
Organizations trust Snowflake with their sensitive data, such as their customers’ personal information. Ensuring that this information is governed properly is critical. First, organizations must know what data they have, where it is, and who has access to it. Data classification helps organizations solve this challenge. However, organizations struggle to classify their data because they rely on slow, error-prone, and manual processes or third-party tools that are more than they need, too expensive, and require additional management. While others just lock the data down if they suspect that it contains sensitive information which removes the ability to analyze the data to gain insights and meet their customers’ needs. Snowflake’s Data Classification alleviates these issues by natively classifying personal information that may be considered sensitive, removing manual processes or dependence on a third-party tool. Additionally, it integrates with the suite of Snowflake’s native governance features so that data can be unlocked to reveal customer insights in a controlled and governed manner, which helps organizations win the trust of their customers while meeting their needs.
Today, we are excited to announce that Data Classification is now available in public preview. Data Classification analyzes columns in structured data for personal information that may be considered sensitive and provides customers with a set of predefined Snowflake System Tags to help classify this data. Together with Snowflake’s other governance features, organizations can make sure that their customers’ personal information is properly governed. Snowflake’s classification is built into the platform; therefore, no extra cost or the need to manage additional tools. It enables organizations to know their data, speeding up the process and unlocking the analytical value in a controlled and governed way. Once classified using Snowflake’s Data Classification, organizations can easily run queries defined in INFORMATION_SCHEMA to search for this data, protect it with role-based policies, and audit access through Access History, which are all part of Snowflake’s suite of native data governance features.
“Snowflake’s Data Classification helps us more reliably manage PII data across our entire Data Platform!»
— Eric Jalbert, Senior Data Infrastructure Engineer, HomeX
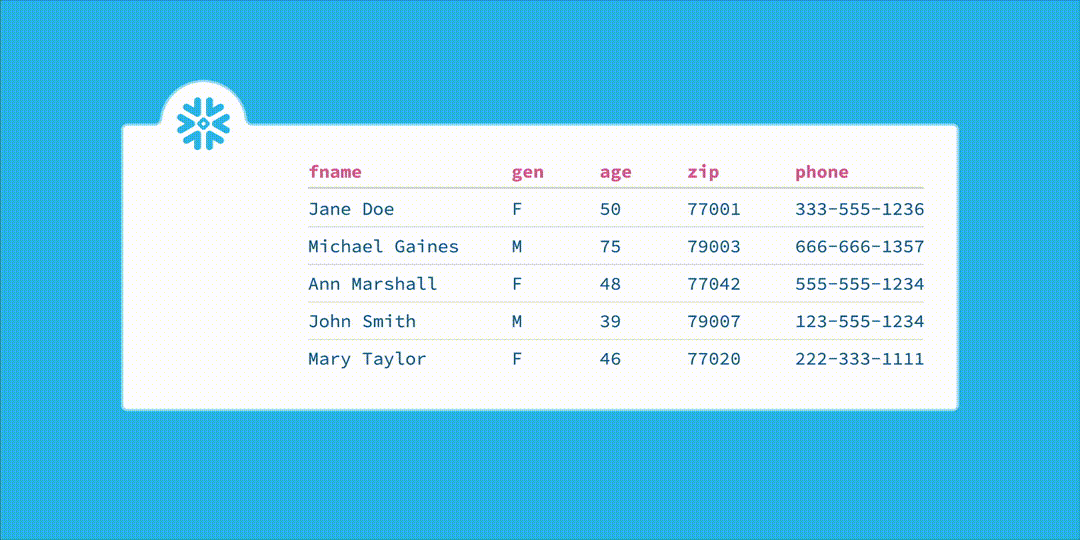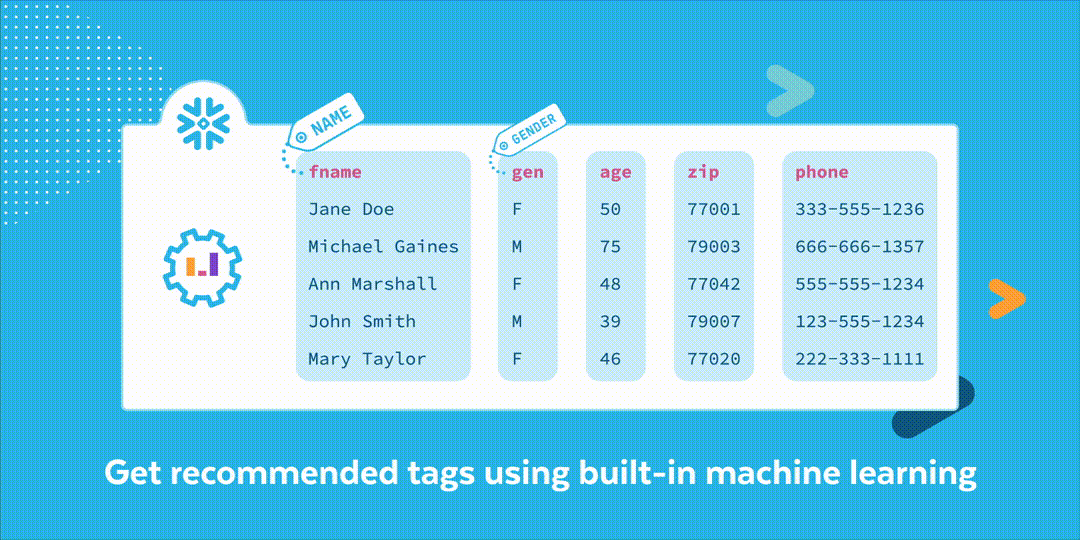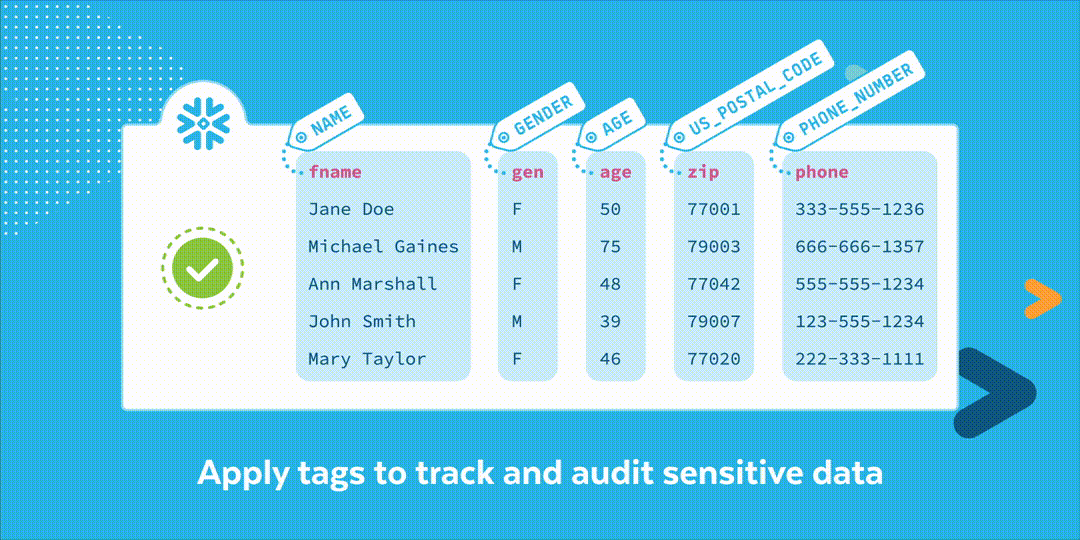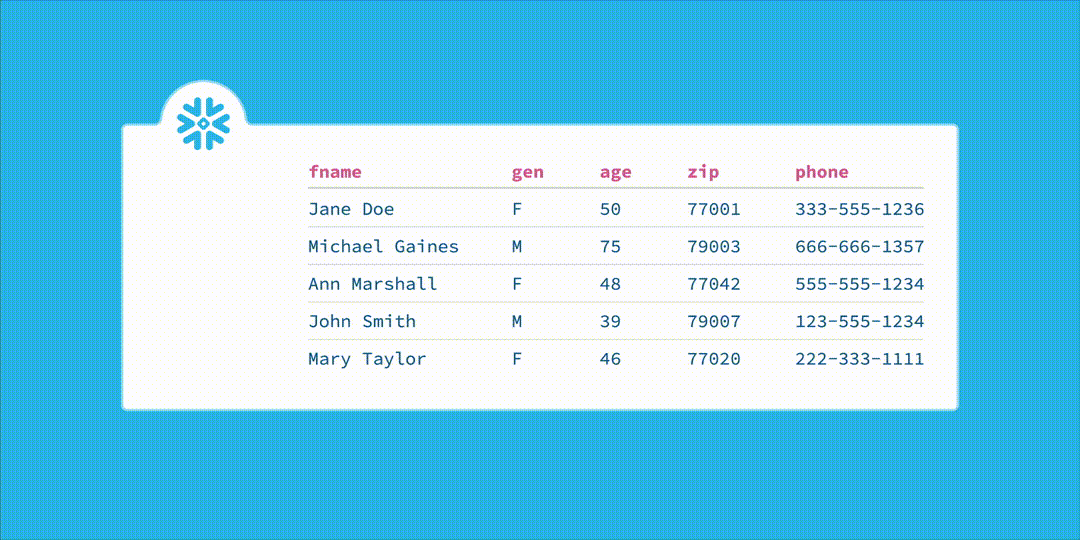
How It Works
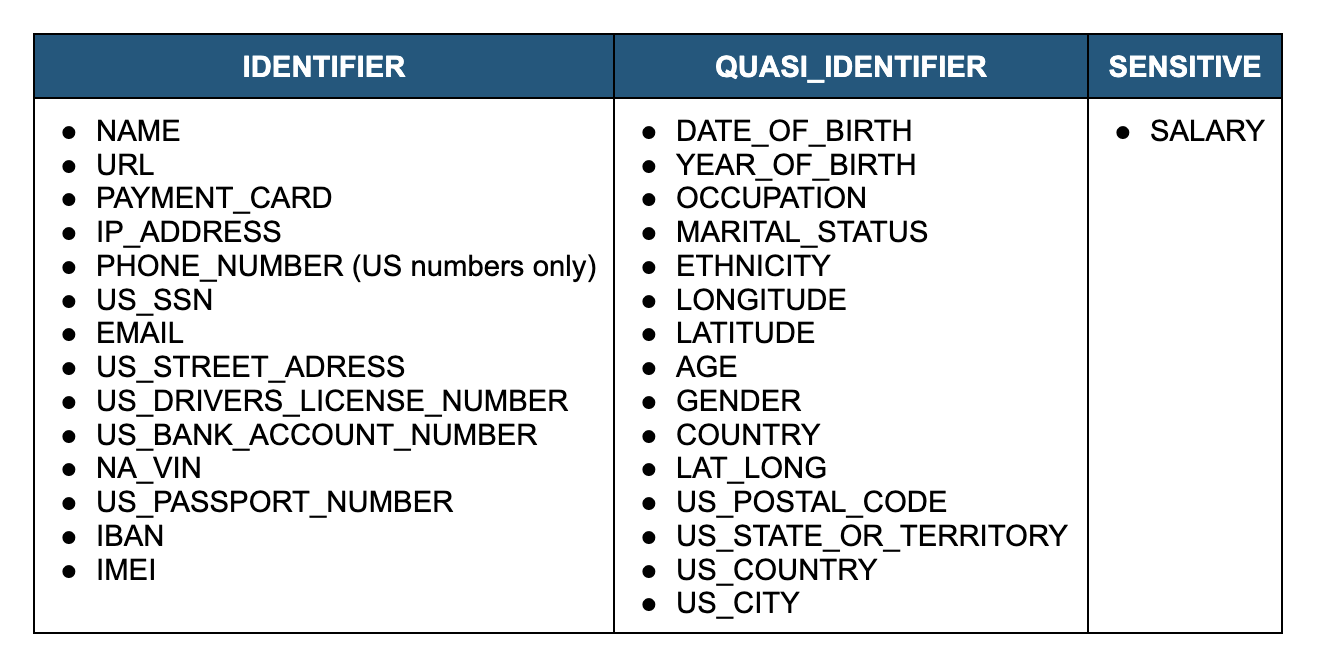
Data Classification analyzes the contents and metadata of columns in a table and then feeds that information into a pre-built machine learning model to help determine the appropriate categories of personal information that may be considered sensitive, requiring more protection or limited access, and applies the results as System Tags. Snowflake will continue to add more categories giving customers more functionality with little additional input. But what is personal information that may be considered sensitive? It is any information that can be connected to an individual, the level of sensitivity can vary depending upon the data and potential harm. There are four general categories that it can be grouped into:
- Direct identifiers, which are attributes that are unique to an individual such as name, and phone number
- Quasi-identifiers, which are identifying in combination, such as age joined with gender and ZIP code
- Transactions and spatiotemporal patterns such as credit card purchases or ride share data
- Sensitive attributes, which are not identifying but are information that individuals don’t want to disclose such as disease status
Snowflake classification only focuses on direct identifiers, quasi-identifiers, and sensitive attributes.
Once a table has been analyzed, values for the System Tags are returned. System Tags are object tags defined by Snowflake and made available in the Snowflake database share. Classification uses two tags: semantic_category and privacy_category. Semantic category relates to what the cells of a column contain; examples include name, gender, age, phone number, and email. Privacy category relates to what kind of personal information the column contains such as identifier, quasi-identifier, and sensitive.
Classification also reports probability and alternates. Probability is the likelihood that the classification is correct and alternates lists of other potential matches if a dominant match is not found. Users can review the results and decide to apply the tags using a system-defined stored procedure. The values of these tags are constrained to the set of Snowflake-supported categories and because these are just Snowflake-defined object tags, all the functionality associated with object tags, such as the Tag_References and Tags view in Account Usage, also applies to these System Tags.
Once the data is classified, organizations can then set up policies, such as Snowflake’s Dynamic Data Masking, to make sure that only the people who need to have access are allowed. Access can be audited by querying the Account Usage view Access_History. For GDPR data deletion use cases, organizations can query the Account Usage view Tag_References to find objects with a specific column such as email, for example, to find all instances of where email may be in their data and then delete the email provided.
Example: Identifying and Protecting Customer PII Data
To demonstrate how Data Classification works, we’ll use a fictitious retailer called StyleMeUp. StyleMeUp has many sensitive fields about its own customers that it has just loaded into Snowflake.
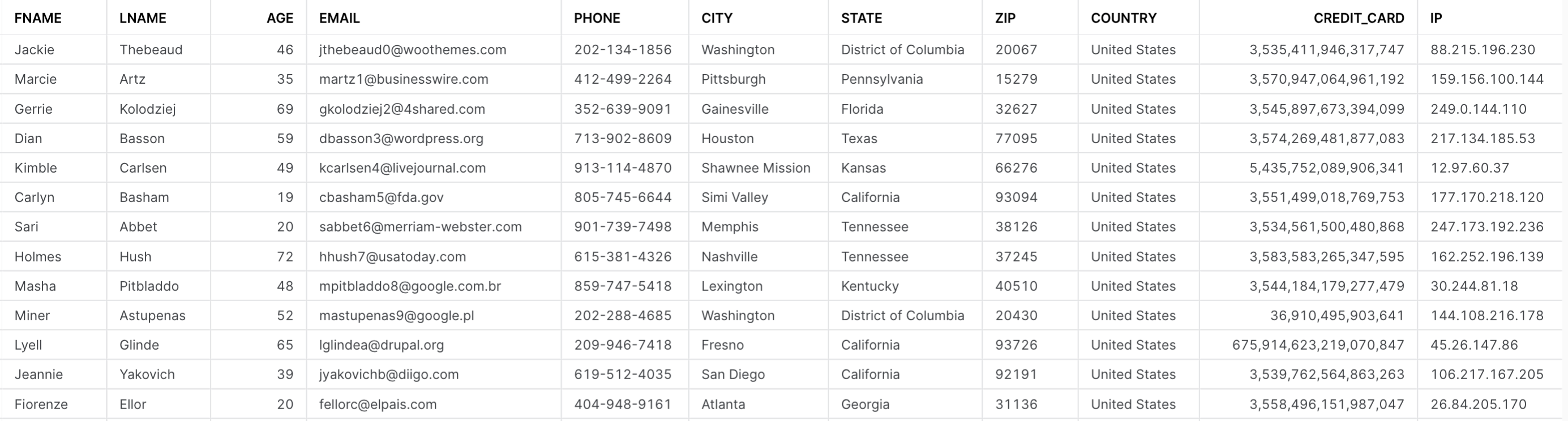
StyleMeUp wants to make sure that this data is properly governed and only the right people have access to the fields they need. For example, the billing department needs to know the name, address, and credit card number of StyleMeUp customers but nothing else. First, StyleMeUp needs to know what information it has; therefore, it uses Snowflake’s Data Classification.
By using the following command, StyleMeUp receives back the suggested values for the System Tags on each column:
SELECT EXTRACT_SEMANTIC_CATEGORIES('CUSTOMER_INFO');The result comes back in just a few seconds JSON formatted:
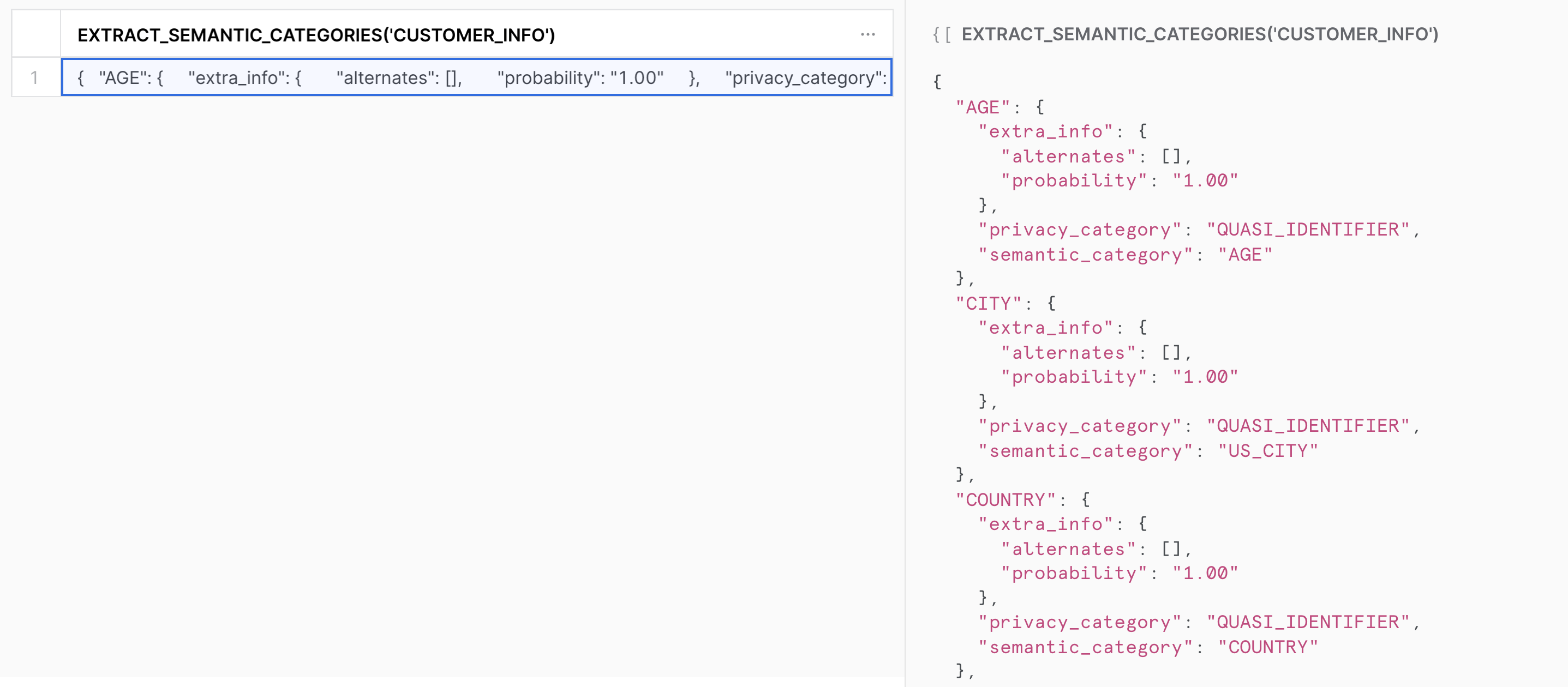
The results are reviewed and accepted; therefore, the System Tags, semantic_category and privacy_category are applied with the values for each column shown above by using the following command:
CALL ASSOCIATE_SEMANTIC_CATEGORY_TAGS('CUSTOMER_INFO',
EXTRACT_SEMANTIC_CATEGORIES('CUSTOMER_INFO'));Now, StyleMeUp can query the Tag_References view to see what columns are in the CUSTOMER_INFO table:
SELECT * FROM SNOWFLAKE.ACCOUNT_USAGE.TAG_REFERENCES
WHERE OBJECT_NAME = 'CUSTOMER_INFO';StyleMeUp will set up masking policies on this table so that the billing department can only see the FNAME, LNAME, CITY, STATE, ZIP, COUNTRY, and CREDIT_CARD columns unmasked.
ALTER TABLE CUSTOMER_INFO ALTER COLUMN AGE SET MASKING POLICY
AGE_MASK;
ALTER TABLE CUSTOMER_INFO ALTER COLUMN EMAIL SET MASKING POLICY
EMAIL_MASK;
ALTER TABLE CUSTOMER_INFO ALTER COLUMN PHONE SET MASKING POLICY
PHONE_MASK;
ALTER TABLE CUSTOMER_INFO ALTER COLUMN IP SET MASKING POLICY
IP_MASK;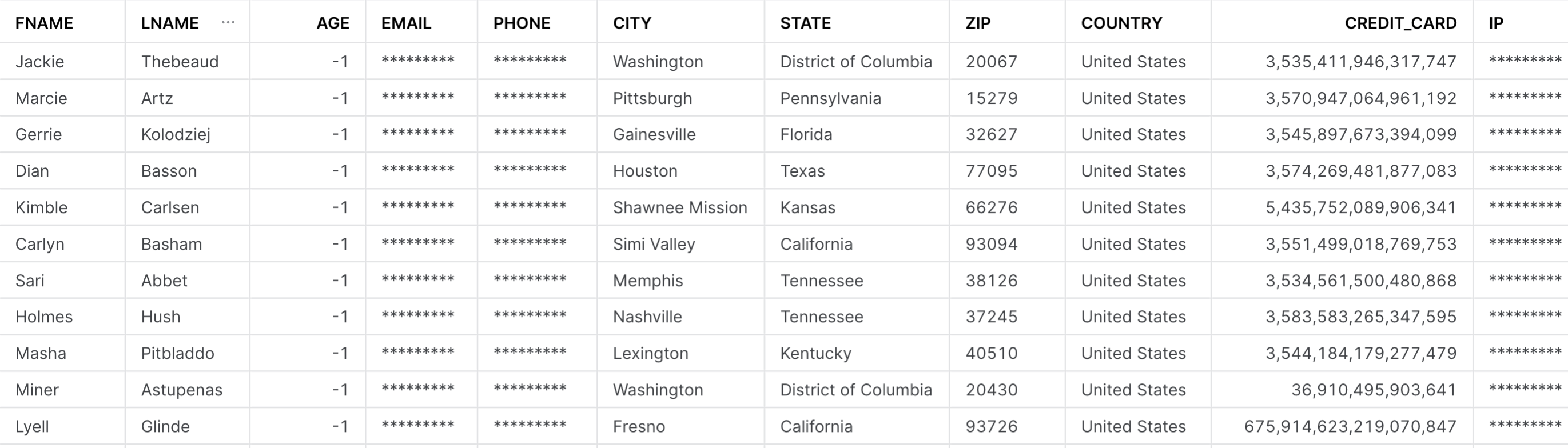
Classification also helps make finding personal information easier, which can assist in satisfying GDPR data deletion requests. For example, StyleMeUp has received a request from one of its customers to delete their data along with the following email address: [email protected]
StyleMeUp can query the Tag_References view to find all tables that contain email.
SELECT * FROM SNOWFLAKE.ACCOUNT_USAGE.TAG_REFERENCES
WHERE TAG_VALUE = 'EMAIL';
They find one table CUSTOMER_INFO that has a column classified as EMAIL. They can then delete the requested information from the table by using the following:
DELETE FROM CUSTOMER_INFO WHERE EMAIL = '[email protected]';Get Started Today
Try out Data Classification along with many of Snowflake’s native governance features by following along with this quickstart guide, which walks you through step-by-step how to process and protect PII data with Snowflake. You can also find product documentation here.