
The Complexity of Data Engineering
Data engineering is a critical aspect for data management. The complexity is twofold. First, often multiple systems and solutions are used together, making the data pipeline architecture rigid and overly complicated. One of the key reasons is that data engineering is a collaborative effort across teams. Data analysts may prefer using SQL and GUI-based tools, data scientists love to work with their notebooks and Python to prepare data, and tech-savvy data engineers and developers need to tackle complex code and programming constructs. To make it all work, data often needs to travel across all these different systems, complicating data pipelines and architecture even more and also jeopardizing security and governance.
Second, managing and working with data processing infrastructure traditionally requires significant manual effort and maintenance overhead. As a result, data engineers are spread thin and spend a majority of time maintaining and fixing pipelines.
Enter Snowpark and Java Functions
Snowflake started its journey to the Data Cloud by completely transforming data warehousing by building a reliable, secure, performant, and scalable data-processing system from the ground up—in the cloud—and delivered it as managed services so the infrastructure complexity is taken care of. That has set the tone for what modern data engineering can look like, especially for the SQL users. Now with Snowpark and Java user-defined functions, currently in public preview (UDFs), we are opening up the Data Cloud with data programmability and extensibility to the non-SQL users, so they can benefit from the same performance, scalability, and ease of use, seamlessly and all in a single platform.
Snowpark is a new developer experience Snowflake, recently introduced at Snowflake Summit in June, that brings deeply integrated DataFrame-style programming to the languages developers like to use, starting with Scala. Java Functions are also available within this experience, further extending what you’re able to do with Snowflake. Snowpark and Java UDFs are designed to make building complex data pipelines a breeze and to allow developers to interact with Snowflake directly without moving data.
Accelerating Data Engineering with Partners through Snowpark
At Snowflake Summit, we showed demos and example use cases, and shared the excitement from our partners in our extended ecosystem. Now, let’s take a deeper look at some of the complex data engineering use cases that can be tackled through the Snowpark Accelerated Program’s partners.
Delivering trusted data with Talend
Your analytics capability is only as good as the quality of your data. For many, data quality has been a top concern. Now, users can perform a health check on their data within Snowflake using Talend Data Trust Score™. In Talend’s demo, a full scan of a table is done and the semantic analysis is returned, and then a Talend Data Trust Score is calculated. Typically, in the past, all that data would have to be extracted and the analysis would have to be run in another system. That is challenging, especially with large volumes of data, and moving the data introduces not only security risks, but also the risk of failed analysis jobs if the processing application runs out of resources. Snowpark and Java UDFs have alleviated these struggles, because the processing happens right inside of Snowflake. Talend’s semantic analyzer is then pushed to Snowflake as a Java UDF, and then Snowpark is used to execute queries and orchestrate the entire process.
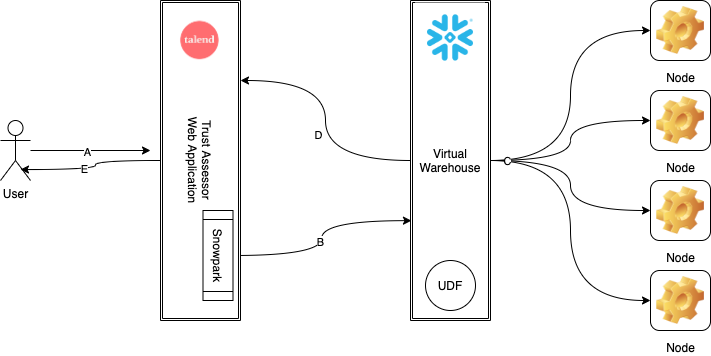
Talend uses Snowpark and Java UDFs to assess health and quality of data
Optimizing DataOps with the StreamSets engine for Snowpark (in preview)
The StreamSets engine for Snowpark will build on top of Snowpark to enable both the expressiveness and flexibility of Snowpark’s multi-language support as well as the simplicity of Data Cloud operations. With this new tool, data engineers will be able to go beyond SQL to express powerful data pipeline logic with the StreamSets DataOps Platform. Utilizing Scala or Java through an intuitive graphical interface, they can choose no code, or they can drop in code when they want. The StreamSets engine for Snowpark will provide all the benefits of the StreamSets DataOps Platform with built-in monitoring and orchestration of complex data pipelines at scale, in the cloud with no additional hardware required.
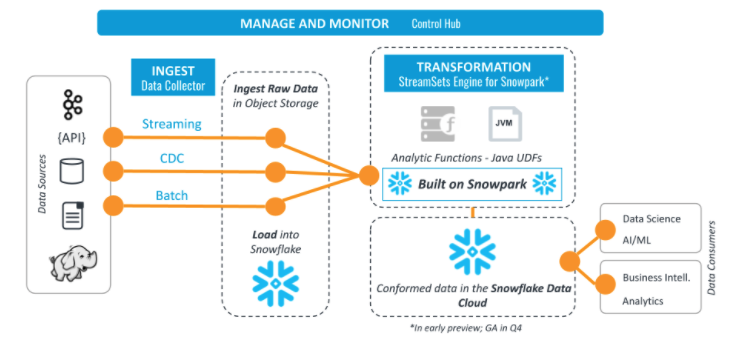
StreamSets’ end-to-end data ingestion and ELT for Snowflake
Powerful data integration and automated orchestration with Rivery
Using Snowpark’s expanded programming capabilities, Rivery customers can unlock new dimensions of their data. Now customers can run SQL, Scala code, and Java UDFs on Snowflake all in parallel, directly inside Rivery. Rivery’s Snowpark integration also simplifies data operations by centralizing data workflows and eliminating superfluous data systems. Rivery customers can also embed Snowpark’s functionality in automated data workflows. Rivery’s Logic Rivers engine combines data ingestion and data transformation into a single automated workflow. Now, Logic Rivers can ingest data from any data source; execute transformations via SQL, Scala, or Java UDFs; and initiate other logic steps including reverse ETL, within a preset automated flow. Logic Rivers, with the power of Snowpark, offers completely automated data orchestration.
Read this Rivery blog, which has a sentiment analysis demo, to learn more about the integration.
Over 50 partners have joined us in the Snowpark Accelerated Program across data engineering, data science, and governance use cases. Snowflake partners Matillion, Informatica, DataOps.Live, and many more are delivering exciting integrations with Snowpark. You can learn more about their use cases here.
The Future with Data Programmability
Snowpark and Java UDFs are now available in public preview, but we are only at the beginning of this journey to data programmability. As mentioned in the summit session What’s New: Extensibility in Snowflake, more improvement features are in the works to deliver an optimized developer experience with Snowflake. You can also do a test-run with this step-by-step lab guide. Give it a try and join the Snowpark discussion group to share what use cases you have.