
Enterprises can now harness the power of Apache Spark to quickly and easily prepare data and build Machine Learning (ML) models directly against that data in Snowflake. Snowflake and Qubole make it easy to get started by embedding required drivers, securing credentials, simplifying connection setup and optimizing in-database processing. Customers can focus on getting started quickly with their data preparation and ML initiatives instead of worrying about complex integrations and the cost of moving large data sets.
Setting up the Snowflake connection and getting started takes only a few minutes. Customers first create a Snowflake data store in Qubole and enter details for their Snowflake data warehouse. All drivers and packages are preloaded and kept up to date, eliminating manual bootstrapping of jars into the Spark cluster. There is no further configuration or tuning required and there are no added costs for the integration. Once the connection is saved, customers can browse their snowflake tables, view metadata and see a preview of the Snowflake data all from the Qubole interface. They can then use Zeppelin notebooks to get started reading and writing data to Snowflake as they begin exploring advanced data preparation and ML use cases.
Below is an example of the object browser view showing the available tables and properties:
Security is also handled seamlessly so customers can focus on getting started with their data, without the worry of over-protecting their credentials. Qubole provides centralized and secure credential management which eliminates the need to specify any credentials in plain text. Username and password are entered only when setting up the data store, but are otherwise inaccessible.
The solution is also designed for enterprise requirements and allows customers to use federated authentication and SSO via the embedded Snowflake drivers. With SSO enabled, customers can authenticate through an external, SAML 2.0-compliant identity provider (IdP) and achieve a higher level of security and simplicity. These capabilities help customers more easily share notebooks and collaborate on projects with little risk of sensitive information being exposed.
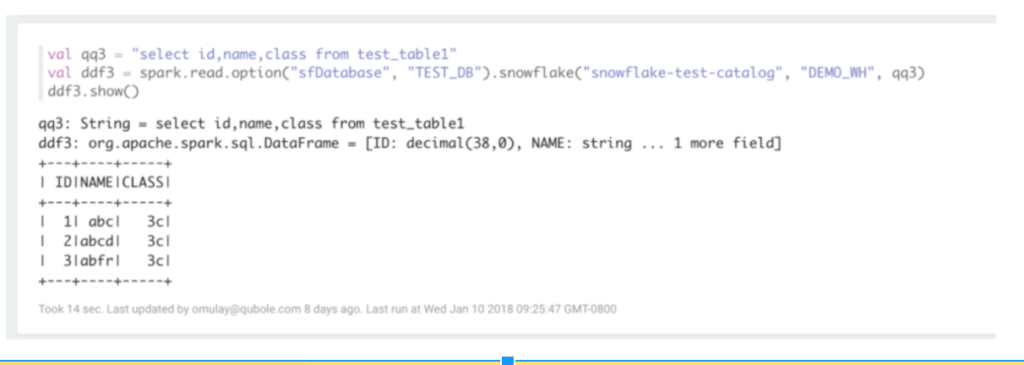
Below is a sample Scala program showing how to read from Snowflake using the data store object without specifying any credentials in plain text:

Beyond the simplicity and security of the integration, which helps customers get started quickly, customers will also benefit from a highly optimized Spark integration that uses Snowflake query pushdown to balance the query-processing power of Snowflake with the computational capabilities of Apache Spark. From simple projection and filter operations to advanced operations such as joins, aggregations and even scalar SQL functions, query pushdown runs these operations in Snowflake (where the data resides) to help refine and pre-filter the data before it is read into Spark. The traditional performance and cost challenges associated with moving large amounts data for processing are thereby eliminated without additional overhead or management.
With Snowflake and Qubole, customers get an optimized platform for advanced data preparation and ML that makes it simple to get started. Customers can complement their existing cloud data warehouse strategy or get more value out of ML initiatives by opening access to more data. To learn more about ML and advanced data preparation with Qubole, visit the Qubole blog.
Try Snowflake for free. Sign up and receive $400 US dollars worth of free usage. You can create a sandbox or launch a production implementation from the same Snowflake environment.