
注:本記事は(2021年7月21日)に公開された(How Cisco Optimized Performance on Snowflake to Reduce Costs 15%: Part 1)を翻訳して公開したものです。
Snowflakeは、データウェアハウスワークロード向けの強力なプラットフォームです。エンタープライズでデータの需要が高まる中、Snowflakeは以前のデータウェアハウスソリューションからの既存のワークロードを処理しながら、新しいデータプロジェクトやデータデマンドにも対応します。データガバナンスを向上させ、より細部にわたるデータセキュリティを提供するSnowflakeを利用することで、Cisco(およびそのカスタマーやパートナー)はデータの力をさらに高め、大きなビジネスインパクトを実現しています。
以前、当社のブログ記事の中でAnupama Rao氏がデータの移行について語ったとおり、Snowflakeはレポートと変革に関して期待以上の性能を発揮しました。同氏は次のように説明します。「かつては実行に10時間以上かかっていた変換ジョブが、今では1時間以内に完了するため、性能が10倍向上したことになります。これにより、当社のビジネスチームのダッシュボードには、より最新のデータが供給されるようになり、それに基づいてより正確なインサイトが得られるようになりました。レポートも今では平均4倍もの速さで作成できるようになり、同時実行の容量も4倍に増えたため、アナリストは業務上のニーズに応じて柔軟にレポートを平行して作成することができます。」
Snowflakeの従量課金モデルにより、組織はコスト管理の焦点をプランニングからモニタリングや最適化に移すことができました。Snowflakeは特に設定をしなくても初めからコスト最適化のためのチェックアンドバランス機能を備えています。また、Snowflakeの仕組みの基本を理解している方であれば、さらなる最適化も可能です。同時実行性と拡張性、さらには最適化された性能が、あらゆるデータウェアハウス環境の中心的なモットーです。前後編の2部構成でお届けする今回は、Snowflakeの主要なアーキテクチャ構成要素をレビューし、自社のワークロードに合わせて性能を最適化するお勧めのベストプラクティスをご紹介します。
Snowflakeのアーキテクチャ
図1で示すSnowflakeのアーキテクチャには、下記が含まれています。
- 事実上無制限の量の構造化、半構造化、および非構造化データを格納できる集約されたストレージ(プライベートプレビュー版)
- リソースの競合なしに複数のワークロードを実行できるマルチクラスター向けコンピュート機能
- 共通の管理、セキュリティ、メタデータタスクを自動化するクラウドサービス
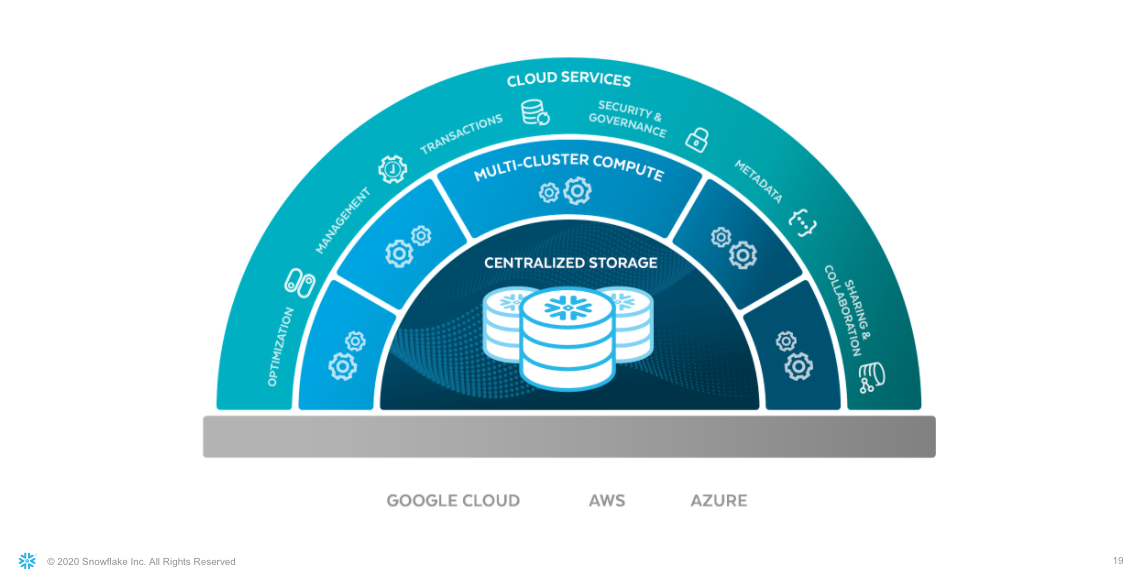
図1:Snowflakeアーキテクチャ
Snowflakeプラットフォームはクラウドリージョンとプロバイダーをまたいで一貫したエクスペリエンスを提供します。異なるクラウドインフラストラクチャーと管理タスクによる複雑さは、Snowflakeの最適化ストレージではめったに見られません。システムのパワーの原動力は、仮想マシンの伸縮性のあるクラスターである仮想ウェアハウスであり、その仮想ウェアハウス、クエリ、すべてのメタデータを管理するSnowflakeクラウドサービスレイヤーのサービスの集合がシステムの頭脳に当たります。
キャッシング
キャッシングのためのパラメーターを最適化することで、パフォーマンスが向上し、コストが減少します。
メタデータキャッシュ
メタデータキャッシュは、Snowflakeクラウドサービスレイヤーの性能を最適化します。ユーザーのクエリは構文的な検証と意味的な検証の両方が必要です。そのためにSnowflakeの実行エンジンはメタデータレイヤー内のキャッシュにアクセスし、アカウントに関する情報を見つけます。解析されたクエリプランはキャッシュされるため、後続の類似クエリをより速くコンパイルできます。メタデータキャッシュのメンテナンスと最適化はSnowflakeが行うため、ユーザーによる介入は不要です。
ウェアハウスキャッシュ
Snowflakeでは、仮想ウェアハウスはコンピュート(ミドル)レイヤーの内側にあります。Snowflake内で実行されるほぼすべてのクエリにはアクティブな仮想ウェアハウスが必要です(SHOW TABLESのようなメタデータドリブンなクエリや、SELECT COUNT(*) or SELECT MIN(COL)のような事前コンピュートされた集計クエリは例外)。
仮想ウェアハウスは、他のコンピュートサーバーと同様、事前定義されたCPU、メモリ、ストレージでプロビジョニングされます。クエリが実行されると常に、関連データがクラウドストレージレイヤーから取得されます。次にこのデータはプロビジョニング済のウェアハウスに関連付けられた高速SSDに保管されます。次回、クエリが同じデータを求める場合、ローカルディスクキャッシュ(ウェアハウスキャッシュと呼ばれる)のデータが再利用されます。ウェアハウスキャッシュにデータがない場合、リモートI/Oとなります。リモートI/Oは時間とコストがかかるため、ウェアハウスキャッシュを使用する方が、より高速でコスト効率の高いクエリ応答が実現します。
Snowflakeの場合、ウェアハウスキャッシュのサイズは使用されたウェアハウスのサイズに正比例します。たとえば、XSサイズのウェアハウスに関連付けられたキャッシュは、4XLサイズのウェアハウスに関連付けられたキャッシュの128分の1となります。このことからも自社のニーズに最適なサイズのウェアハウスを選択することが重要となります。
入力するパラメーターに基づいて、ウェアハウスを自動的に一時停止するよう設定できます。ウェアハウスが一時停止すると常に関連キャッシュは直ちにクリアされるため、ウェアハウス一時停止パラメーターを設定するときは、コストと性能のトレードオフを考慮してください。ウェアハウスの一時停止が頻繁すぎると、データを何度もキャッシュしなければならなくなる場合があります。
ウェアハウスの一時停止時間を設計するときは、以下の点を考慮してください。
- クエリの実行頻度はどれくらいか
- 関与するデータセットの大きさはどれくらいか
- 類似のクエリで使用されるテーブルにどの程度の重複が存在するか
図2は、一時停止されたウェアハウスと実行中のウェアハウス間のクエリ時間の違いを示しています。
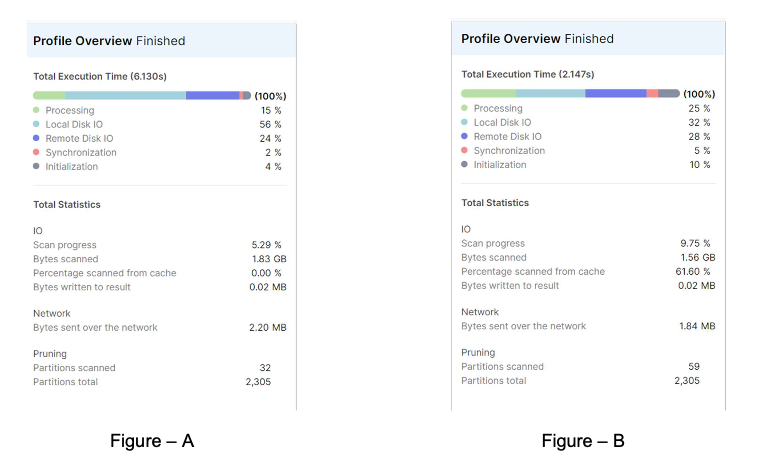
図2:キャッシュ済データを使用した場合に、一時停止されたウェアハウスと実行中のウェアハウスに関してクエリプロファイルに表示されたクエリ時間の違い
一時停止されたウェアハウスでのクエリ(左側)には6秒かかっており、その時間の80%はI/Oオペレーションで使われています。キャッシュからのスキャンの割合は0%となっており、ウェアハウスキャッシュが一切使用されなかったことを意味します。一方、実行中のウェアハウスでのクエリ(右側)はわずか2秒で完了しました。データの60%はキャッシュからスキャンされており、結果としてクエリ応答時間が66%速くなっています。キャッシュ効率の増加とクエリ応答時間の増加が正比例していました。
結果キャッシュ
Snowflakeでは、結果を結果キャッシュに格納し、同じクエリが出されると保存された結果が再利用されるようになっています。図3に示されているのは元のクエリに対する統計であり、完了までに4.5秒かかっています。24時間以内に同じクエリが再度実行されると結果が数ミリ秒で返され、クエリプロファイルには結果キャッシュが使用されたことが分かります。

図3:結果キャッシュに保存されたクエリ結果がクエリプロファイルに表示されている様子
結果は、24時間から最大31日間まで保存できます。ただし結果キャッシュは送信されたクエリが同じ場合(空白スペースや改行文字を除く)のみ機能します。クエリの文字種が異なる場合、結果キャッシュは活用されません。たとえば、select col1 from tab1は、SELECT COL1 FROM TAB1と同じとは認識されません。
結果キャッシュは、ユーザーやロールをまたいで使用できます。ただし、データをクエリしている各ロールが基になるすべてのテーブルへのアクセス権限を有していること、また同じクエリを送信していることが条件となります。たとえば、ユーザーAがロールRを通じてデータXをクエリした24時間以内に、ユーザーBが同じデータXをロールSを通じてクエリした場合、結果キャッシュが使用され、実際にはクエリを実行せずに結果が返されます。
ウェアハウス
Snowflakeでは、どのクエリにも、CPU、メモリ、ストレージを含むコンピュートリソースである仮想ウェアハウスが必要です。Snowflakeの仮想ウェアハウスは「Tシャツサイズ」で提供されます。下の表はウェアハウスのサイズ、関連する利用可能リソース、および使用時に消費される1秒あたりのクレジットをまとめたものです。

図4:Snowflakeドキュメンテーションに掲載されているウェアハウスのサイズ表(将来サイズが変更される可能性があります。Snowflakeドキュメンテーションをご確認ください)
ウェアハウスのサイズが大きいほど、より多くのリソースが提供されます。ただし、ワークロードによっては、リソースが増えたからといって必ずしもクエリ応答が良くなるとは限りません。
特定のワークロードに対してウェアハウスを設計する場合、以下について考慮してください。
- データセットの量
- クエリの複雑さ
- 関連するクエリ応答時間のSLA
- クエリ実行のコスト
マルチクラスターウェアハウス機能を利用すると、各仮想ウェアハウスをクラスターのセットにすることができます。クラスターのサイズ(1~10)により、類似のウェアハウスのインスタンスをどれだけ多く同時実行できるかが決まります(水平スケーリング)。これによりSnowflakeは、需要の増加に応じて追加のクラスターを始動できるため、システムで大規模な並行ロード処理が予想される場合に便利です。ロードが減ると、Snowflakeは自動停止設定に基づいて追加クラスターを自動的に停止し、必要最小限のクラスターサイズにまで減らします。
大規模なデータセットや大量の結合を含む複雑なクエリを実行するには、より多くのコンピュートリソースが必要になる場合があります。その場合、ALTER WAREHOUSEコマンドを使用して仮想ウェアハウスのサイズを上げます(垂直スケーリング)。しかし、ウェアハウスのサイズを上げるごとに、関連するキャッシュが削除されるため、ワークロードに基づいてウェアハウスのサイズを決定し、ワークロードに大幅な変化が発生するまでは同じサイズで実行することをお勧めします。
これにより、SLAを満たすパフォーマンスを確保できます。ただし、コストとのトレードオフに注意し、アクティビティに基づいて自動停止を使用しながらアップタイムを管理してください。ウェアハウスを始動するごとに、最小1分間が課金されるという点にご注意ください。それ以降はウェアハウスの実行時間(秒単位)で課金されます。従って、停止時間を1分未満に設定しても意味がありません。
クラスタリング
クエリの最適化においては、クラスタリングが重要な役割を果たします。Snowflake内のすべてのテーブルは、デフォルトでマイクロパーティションに区切られており、それぞれ50 MB~500 MBの非圧縮データを格納するよう設計されています。テーブルにクラスタリングキー明示的なパーティションキーが定義されていない場合、ナチュラルキーまたは挿入の命令に基づいて区切られます。
クラスタリングキーは、単一のカラムまたは複数のカラム(複合カラム)に基づいて定義できます。また、関数を用いてクラスタリングキーを定義することもできます。複合カラムベースのクラスタリングキーを定義する場合、カラムの順番が最小カーディナリティーから最大カーディナリティーになるよう選択します。テーブルのクラスタリングキーの健全性を評価するには、SYSTEM$CLUSTERING_INFORMATIONを呼び出します。
クラスタリングカラムを選択するときは、クエリのパターンを考慮し、フィルターと結合でよく使用されるカラムを選びます。
図4と5に示すように、クラスタリングキーの効率性は、関連するクエリプロファイルから判別できます。

図5:クラスタリングの前後に続けて実行されたクエリ
図5は、クラスタリング前後のクエリプロファイルを示します。クラスタリング後の応答時間は5.3秒からミリ秒にまで短縮されています。プロファイルの一番下のPartitions scannedとPartitions totalフィールドとの間の違いに注目してください。これはパーティションプルーニングの結果を示しています。クラスタリングキーのないクエリはパーティションの52%をスキャンしていますが、クラスタリングキーのあるクエリはパーティションの7.5%しかスキャンしていません。クラスタリングキーを使用することで、クエリパフォーマンスが134%上がっています。

図6:クラスタリング前(左)とクラスタリング後(右)のクエリ統計を示すクエリプロファイル
クラスタリングはパフォーマンスを向上させることができますが、再クラスタリングコストも考慮する必要があります。いったんテーブルにクラスタリングキーが定義されるとテーブル上でDMLが起きるごとに再クラスタリング操作が必要となり、これにはコンピュートリソースが使用されます。Snowflakeは変更をスキャンしてバックグラウンドで再クラスタリングする自動クラスタリングサービスを提供しています。これらの操作のコストはサービスとして課金されます。このコストを最小化するには、挿入されたデータが、クラスタリングキー定義における順序と同じ順序で追加可能かを調べます。また、1日のうちにテーブルに多くの変更が施される場合、ALTER TABLEコマンドを使用して自動クラスタリングを停止し、1日に1回、それらの変更後に再開して累積クラスタリングを実行することを検討してください。
マテリアライズドビュー
マテリアライズドビューは、物理テーブルの事前コンピュートされたデータや累積データを保存する物理的な構造です。基となる物理テーブルにDMLが生じるたびに、Snowflakeは関連するマテリアライズドビューを更新し、データの整合性を確保します。このサービスには関連するコンピュートコストが生じます。マテリアライズドビューは1対1である必要があります(現在、Snowflakeでは結合を含むマテリアライズドビューをサポートしていません)。Snowflakeは最近、クエリリライトという新機能をリリースしました。これは、クエリロジックまたは集計がマテリアライズドビューの定義に完全に一致する場合に、ベーステーブルの代わりにマテリアライズドビュー(存在する場合)を使用するようクエリを自動的に再ルーティングする機能です。
マテリアライズドビューを使用する前に:
- 履歴を確認します。集計クエリが何回トリガーされたかを確認して、マテリアライズドビューなしで実行する場合のコンピュートコストを計算します。次に、同じロジックでマテリアライズドビューを作成し、マテリアライズドビューをクエリするためのコンピュートコストを確認します。これに、マテリアライズドビューの更新コストを追加します。両コストの合計が元のコンピュートコストよりも少ない場合、マテリアライズドビューを導入すべき使用事例となります。
- 集計データが、独立した物理テーブルとして、またはETLプロセスの一部として保持可能か調べます。それが可能であり、かつテーブルを構築するためのコンピュートコストがマテリアライズドビューの更新コストよりも少ない場合、テーブルを使用することで、パフォーマンスを犠牲にすることなくコストを削減できます。
クエリ履歴
SnowflakeのQUERY_HISTORYは、Snowflakeの内部メタデータデータベースからシェアされるビューで、Snowflakeシステムに対して実行される各クエリに関するエントリーが掲載されており、クエリのパターンや履歴に基づいてコストを最適化するための優れたリソースとなります。このビューは、SNOWFLAKE.INFORMATION_SCHEMAまたはSNOWFLAKE.ACCOUNT_USAGE_SCHEMAからクエリできます。
このビューで表示される以下のカラムは、クエリのパフォーマンスを向上させ、関連コストをシステムレベルで低減するために役立つインサイトを提供します。
- WAREHOUSE_SIZE:TOTAL_ELAPSED_TIMEと併用することで、クエリの適切なコストを判別できます。
- EXECUTION_STATUS:失敗クエリに付随するコストの特定に使用されます。
- PERCENTAGE_SCANNED_FROM_CACHE:ウェアハウスのサイズとアップタイムの検証に使用されます。
- PARTITIONS_SCANNED:PARTITIONS_TOTALと併用することで、プルーニングの効率性について、またテーブルをクラスター化する必要があるかを識別できます。
- QUEUED_PROVISIONING_TIME:QUEUED_OVERLOAD_TIMEと併用することで、マルチクラスターウェアハウスの設計に役立ちます。
- QUERY_LOAD_PERCENT:ウェアハウスロードの判別に使用されます。
Snowflakeのアーキテクチャと最適化機能について理解することで、非効率な点を発見し性能を改善することができます。このシリーズの後編では、Ciscoのチームによる性能最適化のベストプラクティスについて詳しくご紹介します。
Manickaraja Kumarappan氏は、このブログの執筆時点、Ciscoデータアンドアナリティクス部門のアーキテクトの職にありました。