
Snowflake is happy to announce, in preview today, the availability of data masking policies that enhance column-level security in Snowflake Cloud Data Platform. Masking policies help with managing and querying PII, PHI, and other types of sensitive data. The policies allow authorized users to view sensitive data in plain text while preventing unauthorized users from viewing the data completely or at various levels of redaction. Masking includes many obfuscation techniques such as partially masked, fully masked, hashed, encrypted, or replaced with tokenized values.
Electronic Arts is one of the early access customers using this feature for HR analytics workloads. Read this how-to post by Electronic Arts’ Chief BI Architect, Vlad Valeyev, for further details.
“Most data platforms fall short of protecting sensitive data against superusers with admin rights, forcing such data to be kept in a physical silo, accessible only by few. Snowflake’s new Dynamic Data Masking feature combined with the existing Secure View features addresses this challenge with just a few lines of code. No changes are required to the rest of the business logic while keeping the data secure and accessible for self-service analytics.”
—Vlad Valeyev, Chief BI Architect, Electronic Arts.
How Is This Solution Different from Using Secure Views?
Many customers use secure views in Snowflake to manage sensitive data by entirely hiding sensitive columns from unauthorized users or masking them using user-defined functions (UDFs). Although this approach works for some use cases, it doesn’t solve the following problems.
- Object owners (secure view owners) and users with privileged roles still have access to the data in sensitive columns.
- Data loaded in pre-tokenized form cannot be de-tokenized at query time.
- The additional secure views and BI dashboards built atop them (in some cases, thousands of them) add management burden.
Snowflake is a customer-obsessed company. We heard your feedback and are happy to announce the solution to the problems mentioned above and more through the introduction of data masking policies.
Use-Case Scenarios
Masking policies can be used in the following two scenarios:
Dynamic data masking: Sensitive data in plain text is loaded into Snowflake, and it is dynamically masked/encrypted at the time of query for unauthorized users, as shown in Figure 1.
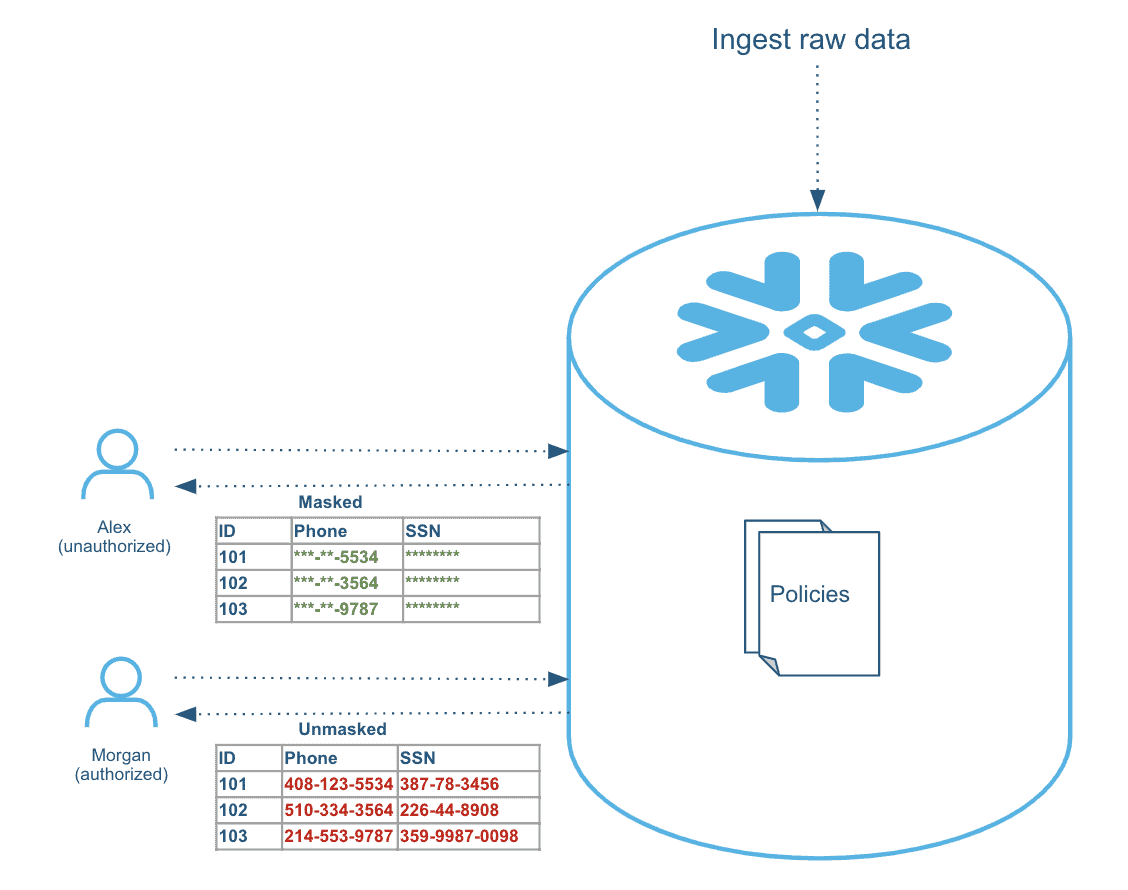
Figure 1: Example of dynamic data masking.
External tokenization: Sensitive data is tokenized/encrypted externally using partner solutions or in-house customer-developed solutions before it is loaded into Snowflake. Then, at query time, the data is de-tokenized/decrypted for authorized users through masking policies that call the external tokenization service using external functions. See Figure 2. Multiple partners have integrated their solutions with Snowflake to provide this functionality.
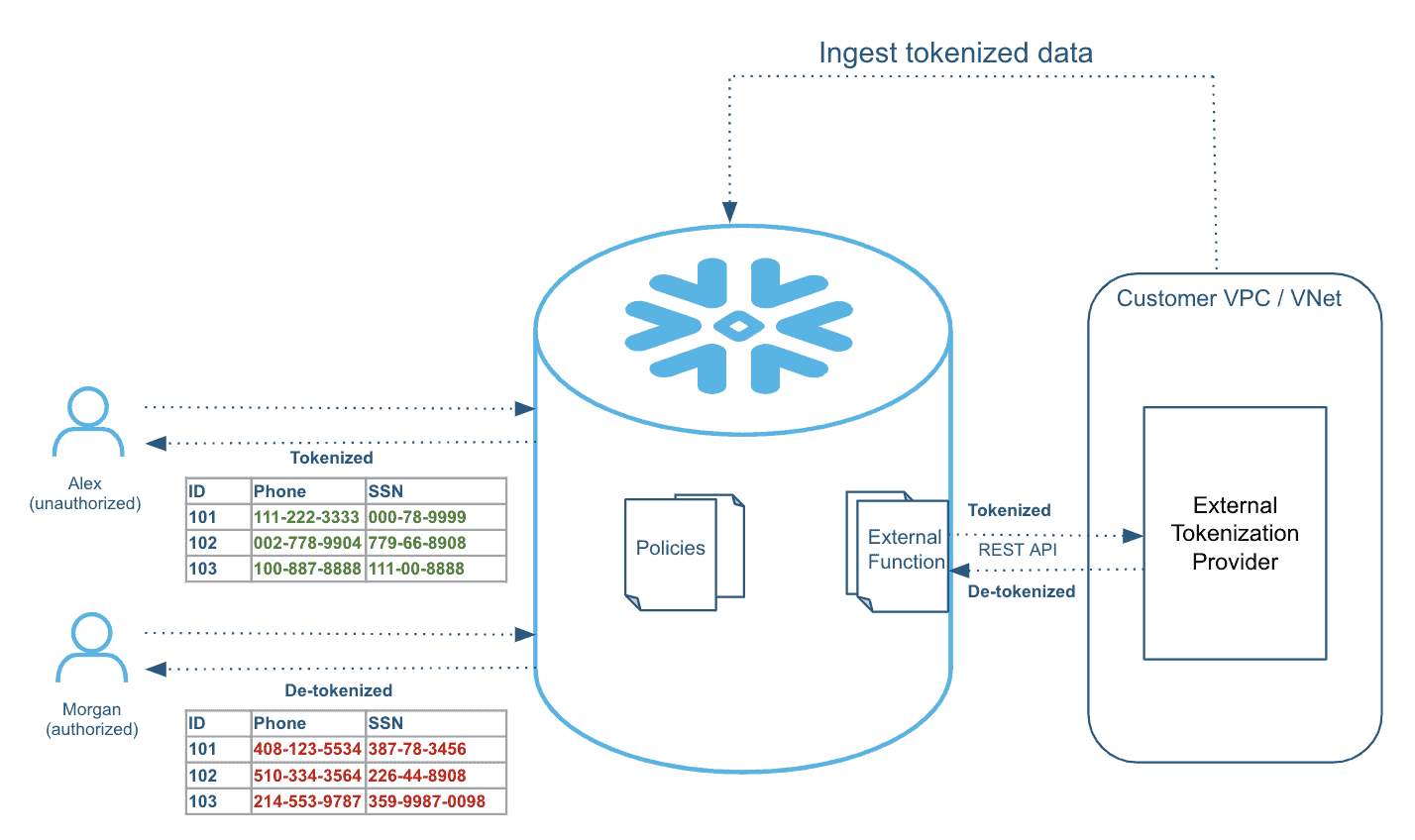
Figure 2: Example of external tokenization.
Using Data Masking Policies
There are just three steps to using masking policies:
- Define a masking policy
- Apply the policy to one or more columns
- Query the data
Because a masking policy can be applied to multiple columns across tables and views in multiple databases and schemas (see Figure 3), you can update a masking algorithm and access rules centrally, and the changes will be applied immediately to all the columns where this policy is applied.
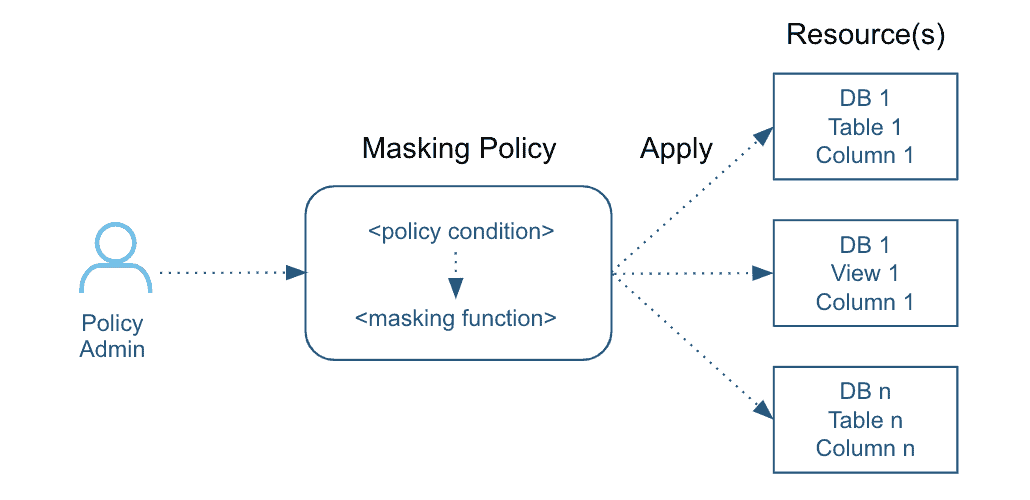
Figure 3: Example masking policy that is applied to multiple columns across tables and views.
MASKING POLICY is a new object in Snowflake that captures the conditions and functions to use when specific conditions are met, as shown in Figure 4.

Figure 4: Specifying conditions for when a masking policy is applied.
In Figure 4, users with the current_role() of PII_ROLE in the session are authorized to view the raw data, and users with the SUPPORT role can view partially masked data (such as the domain part of an email), while the rest of the users will see “***MASKED***” when the email_mask policy is applied to a sensitive column.
This policy-based approach, in conjunction with role-based access control (RBAC), allows you to prevent even table/view owners and users with privileged roles from viewing sensitive data.
Here are some more masking policy examples to help you get a better understanding of how masking policies can be used for various scenarios.

New Built-In Context Functions
To help define various policy conditions, Snowflake is introducing four new built-in context functions:
- is_role_in_session(<name>) Use this function to check whether a given role is part of the current session. It compares not just the current_role() but also all the child roles that are part of the current_role() hierarchy.
- invoker_role() This function returns the executing role of the current execution context. Imagine there’s a masking policy applied to a table column that uses invoker_role() in the policy condition. When a user queries the view created on the table, the invoker_role() function returns the “view owner role” as the table is being executed in the view execution context.
- is_granted_to_invoker_role(<name>) This function checks whether the given role matches with the invoker_role() or any of its child roles in the role hierarchy.
- invoker_share() This function is for use in data sharing scenarios where the provider wants to share sensitive data with the data consumers.
Runtime Query Execution
The best part of the data masking solution is that the end users simply query the data without knowing whether the masking policy is set on the column or not. Snowflake transparently rewrites the query at runtime wherever it finds a column with a masking policy attached. For authorized users, query results return sensitive data in plain-text, while for unauthorized users sensitive data is masked, encrypted, or tokenized.
Below are a few examples of a query submitted by a user and the query executed after Snowflake rewrites the query automatically.

The rewrite is performed in all places where the protected column is present in the query, such as in “projections”, “where” clauses, “join” predicates, “group by” statements, or “order by” statements.
If you want to selectively rewrite a query so that “join” predicates are not rewritten, you can create a view and apply policies to the view columns instead of the original table.
When views are executed, Snowflake performs nested policy execution starting with the base table and proceeds up the view chain, as shown in Figure 5.
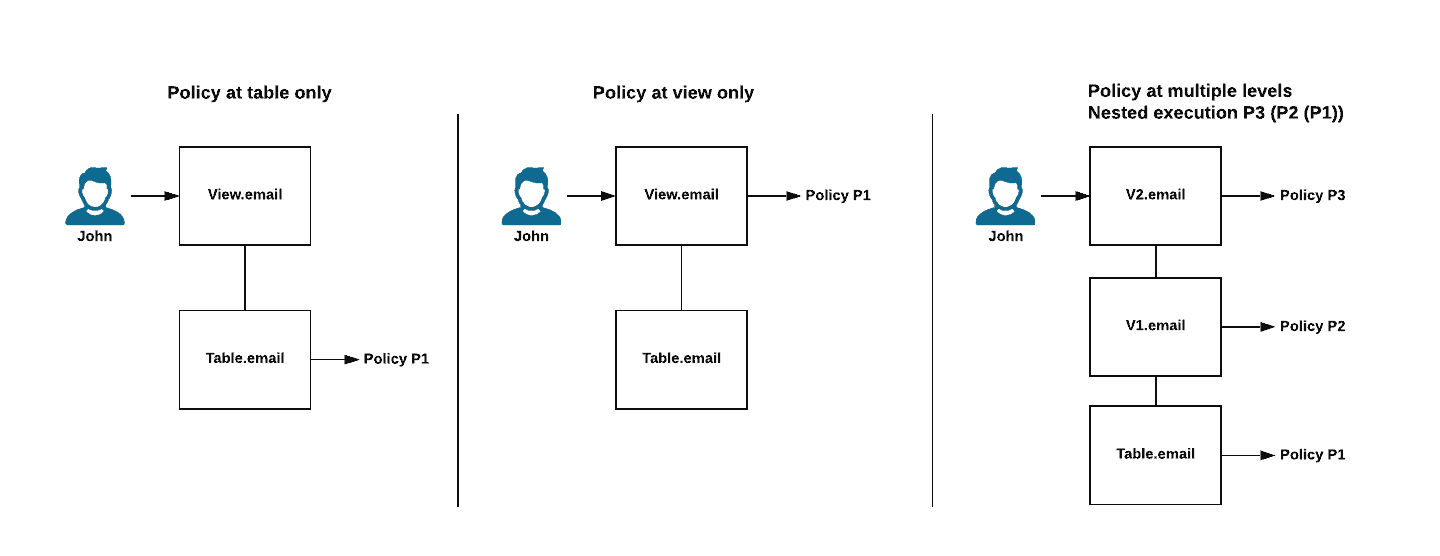
Figure 5: Examples of policy execution.
Based on the use case, you can decide to apply the policy at just the base table column, the view column, or both.
For example, if you want some roles to allow access to the aggregate value, but not individual sensitive information, you can apply a policy on the table column using invoker_role() and apply a second policy on the view aggregate column using the current_role().
Masking Policies for Data Sharing
Data providers can now mask/obfuscate sensitive data when sharing it with their consumers by simply applying masking policies to the shared table or secure view columns. Furthermore, with the introduction of the new invoker_share() context function, different masking rules can be applied to the same column when used in multiple shares, as shown in Figure 6. This gives data providers additional flexibility in how they provide data to consumers while being easy to manage centrally.
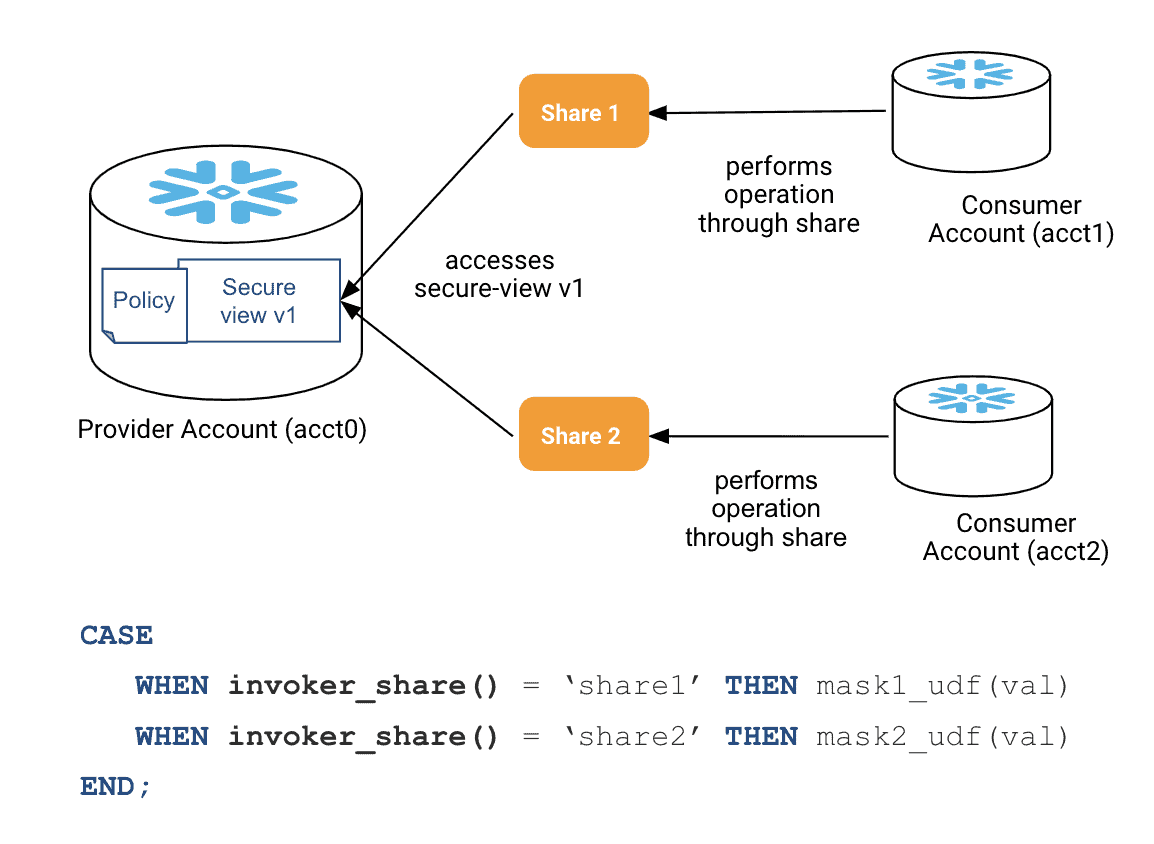
Figure 6: Example of providing different masking rules to a column that is part of multiple shares.
Managing Data Masking Policies
Determining who can create masking policies and apply them to columns is controlled through new RBAC privileges. Different organizations have different requirements for how they want to manage policies. Some organizations want policies to be centrally managed, other organizations want policy management to be a decentralized function, and other organizations fall in between.
Snowflake supports a continuum of such deployment use cases, as shown in Figure 7. A security/privacy officer can centrally manage and apply policies, or the security/privacy officer can define policies and make data stewards on individual teams responsible for applying the policies to their data sets. A third option is to let team data stewards define and apply policies.
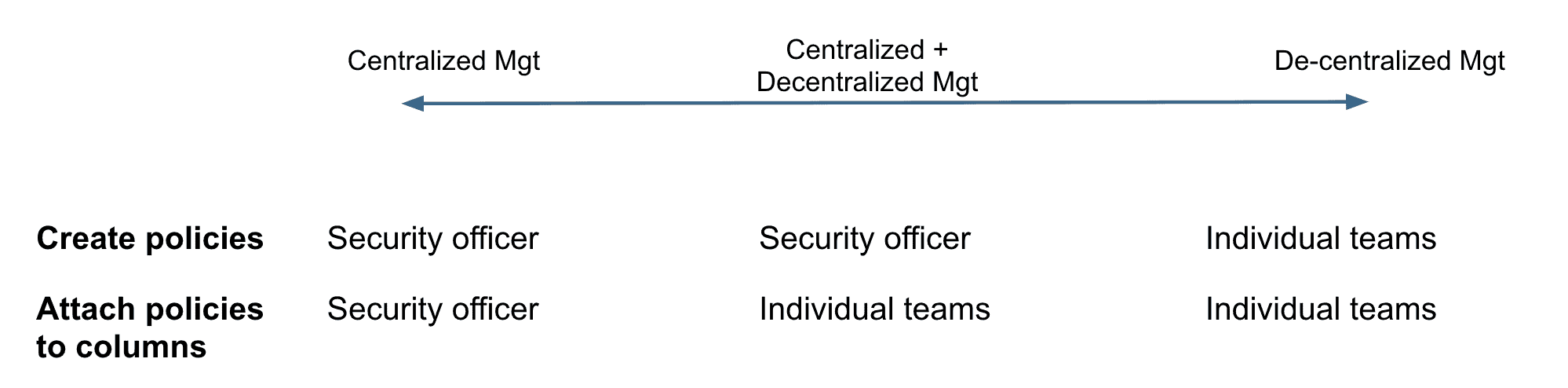
Figure 7: Options for creating and applying data masking policies.
A Few Things to Keep in Mind
- Masking policies cannot be applied to virtual columns. This limitation is to prevent users from bypassing the policy by directly using the underlying expression. If you have a need to apply a data masking policy to a virtual column, you can create a view on the virtual columns, and apply policies to the view columns.
- Since all columns of an external table are virtual except the VALUE variant column, you can apply a data masking policy only to the VALUE column.
- Materialized views can’t be created on table columns with masking policies applied. Similarly, policies can’t be applied to table columns if materialized views exist on those columns. However, you can apply masking policies to materialized view columns as long as there’s no masking policy on the underlying columns.
- Masking policies carry over to cloned objects.
- The Result Set cache isn’t used for queries that contain columns with masking policies.
Conclusion
Bring your sensitive data into Snowflake and start querying it using dynamic data masking and external tokenization. See Snowflake documentation for further details. Also, please share your feedback or request enhancements through the Snowflake community.