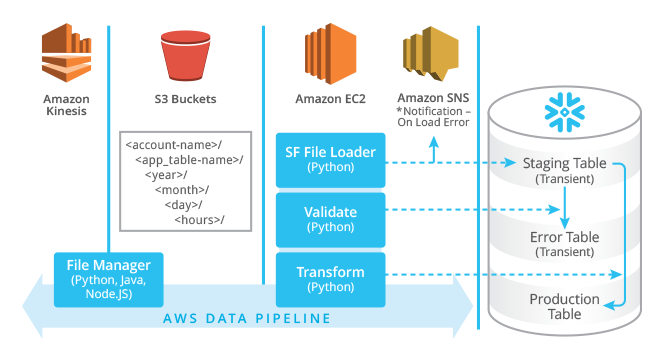
In PART I of this blog post, we discussed some of the architectural decisions for building a streaming data pipeline and how Snowflake can best be used as both your Enterprise Data Warehouse (EDW) and your Big Data platform. Conceptually, you want to set yourself up for analyzing data in near “real-time”, providing your business users with access to data in minutes, instead of the hours or days they are accustomed to. This is what the Lambda Architecture (https://lambda-architecture.net/) attempts to achieve and this is what Snowflake customers love about our platform.
Snowflake provides the best of both worlds, i.e. users can query semi-structured data using SQL while data is being loaded, with no contention and full transactional consistency. If you are like me, you are saying to yourself, “Really?” In short, the answer is a resounding “YES!” So what’s our secret? We take advantage of being the first cloud-native database hosted on AWS and using the S3 file system service’s capabilities to their fullest.
PART II explores the Snowflake COPY command and its powerful options for gradually adding capacity and capability to your data pipeline for error handling and transformation. It also discusses options for validating and transforming data after it’s been loaded.
Snowflake’s COPY Command
The COPY command is extremely feature rich, giving you the flexibility to decide where in the pipeline to handle certain functions or transformations, such as using ELT (Extract/Load/Transform) instead of traditional ETL.
Using the COPY command, data can be loaded from S3 in parallel, enabling loading hundreds of Terabytes (TB) in hours, without compromising near real-time access to data that has been loaded. The COPY command can be executed from the Worksheet tab in the UI, just like any other DDL or DML operation, or programmatically using one of the supported languages, such as Python, Node.js, ODBC, JDBC, or Spark.
Tip: As a best practice, we recommend testing the syntax of your commands through the UI before embedding it in code.
Here are the highlights of the many options that the COPY command provides for managing the loading process end-to-end.
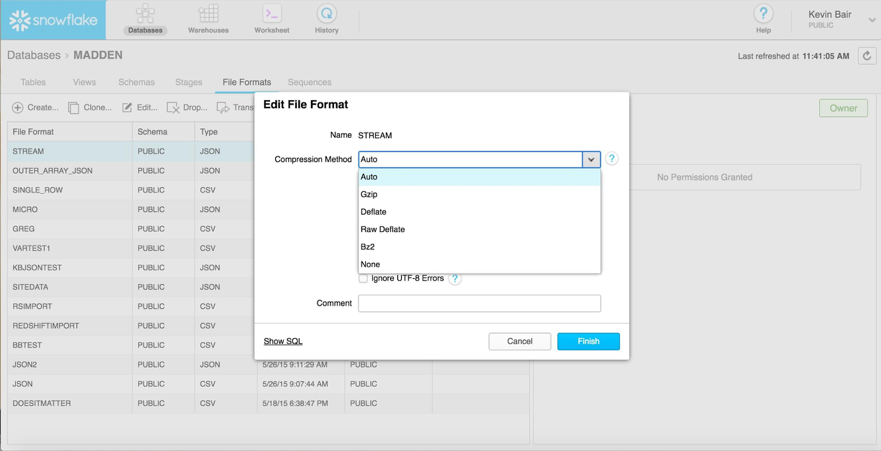
Compression
Because Snowflake uses a columnar Massively Parallel Processing (MPP) implementation, data is compressed for optimized storage and query performance. In addition, data can be loaded from already-compressed files as shown below:
Tip: Design your data-collection application to output files of about 100 MB in size, which will not only give the best storage value, but also optimal query performance based on Snowflake’s underlying architecture.
Parallel Load
Snowflake’s ability to load multiple files in parallel by executing a single COPY command means each virtual warehouse (VW) node can operate simultaneously on multiple files. The design consideration here is whether to create one large file (e.g. multiple GB) or many small files for optimal load performance. The Snowflake COPY command can handle either configuration, but will load the smaller, more numerous files much faster. Smaller files also allow for easier error handling if there is a problem with the data.
Error Handling
COPY command options that should be considered for error handling include:
- Validate before loading: Snowflake allows you to run the COPY command in Validation mode without actually loading the data. It can either return the number of rows that failed or return all errors. This feature is nice for smaller data sets, but has the downside of requiring the command to be executed twice: once for error checking, and then again for the actual load, which could be excessive overhead, depending on your use case.
- Validate on load: The COPY command offers multiple options for controlling behavior in the event of error during the load:
- The simplest strategy is to continue on error, which for some use cases or initial testing purposes is acceptable.
- The next option is to skip the file if any errors occur, or if a specific number of errors occur, or if a specific percentage of the records contain errors. Keep in mind that Snowflake maintains metadata regarding the files that have been loaded and, unless specifically configured to do so, the COPY command won’t load the same file twice into the same table. This allows you to use the same COPY command with the same pattern match over and over again as more files are added into the same directory structure. However, you must remember this when trying to load.
- Lastly, you can abort on error and stop loading completely.
File Cleanup
The COPY command has a parameter setting to automatically purge files that loaded from the S3 staging area upon success or leave them in place for regulatory purposes or long term storage. Most clients chose to retain these files for at least a short period of time. Once the data is validated, you can decide whether to keep it in its current location (i.e. in the staging area), move it to cheaper, long-term storage (such as Amazon Glacier), or delete it completely.
Loading to Production Tables or Staging Tables?
You can choose to load directly into your production table or you can stage your data for post-processing once ingested. There are benefits and trade-offs to both. The simplest and most straightforward implementation would be to have all transformational and error logic built around your production-level tables. Depending on your data volumes, particularly how much you trust the quality of the data, this could work fine. The downside of this approach is flexibility. As you can imagine, you have now set yourself up to let this table (or set of tables) grow forever.
Depending on your use case, if you decide to do transformations, you may find yourself working from extremely large, potentially unclean data sets, which might not be optimal. Most clients start with this method, then transition to the architecture depicted in PART I of this blog. It’s relatively easy to transition any code written to work with staging tables so that it writes smaller chunks of data into production tables instead.
Post-Load Processing
Once data has been loaded using the COPY command, Snowflake supports additional post-processing options.
Dynamic Handling of Semi-structured Data
Most streaming data that our customers load into Snowflake comes as semi-structured data, such as JSON, AVRO, or XML. One of the biggest benefits of using Snowflake for processing this data is not requiring code changes in the data pipeline as the structure of the data changes. Most databases require shredding prior to ingest to put the data into predefined tables, which enables access to it via SQL. We have several customers where their data format changes daily, and prior to Snowflake, the application development team had to prioritize the elements that would be exposed and the parts of the pipeline that would be fixed.
Not any longer with Snowflake!
Our VARIANT data type automatically adapts to allow new elements to be ingested and available right away without changing any of your application code or database schema. Each element becomes an internal sub-column that can be referenced using a dot notation, e.g.:
SELECT COUNT(:) FROM elt_table;
This provides end users instant access to new data as it becomes part of the stream, without having to ask the development team to do new work. AWESOME!
Data Validation
Similar to the Validation mode that can be used for error handling before loading, Snowflake users can tap into the metadata collected for every file loaded. For each COPY command, the VALIDATE table function provides information on the types of errors encountered, the name of the file containing the error, and the line and byte offset of the error, which can be used to analyze malformed data in the stream. A best practice would be to execute this function after each COPY command and save the results into an error table for debugging at a later time, e.g.:
INSERT INTO save_copy_errors SELECT * FROM TABLE(VALIDATE(elt_table, Job_ID => '_LAST'));
Data Transformation
Depending on your use cases, the skill of your end users, the types of analytics you perform, and your query tools, you may want (or need) to transform semi-structured data (including arrays and objects in non-relational structures) into relational tables with regular data types (INTEGER, CHAR, DATE, etc.), including data models using Third Normal Form, Stars, Snowflake, or any kind of schema. Snowflake is a fully-functional, ANSI-compliant RDBMS that doesn’t limit your data model creation. Snowflake’s built-in functionality promotes ELT (Extract/Load/Transform) in favor of traditional ETL or Data Lake architectures that rely on using Hadoop for transformation. These features include:
- Extreme Performance using SQL with semi-structured data: Snowflake automatically shreds semi-structured objects into sub-columns. An added benefit is that each of these columns has statistical metadata captured on ingest; this is used to optimize query performance, similar to regular relational columns. This allows us to deliver improved performance over Hive or other Hadoop/SQL overlay technologies by a factor of 10 to 1000 times. Moreover, you can always improve performance by scaling your VW without reloading data.
- User Defined Function (UDF) Support: If Snowflake does not provide a native function, aggregation or transformation for the operation you wish to perform, you can easily create SQL UDFs and JavaScript UDFs.
- Data Typecasting: Snowflake simplifies data typecasting with both a CAST function and functionally equivalent ‘::’ notation to implicitly convert data types. Special care should be taken when converting timestamps and dates to negate further casting downstream in the pipeline during end-user queries.
Conclusion
Streamlining the data pipeline can have a huge impact on the value of data flowing into your business. End users that used to wait for days to see the results of changes they have made to operational systems will be able to see their results in minutes. Utilizing the power of a cloud-based Massively Parallel Processing RDBMS to do ELT means you don’t have to move TBs of data between your Hadoop infrastructure and your EDW, which results in significantly shortening or eliminating data load windows. The Snowflake Data platform allows you to start small with little complexity and then scale your architecture as the needs of your business change.
I have really only scratched the surface on the capabilities of Snowflake related to processing semi-structured data, so look for more posts as I work with customers on their most challenging Big Data analytic scenarios and please get in touch with any questions! And, as always, make sure to follow our Snowflake-related Twitter feeds (@SnowflakeDB) for all the latest developments and announcements.



