
“If you build it, they will come,” the legend says. Therefore, we submit that a key metric of success for a data initiative is the measure of data utilization. We want our data platform to be user friendly so our users will, well, use it.
Over the years, as we’ve watched teams begin their data warehouse journeys, we’ve seen them focus on data acquisition to “get the data” but forget to think about access control. Then, as data from the warehouse is gleefully exposed to users, word of this new source of data begins to echo throughout the organization. New stakeholders are engaged and new demands surface. Soon, stakeholders start providing feedback on data sensitivity and who should—or shouldn’t—see certain information. As these new restrictions surface, one or all of the following may result:
- Data mart proliferation: New data marts are created and targeted at specific user groups but have essentially the same data, just different columns or rows hidden.
- Visualization explosion: When user access is embedded within the visualization, the number of visualizations almost certainly expands out of control, often exponentially.
- Access control churn: As the organization evolves, regulations come and go, and as users’ access rights change, the maintenance workload grows. Keeping up with that change becomes a nightmare for data engineers, DBAs, and report and application developers.
So if you’re just starting your data warehouse journey, consider centralized, fine-grained user access control from the very first step. Access control should be architected and defined well before you land the first data or write your first query, and absolutely before any data is presented to stakeholders.
Below I’ve defined a few access control options and recommendations to consider.
Learn more about data access control and why infoSecur is built on Snowflake: watch our Powered by Snowflake conversation with Michael Magalsky, founder of infoSecur.
Where to control user access?
First, let’s make sure we all have the same definitions for authentication and authorization. Authentication is the process or processes that ensure the person requesting access is indeed who they say they are. Authorization is the metadata that defines what a given individual, group, or role is allowed to see. For the purposes of this post, I’m making the following assumptions:
- Something else takes care of authentication. Whether it’s the operating system, Active Directory, OKTA, or some combination of the many identity and access management tools available, the data architecture defers responsibility for validating if the access requestor is who they say they are.
- Authorization, however, is absolutely the responsibility of the data warehouse architecture. It is a key feature and should not be overly complicated. Aim for simplicity, consistency, and ease of management in your solution.
A modern data architecture
This diagram depicts the core components of a modern data architecture that we’ll be discussing in this blog post: Source, Staging, Data Warehouse, Presentation, and Visualization layers.
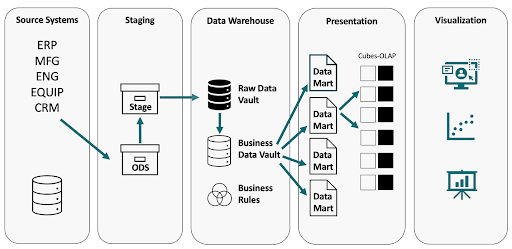
Drag along from the data source
Ideally, as we pull data from the various source systems, we’d include the information that defines how data is accessed within. It’s been our experience that the applications that create data sources each have their own access control mechanism, and they are not consistent. And don’t waste a data engineer’s time trying to decipher each tool’s security mechanism to replicate each application’s access control metadata into a common data store—no one has that kind of time available.
Plus, a benefit of a data warehouse is integrating data from various sources to provide end-to-end, correlated metrics and insights. A stakeholder’s day-to-day operational access may be constrained to just the CRM, but they need access to ERP for that end-to-end visualization. You don’t want one tool’s focused data access rules constraining a stakeholder. Nor do you want the opposite, where the access control of a source system results in unnecessary data visibility. Users need access based only on their need to know.
At the data warehouse, data lake or data matrix
Regardless of what you call it, the modern data architecture is a repository that holds the source of truth for downstream processes. Here is where we often embed business rules, define dimensions, and hold metadata.
Applying access rules within data sets could significantly increase the complexity of your data architecture. Think about the combinations and permutations of data sets across your organization, people’s roles, and the data they need access to. It’s exponentially complex! Chaos ensues and security breaks down. Database administrators are forced to choose between risk and staff effectiveness.
At presentation: Persistent, secured data marts
In this case the data pipeline is periodically creating data marts for stakeholder consumption. The schedule can be anything you want: hourly, daily, weekly—you get to define it. (We’ll leave the trade-offs for another discussion.)
In this case, as each data mart is created, the rules of access control are applied. Each data mart would have access rules embedded within. Having “standalone,” “access-aware” data sets seems attractive at the start, but there are a few things to consider:
- How often do you build a data mart?
- How frequently is it accessed?
- How frequently do access rules change?
- How often do new employees join the organization, change roles, or simply request access?
You could be creating an overly static situation where a stakeholder’s role has changed but the data set was created weeks prior. Another common issue is data set proliferation, where we create data sets for specific user groups or, in the worst-case scenario, individuals. This has the potential of creating a data pipeline nightmare where compute resources are tasked with ever more frequent data mart builds to ensure access rules are up to date within all data marts. And, your team has to keep track of all those data marts. It’s something that grows exponentially as users, roles, and reports grow—along with varying privacy and access governance use cases. Chaos almost always results.
At presentation: Virtual, secured data marts
Using this approach, a data set is created when the stakeholder requests data. At query time the access rules are joined with the data request, in real time, thereby presenting the most up-to-date data to the stakeholder with access control policies applied.
This is how infoSecur works. The enabling principle is data access policies managed in metadata and applied consistently at the database layer through virtualized data marts.
- Policies are managed in structured data via the infoSecur UI or API.
- Multi-purpose views are automatically generated from the policy and data platform metadata.
- The multi-purpose InfoSecur views perform a join between the data set and access metadata policies at query time.
- The database optimizer uses an efficient query plan to quickly return just the right data to the users.
- infoSecur provides a simplified, familiar query mechanism for end users. Using standard ANSI-SQL SELECT * statements, they are served only the data they are privileged to see.
At visualization
Many organizations take their initial stab at security by building filters and obfuscations into the business intelligence (BI) layer. Concerns with this approach include:
- BI developers are often confused by security requirements that are better understood and implemented elsewhere in the organization.
- Consistency cannot be controlled because the implementation occurs by many team members operating at different skill levels with varying degrees of understanding of security requirements.
- Change is inevitable, and there is nothing more painful than changing reports (manually) when security requirements change.
Get your data architecture in order
There are many places across the modern data architecture to enforce access control. Our recommendation is to leverage virtual, secured data marts at query time. The key enabling principle is data access policies managed in metadata and applied consistently through virtualized data marts. Whether you choose to use infoSecur or another option, you’ll save yourself considerable time over the life of your data warehouse.
This alternative simplifies the queries stakeholders or report writers use to a simple SELECT *. This approach is resilient to changing requirements, regulations, roles, and responsibilities. The policies are enforced just-in-time during the query using both the most up-to-date access rules and the freshest warehouse data.
infoSecur addresses the complex problem of user access control by enabling an organization to create a centralized source of access control metadata that is then available across the organization. The application of metadata through a simple join ensures only the right data is presented based on the access rights of the individual making the request.
The infoSecur application is built using Snowflake’s Native Application Framework, currently in private preview, which enables application developers to build applications using Snowflake core functionalities, globally distribute them on Snowflake Marketplace, and deploy them within a customer’s Snowflake account.
Find out more about infoSecur at www.info-secur.com or by checking out the native app (currently in private preview) in Snowflake Marketplace. To learn more about the Powered by Snowflake program, visit www.snowflake.com/en/data-cloud/powered-by-snowflake/.

