This post highlights some of Snowflake’s advanced functionality and pinpoints key architectural decisions that might be influenced when designing pipelines for ingesting streamed data.
What is Streamed Data?
Streamed data is information that is generated continuously by data sources such as social networks, connected devices, video games, sensors etc. Thus, in the age of social media and the Internet of Things (IOT), streaming architectures for data capture and analysis have become extremely popular. Building these data pipelines to collect semi-structured data from sources such as Facebook, Twitter and LinkedIn requires a platform capable of handling these new constructs and approach to analytics.
Why Snowflake?
Snowflake’s elastic cloud data warehouse is extremely well-suited to handle the volume, variety and velocity challenges of working with Big Data. The prevailing best practice for stream ingestion is the Lambda Architecture (https://lambda-architecture.net/). Snowflake can easily be used as a core component of Lambda, simplifying the architecture and speeding access to data in both the batch layer and the speed layer.
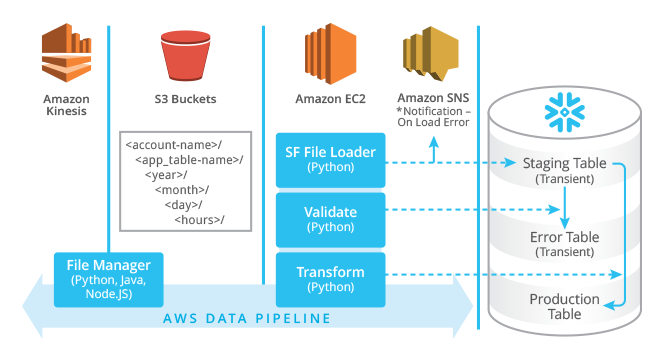
The following diagram provides a high-level view of a data stream ingestion architecture, incorporating both cloud infrastructure and Snowflake elements:
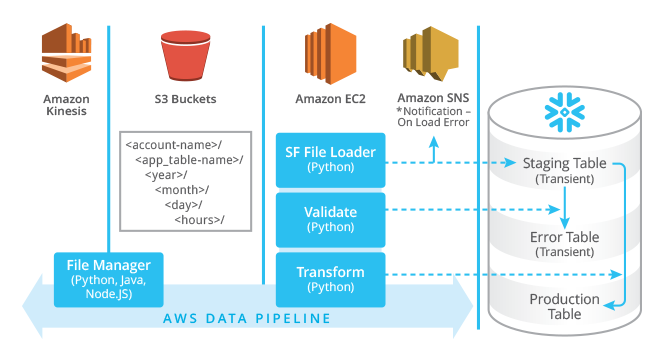
When designing complex architectures, it helps to break the problem into manageable components, so I will divide this discussion into two parts:
- Decisions to make before loading
- Decisions to make about loading (using the COPY command) and post-processing.
This blog post focuses on decisions to make before loading data. A follow-on post will focus on the COPY command and how it handles errors and transformations during loading, as well as a discussion of post-processing options after your data is loaded.
Decisions to Make Before Loading
Snowflake’s Elastic Data Warehouse runs on Amazon’s AWS platform, which offers a wide variety of choices for building your data pipeline. It’s best to start small with a sample data set and a limited number of services, becoming familiar with the nuances of each. One of the biggest benefits of using Snowflake as your Big Data platform is our VARIANT data type implementation for semi-structured data. Due to the variable nature of semi-structured data, new elements are often added to the stream, forcing developers to constantly update their ingest scripts and internal data structures. Snowflake changes this dynamic by automatically shredding these objects into sub-columns on ingest, giving users instant access to the data via SQL (see below for more details).
Programming Language
For streaming applications, choose a language that works well with the cloud platform service (i.e. Snowflake on Amazon AWS) that you will leverage for the following components:
- Data collection (e.g. Kinesis, Firehose, SQS)
- Notification (e.g. SNS)
- Control flow execution (e.g. Data Pipeline, Lambda)
Snowflake supports multiple programming languages, including but not limited to Python, Node.js, ODBC, JDBC, and Spark. All connections into Snowflake use TLS and come through our secure REST API.
File System Directory Structure
Snowflake supports loading directly from Amazon Simple Storage Service (S3) using files of type Avro, JSON, XML and CSV/TSV. Most streaming architectures are designed to write files (either compressed or uncompressed) to a temporary staging area for fault tolerance and manageability (Amazon S3 has some really nice features for moving data around). When setting up S3 buckets and directory structures, consider that the most efficient way to load data into Snowflake is to use micro-batching and the COPY command (more on this in upcoming posts). If you use a directory and file naming convention such as s3://<bucketname>/<projectname>/<tablename>/<year>/<month>/<day>/<hour>, you can use the PATTERN option in the COPY command. The PATTERN option uses regular expressions to match specific files and/or directories to load. By segmenting the data and files by time, data can be loaded in subsets or all at once, depending on your use case.
Tip: Snowflake’s COPY command only loads each file into a table once unless explicitly instructed to reload files. This is a great feature because you can stream your data into the same directory and continue executing the same COPY command over and over again, and only the new files will be loaded. However, as you evolve your load process, don’t abuse this feature. For each COPY command, Snowflake must first get the list of files in the directory to do the matching and, if the list grows too large, the command may spend more time figuring out which files to load than actually loading the data.
Warehouse for Loading
Snowflake has the unique ability to spin up and down compute resources, and the resources can be configured in different sizes. This enables storing and analyzing petabyte-scale data sets. To load or query data, a Virtual Warehouse (VW) must be running and in use within the session. Since Snowflake offers a utility-based pricing model similar to Amazon (i.e. we charge for compute resources by the hour), you will want to optimize your VW for loading based on your use case (i.e. how much data you are loading and how quickly you need access to it). You can bring up or down a VW using SQL or the web user interface. You can also set parameters for auto-suspend and auto-resume. Here is an example command to create and start a VW:
CREATE WAREHOUSE load_warehouse WITH
WAREHOUSE_SIZE = 'MEDIUM'
WAREHOUSE_TYPE = 'STANDARD'
AUTO_SUSPEND = 1800 AUTO_RESUME = TRUE
MIN_CLUSTER_COUNT = 1 MAX_CLUSTER_COUNT = 1;
Tip: Snowflake loads data from files in parallel extremely efficiently, so start with an x-small or small size, and use a single VW for both loading and querying. As your data volumes increase or SLAs for query performance tighten, you can separate out these functions into separate VWs — one for loading, one for querying — and size each for the appropriate workload.
Table Definition
Before loading data into Snowflake, you must define a structure. Since Snowflake is ANSI SQL-compliant, you can execute DDL such as CREATE TABLE AS from within the web interface (in the Worksheet tab) or through the command line interface (snowsql), or you can just use the Database tab in the web interface. There are two key elements to defining a table:
- Table Type
- Table Structure
Table Type
Snowflake supports three table types: permanent, transient, and temporary. The differences between the three are twofold: how long the table persists and how much Time Travel and Fail-safe protection is provided (which contributes to storage cost).
- Temporary tables are just that — they exist for the length of your session. They are typically used as a temporary place to store and act on data while programming. They do not provide any Time Travel or Fail-safe protection so they incur no additional storage footprint beyond the data in the table, which is purged from Snowflake when the session ends.
- Transient tables are often used as staging areas for data that could easily be reloaded if lost or corrupted. Like temporary tables, they provide no Fail-safe protection, but they persist for a day upon deleting, dropping or truncating the table, allowing for Time Travel (https://docs.snowflake.net/manuals/user-guide/data-time-travel.html). Transient tables persist data exactly like permanent tables, except for the Fail-safe aspect.
- Permanent tables are the default type created by the CREATE TABLE command. By default, they provide 1 day of Time Travel and have the added benefit of seven days of Fail-safe protection (https://docs.snowflake.net/manuals/user-guide/data-cdp-storage-costs.html). And, with our Enterprise offering, permanent tables can be configured for up to 90 days of Time Travel.
Table Structure
The structure you chose for your table depends on the type of data you are loading:
- For structured data (CSV/TSV), we highly recommend pre-defining each column/field in your target table with proper data type definition before import. Snowflake provides a File Format object that can help with date conversion, column and row separators, null value definition, etc.
- For semi-structured data (JSON, Avro, XML), define a table with a single column using VARIANT as the data type.
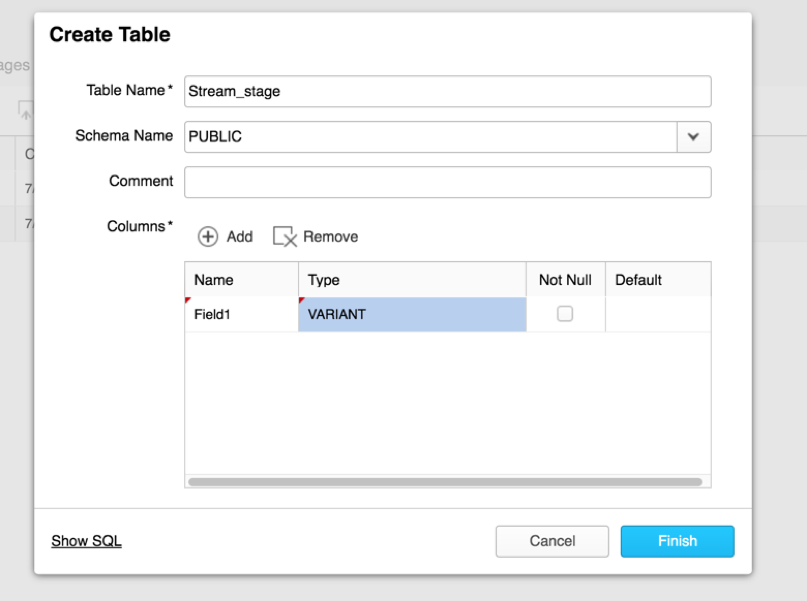
When you load semi-structured data into the VARIANT column, Snowflake automatically shreds each object into a sub-column optimized for query processing and accessible via SQL using dot notation; e.g.:
SELECT COUNT(fieldname:objectname) FROM table;
Conclusion
Ultimately, designing stream architectures and analyzing that data can be simplified based on your architectural decisions and leveraging the platform’s functionality to your advantage. Start small and continue to add capability as your data volumes, data types, and use cases expand.
In PART II of this blog series (coming soon), we will look at how data is loaded into Snowflake and what decisions should be made regarding in-database transformations, such as moving from the traditional ETL model to ELT, which can be much more efficient for big data processing.
And, as always, keep watching this blog site and our Snowflake-related Twitter feed (@SnowflakeDB) for more useful information and up-to-the-minute news about Snowflake Computing.