
Welcome to the third blog post in our series highlighting Snowflake’s data ingestion capabilities, covering the latest on Snowpipe Streaming (currently in public preview) and how streaming ingestion can accelerate data engineering on Snowflake. In Part 1, we discussed usage and best practices of file-based data ingestion options with COPY and Snowpipe. In Part 2, we went over ingestion capabilities with Snowflake’s Connector for Kafka using Snowpipe file-based ingestion.
What is Snowpipe Streaming?
Snowpipe Streaming is our latest data ingestion method offering high-throughput, low-latency streaming data ingestion at a low cost. Rows are streamed from data sources directly into Snowflake tables, allowing for faster, more efficient data pipelines. There is no intermediary step in cloud storage before data is made available in Snowflake; this reduces architectural complexity and reduces end-to-end latency. You also get new functionality such as exactly-once delivery, ordered ingestion, and error handling with dead-letter queue (DLQ) support.
This new method of streaming data ingestion is enabled by our Snowflake Ingest Java SDK and our Snowflake Connector for Kafka, which leverages Snowpipe Streaming’s API to ingest rows with a high degree of parallelism for scalable throughput and low latency. As a native streaming data ingestion offering to Snowflake’s Data Cloud, Snowpipe Streaming simplifies the creation of streaming data pipelines with sub-5 second median latencies, ordered insertions of rows, and serverless scalability to support throughputs of gigabytes per second. Data engineers and developers will no longer need to stitch together different systems and tools to work with real-time streaming and batch data in one single system.
Experimentation testing
We’ve talked about the benefits and capabilities of Snowpipe Streaming, so let’s prove it with the following experiment. In the last part of our blog series, we talked about Kafka, a distributed event streaming platform that enables any volume of data at near real-time latency. Let’s continue that story with an experiment on streaming workload cost and latency using our Snowflake Connector for Kafka to ingest data from Kafka topics into Snowflake tables.
New since our last post, our Kafka connector now supports two different ingestion methods configurable by the snowflake.ingestion.method property:
- SNOWPIPE (default)
- SNOWPIPE_STREAMING
The default ingestion method for Kafka connector uses Snowpipe’s REST API behind the scenes for buffered record-to-file ingestion, and has been available for almost five years with hundreds of customers ingesting petabytes of data into Snowflake.
Our newest ingestion method for Kafka connector uses our recently announced Snowpipe Streaming API to ingest rows directly into Snowflake tables. Since Snowpipe Streaming is in public preview, this also applies to the Snowpipe Streaming ingestion method for Kafka. This means it is a great opportunity to test, integrate, and provide feedback for its capabilities, as many of our partners and customers are currently doing.
Test infrastructure setup
To set up this experiment, we sized our AWS compute instances generously to reduce the amount of infrastructure work to test varying streaming loads from the trickle to flood throughput scenarios. Note that the below infrastructure was only temporarily set up for a limited amount of time specifically for this test and is not optimized. The below instance types and storage sizes are not an explicit requirement or recommendation for using Kafka or achieving similar performance.
Note: As always, it is recommended that the instance types and configurations for your own scenarios be tested and optimized for your specific business requirements and budget.
- To generate sample data and constant load, we have a “Load” EC2 instance running Pepper-box for JMeter to produce sample data rows averaging about 1.8 KB each for constant throughput load.
- Instance type: c4.8xlarge with 50 GiB EBS
- Next we have our “Kafka Cluster” EC2 instance, which is where Kafka is being run on Docker containers with 1 Zookeeper node and 3 Kafka brokers.
- Instance type: r4.8xlarge with 500 GiB EBS
- Lastly we have the “Kafka Connect” EC2 instance, which is running our Snowflake Kafka Connector version 1.9.1, bringing data from Kafka into Snowflake.
- Instance type: c6a.16xlarge with 800 GiB EBS
With our test infrastructure now ready, we set our Kafka configuration properties to be constant for each run, and only the snowflake.ingestion.method will change between Snowpipe or Snowpipe Streaming.
Kafka Configuration Properties (see definitions in our documentation)
- buffer.flush.time: 10 seconds
- buffer.count.records: 1000000
- buffer.flush.size: 700 MB
- tasks.max: 16
- Topic partition count: 16
Test results
Each test was run for 15 minutes through our Kafka connector with ingestion method set to Snowpipe Streaming and Snowpipe at varying load throughput rates of 1 MB/s, 10 MB/s, and 100 MB/s.

Given that the configuration between the two ingestion methods was the same, we can see that
Snowpipe Streaming is at least 50% more cost effective than Snowpipe in a like-for-like comparison of streaming data ingestion with our Snowflake Connector for Kafka.
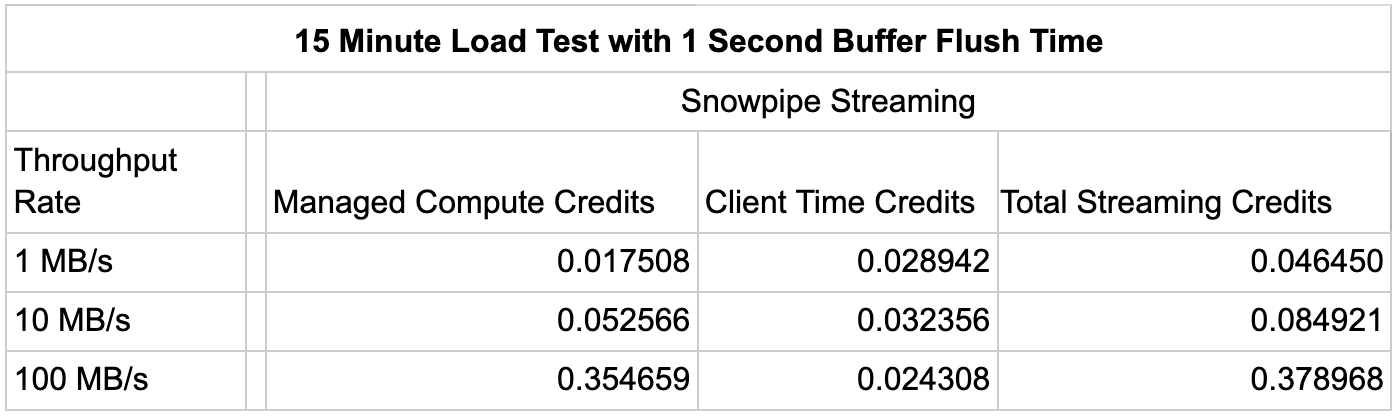
In the prior test, we didn’t highlight the key benefit of Snowpipe Streaming, which is speed. Tests for the same throughput rates were completed, but in this case with a 1 second buffer flush time; a scenario that is not supported by Snowpipe’s minimum buffer flush of 10 seconds.
Based on these benchmarks, for the 100 MB/s throughput rate scenario, Snowpipe Streaming is able to increase speed by up to 10X while credit usage only increased by roughly 5%.
Considerations and best practices
Snowpipe Streaming is a more cost-effective data ingestion method compared to Snowpipe, specifically for offering high-throughput, low-latency streaming data ingestion based on our benchmarks at a low cost. If you are currently using the latest version of our Snowflake Connector for Kafka, it is a simple configuration change to switch your ingestion method from Snowpipe to Snowpipe Streaming to reap the benefits, as we have seen from the above experiment. Of course, it is recommended that you use the above results as guidance for your own tests as you integrate Snowpipe Streaming into your near real-time applications and Kafka workloads.
Keep in mind that Snowpipe Streaming is currently in public preview, so we recommend you use this time to test out its capabilities as we prepare to confidently support production workloads once we move to general availability, expected later this year.
As mentioned in previous blog posts, there are many approaches to data ingestion, but the best practice is to reduce complexity while achieving your business requirements. Batch and Streaming ingestion can work together to provide the simplest and most cost effective solution to your data pipelines. Streaming ingestion is not meant to replace file-based ingestion, but rather to augment it for data loading scenarios that better fit your business needs. For most batch scenarios, ingesting large files using COPY or Snowpipe Auto-Ingest provides a performant and efficient mechanism for moving bulk data to Snowflake. For streaming scenarios where rows can be sent from applications or event streaming platforms like Kafka, using Snowpipe Streaming enables low-latency ingestion directly into Snowflake tables at low cost. Consider your data generation sources and latency requirements to leverage both batch and streaming ingestion to reduce complexity and cost.


