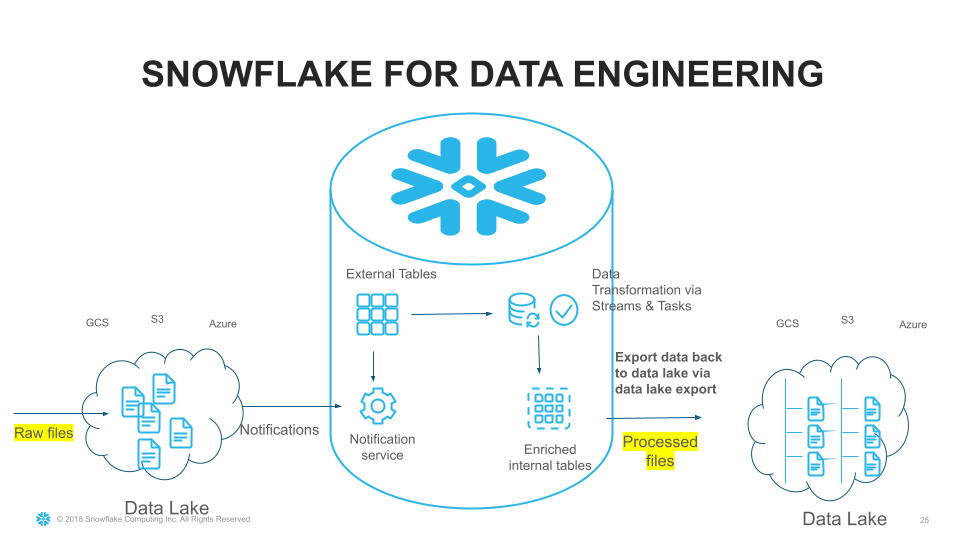
Figure 3: Using Streams on external tables to build data pipelines.
Conclusion
To summarize, organizations can build several use cases and different data lake architectures using external tables. The vectorized scanner has improved the performance significantly. Give External Tables a try today!
Check out the Snowflake Data Cloud Summit to learn more about external tables and how companies like Portland General Electric and Airlines Reporting Corporation leverage them to maximize the utility of their data lakes.