The accessibility of data has changed the way that businesses are run. Data has become essential to decision makers at all levels, and getting access to relevant data is now a top priority within many organizations. This change has created huge demands on those who manage the data itself. Data infrastructures often cannot handle the demands of the large numbers of business users, and the result is often widespread frustration.
The concept of an Enterprise Data Warehouse offers a framework to provide a cleansed and organized view of all critical business data within an organization. However, this concept requires a mechanism to distribute the data efficiently to a wide variety of audiences. Executives most often require a highly summarized version of the data for quick consumption. Analysts want the ability to ‘slice and dice’ the data to find interesting insights. Managers need a filtered view that allows them to track their team’s data in the context of the organization as a whole. Strategists and economists need highly specialized data that can require highly complex algorithms and tools to generate. If one system is to serve the data for all of these audiences, along with numerous others, it must be able to scale to provide access to all of them.
Traditional Data Warehouse architecture has not been able to adequately respond to this demand for data. Many organizations have been forced to move to hybrid architectures in response. OLAP tools and datamarts became commonplace as mechanisms to distribute data to business users. Statisticians and later data scientists often had to create and maintain entirely separate systems to handle data volumes and workloads that would overwhelm the data warehouse. Data is copied repeatedly into a variety of systems and formats in order to make it available to wider audiences. A vice president at a large retail company openly referred to their data warehouse as a data pump that was entirely consumed by the loading of data on one side and the copying of that data out to all sorts of systems on the other side. This also leads to challenges in ensuring there is one vision of the data inside the organization and synchronizing all the siloed data.

During my time working in a business intelligence role for a number of the largest organizations in the world, I encountered all of these problems. While supporting the Mobile Shopping Team at a major online retailer, I had access to a wide variety of powerful tools for delivering data to my coworkers that relied on that data for making key decisions about the business. However coordinating all of these systems so that they produced consistent results across the board was a huge headache. On top of that, many of the resources were shared with other internal teams, which meant that we were regularly competing for access to a limited pool of resources. There were a number of situations where I could not get data that was requested by my VP in a timely manner because other teams had consumed all available resources in the warehouse environment.
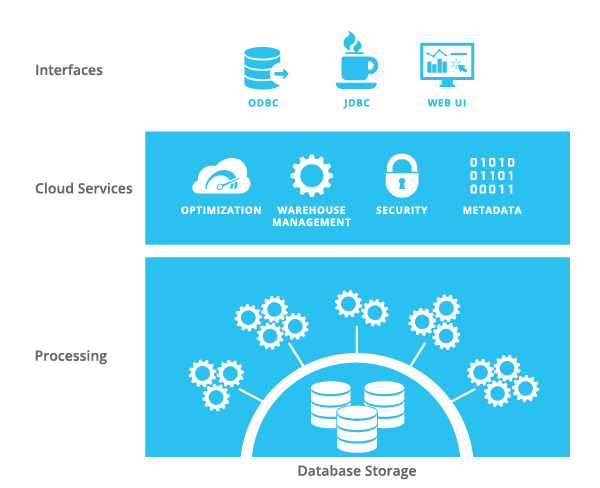
The architects behind Snowflake were all too familiar with these problems, and they came to the conclusion that the situation demanded an entirely new architecture. The rise of cloud computing provided the raw materials: vast, scalable storage completely abstracted from the idea of server hardware or storage arrays and elastic compute. More importantly, this storage is self-replicating, thus automatically creating additional copies of items in storage if they become ‘hot’. This new storage, combined with the availability to leverage nearly unlimited computing power, is at the heart of the multi-cluster shared data architecture that is central to Snowflake’s Elastic Data Warehouse.

At Snowflake, data is stored once, but can be accessed by as many different compute engines as are required to provide responses to any number of requests. Data workers no longer need to focus on building out frameworks to deal with concurrency issues. They can keep all of their data in one system and provide access without having to consider how different groups of users might impact one another. The focus can then be placed where it belongs, on deriving value from the data itself. Thus you can load data and at the same time have multiple groups, each with their own computing resources, query the data. No more waiting for some other groups to free up resources. Your business can now deliver analytics to the various users: executives, analysts, data scientists, and managers, without the environment getting in the way of performance.
As always, keep an eye on our Snowflake-related Twitter feeds (@SnowflakeDB and (@ToddBeauchene) for continuing updates on all the action and activities here at Snowflake Computing.



