
Near real-time analytics on growing volumes of data can provide a key competitive advantage. Seizing that advantage requires making the data available to decision makers and applications in a form suitable for consumption. Snowflake Cloud Data Platform enables organizations to be data-driven so they can capture a competitive advantage, and data pipelines make it much easier to transform data into the most suitable form efficiently.
Snowflake provides a well known cloud data warehouse that has supported efficient, at-scale queries on multiple clouds for many years. But over the last few years, Snowflake has evolved into a broad cloud data platform for processing data and supporting applications. Data pipelines are a key piece of that platform. The Streams and Tasks features enable you to build data pipelines and turn Snowflake into a nimble data transformation engine in addition to a powerful data warehouse.
Today, we are excited to announce the general availability (GA) of the Streams and Tasks for data pipelines on all supported cloud platforms.
Data pipelines are an integral part of your cloud data platform
Many transformations can benefit from the simplicity of using the same tool to handle transactions and queries. A lot of pipelines start small with basic transformations and organically become richer over time. Quicker time to implementation and a native integration with the transaction subsystem can provide a big productivity boost. Snowflake data pipelines use two independent but complementary abstractions of streams and tasks to implement simple data pipelines. This lets you get started faster and allows better integration with external transformation engines and schedulers if needed.
The table stream is a Change Data Capture (CDC) abstraction on a Snowflake table with transactional semantics. You can think of a stream as a bookmark on a table that is updated when used in a transaction so you always know the changes that are not yet processed. You can use a stream for queries just like a table or a view. You can have as many independent bookmarks as you need, and you can use each one in a pipeline (or elsewhere) to ensure that all new data is processed transactionally.
Tasks are schedulable units of execution—a SQL statement or a stored procedure with an attached cron schedule or an interval of execution. You can string together tasks in a tree of dependencies to build your pipeline as shown below. You can run tasks as frequently as every minute to get fine-grained execution and keep up with incoming data as it arrives. In addition, you can select a warehouse of your choice to scale to your processing needs, suspending the warehouse when it’s not used for running tasks. There are no additional costs to use streams and tasks—you are charged credits for the warehouse you use in a task, as you would be for running queries outside tasks.
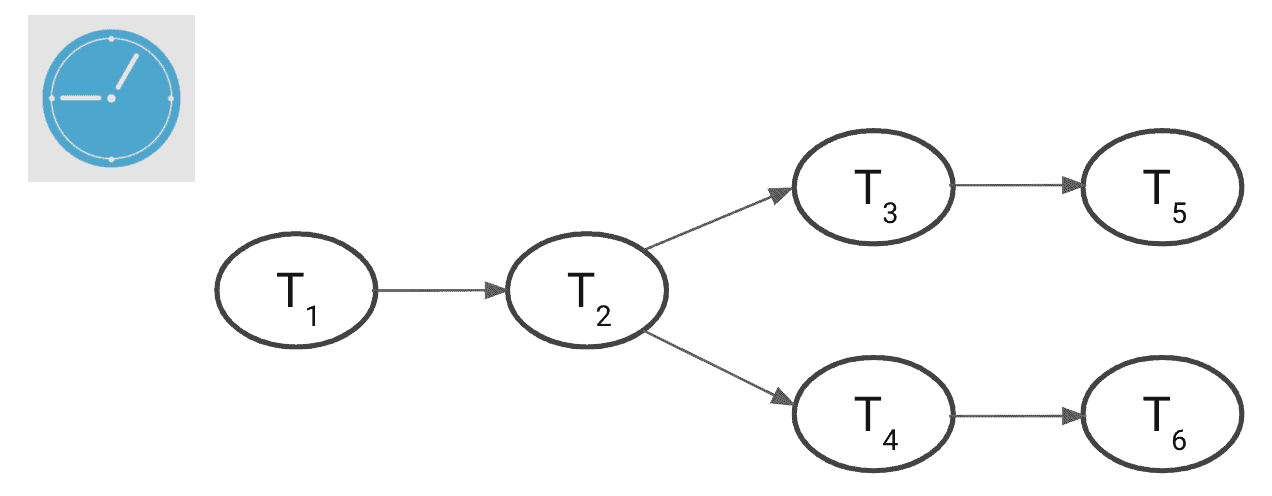
Streams and tasks are completely independent abstractions, but they come together to enable a pipeline of transformations that Snowflake runs on a schedule for you. You can scale this pipeline to match the influx of data and the complexity of transformations while ensuring that all data gets transformed transactionally, even if some executions might fail for various reasons.
Data for the masses
Last year, Snowflake released a public preview of the Streams and Tasks feature. We are gratified that our preview customers trusted us, implementing sophisticated and near-real-time pipelines running over 1.5 million tasks every day for many months. Just in the last 30 days, customers created over 200 thousand streams to process new and changed data. This trust has given us the confidence to move forward with this GA announcement.
”Instead of running hourly batch jobs in Airflow that each processes tens or hundreds of thousands of rows, using Snowflake Tasks, we’re now able to schedule over 5,000 micro-batch jobs an hour that only process a handful of new rows each time they execute. The biggest benefit for us is the reduced latency in our ELT pipeline. Data that used to take one to two hours to import and transform is now available in five minutes“ says Adrian Kreuziger, Senior Software Developer at Convoy.
Simple example
Here is a basic example showing how a stream and a task can be used to merge data from a staging table into a dimension table.
- Data is loaded into the staging table product_stage using COPY, Snowpipe, Snowflake Kafka Connector, or another tool. The loaded data needs to be merged into the dimension table product_dimension using insert for new products and update for new information about existing products. Both come in as inserts in the stage table but need to be turned into upserts (merge) in the dimension table.
- The stream product_stage_delta provides the changes, in this case all insertions.
- The task product_merger runs a merge statement periodically over the changes provided by the stream. This keeps the merge operation separate from ingestion, and it can be done asynchronously while getting transactional semantics for all ingested data. You can add complex business logic by using a stored procedure as the task body instead of the merge statement.
// Data lands here from files/ Kafka create table product_stage ( id int, info variant); // This is the target table for merge create table product_dimension ( id int, info variant); // CDC on staging table // Interested only in inserts; so using append_only optimization create stream product_stage_delta on table product_stage append_only = true; // Periodic merge from staging using CDC. Covers updates & inserts create task product_merger warehouse = product_warehouse schedule = '5 minutes' as merge into product_dimension pd using product_stage_delta delta on pd.id = delta.id when matched then update set pd.info = delta.info when not matched then insert (id, info) values (delta.id, delta.info);
You can enhance the task above to perform more complex business logic, schematize the variant column, or keep multiple dimension tables consistent. Keeping dimension tables up to date is a classic data warehouse use case. During the preview, customers also used streams and tasks to transform IoT data for dashboards and reporting, perform periodic materialization for complex materialized views, clean and prepare data for machine learning training and prediction, perform data masking and data loss prevention, and monitor security continuously.
Build data pipelines in Snowflake today
Many of our customers have already built impressive pipelines. Now others who were looking for GA or just did not have a chance to try these capabilities can also see how quickly they can create their pipelines. You can find the documentation and information on how to get started here.