
Updates have been made since the original publishing of this blog post. For the latest information about Snowflake’s support for Apache Iceberg, please see here.
For anyone pursuing a data lake or data mesh strategy, choosing a table format is an important decision. A table format will enable or limit the features available, such as schema evolution, time travel, and compaction, to name a few. With several different options available, let’s cover five compelling reasons why Apache Iceberg is the table format to choose if you’re pursuing a data architecture where open source and open standards are a must-have.
Table formats and Iceberg
First, let’s cover a brief background of why you might need an open source table format and how Apache Iceberg fits in. If you are building a data architecture around files, such as Apache ORC or Apache Parquet, you benefit from simplicity of implementation, but also will encounter a few problems. For instance, query engines need to know which files correspond to a table, because the files do not have data on the table they are associated with. Additionally, files by themselves do not make it easy to change schemas of a table, or to time-travel over it. Each query engine must also have its own view of how to query the files. All of a sudden, an easy-to-implement data architecture can become much more difficult. This is where table formats fit in: They enable database-like semantics over files; you can easily get features such as ACID compliance, time travel, and schema evolution, making your files much more useful for analytical queries.
Apache Iceberg is one of many solutions to implement a table format over sets of files; with table formats the headaches of working with files can disappear. Iceberg was created by Netflix and later donated to the Apache Software Foundation. Today, Iceberg is developed outside the influence of any one for-profit organization and is focused on solving challenging data architecture problems. While Iceberg is not the only table format, it is an especially compelling one for a few key reasons. It is in part because of these reasons that we announced earlier this year expanded support for Iceberg via External Tables, and more recently at Summit a new type of Snowflake table called Iceberg Tables.
What table formats such as Iceberg solve
If you are running high-performance analytics on large amounts of files in a cloud object store, you have likely heard about table formats. A common question is: what problems and use cases will a table format actually help solve?
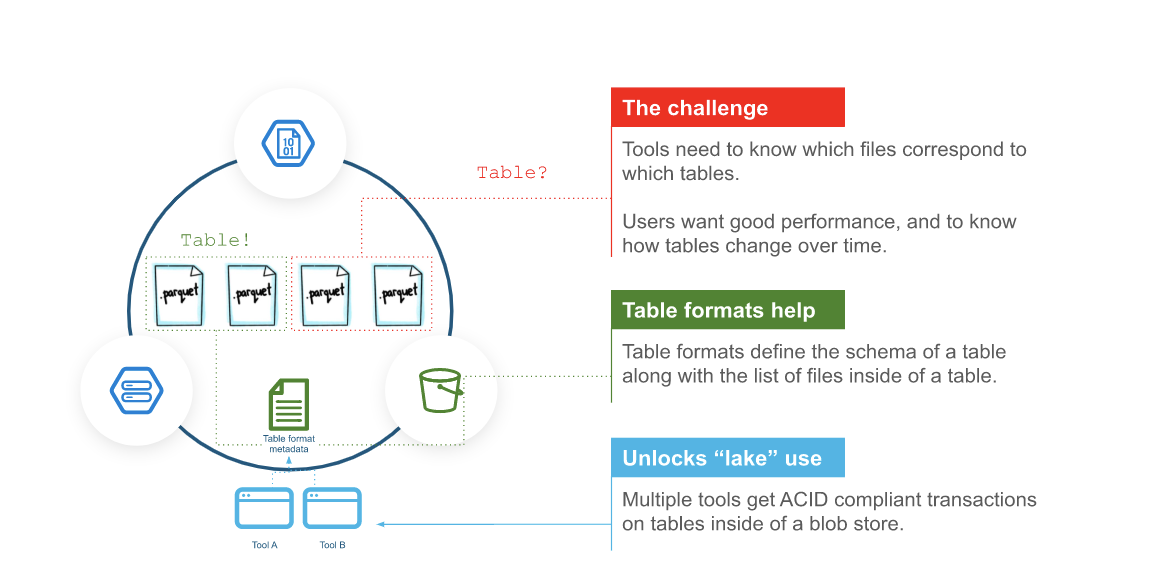
At a high level, table formats such as Iceberg enable tools to understand which files correspond to a table and to store metadata about the table to improve performance and interoperability.
Performance
Performance can benefit from table formats because they reduce the amount of data that needs to be queried, or the complexity of queries on top of the data. Table formats such as Iceberg hold metadata on files to make queries on the files more efficient and cost effective. Interestingly, the more you use files for analytics, the more this becomes a problem. Often people want ACID properties when performing analytics and files themselves do not provide ACID compliance.
For example, say you are working with a thousand Parquet files in a cloud storage bucket. Without metadata about the files and table, your query may need to open each file to understand if the file holds any data relevant to the query. Likewise, over time, each file may be unoptimized for the data inside of the table, increasing table operation times considerably. A table format can more efficiently prune queries and also optimize table files over time to improve performance across all query engines.
Interoperability
If you are an organization that has several different tools operating on a set of data, you have a few options. You can create a copy of the data for each tool, or you can have all tools operate on the same set of data. If you want to use one set of data, all of the tools need to know how to understand the data, safely operate with it, and ensure other tools can work with it in the future.
An example will showcase why this can be a major headache. Suppose you have two tools that want to update a set of data in a table at the same time. Without a table format and metastore, these tools may both update the table at the same time, corrupting the table and possibly causing data loss. As another example, when looking at the table data, one tool may consider all data to be of type string, while another tool sees multiple data types. Table formats, such as Iceberg, can help solve this problem, ensuring better compatibility and interoperability.
Ease of use
Cost is a frequent consideration for users who want to perform analytics on files inside of a cloud object store, and table formats help ensure that cost effectiveness does not get in the way of ease of use. When someone wants to perform analytics with files, they have to understand what tables exist, how the tables are put together, and then possibly import the data for use. Table formats such as Iceberg have out-of-the-box support in a variety of tools and systems, effectively meaning using Iceberg is very fast.
As an example, say you have a vendor who emits all data in Parquet files today and you want to consume this data in Snowflake. Traditionally, you can either expect each file to be tied to a given data set or you have to open each file and process them to determine to which data set they belong. Moreover, depending on the system, you may have to run through an import process on the files. With Iceberg, however, it’s clear from the start how each file ties to a table and many systems can work with Iceberg, in a standard way (since it’s based on a spec), out of the box.
Compelling reasons to choose Iceberg
Given the benefits of performance, interoperability, and ease of use, it’s easy to see why table formats are extremely useful when performing analytics on files. The next question becomes: which one should I use? While there are many to choose from, Apache Iceberg stands above the rest; because of many reasons, including the ones below, Snowflake is substantially investing into Iceberg.
1: Iceberg makes a clean break from the past.
The past can have a major impact on how a table format works today. Some table formats have grown as an evolution of older technologies, while others have made a clean break. Iceberg is in the latter camp. Generally, Iceberg has not based itself as an evolution of an older technology such as Apache Hive. While this seems like something that should be a minor point, the decision on whether to start new or evolve as an extension of a prior technology can have major impacts on how the table format works.
Starting as an evolution of older technologies can be limiting; a good example of this is how some table formats navigate changes that are metadata-only operations in Iceberg. How schema changes can be handled, such as renaming a column, are a good example. By making a clean break with the past, Iceberg doesn’t inherit some of the undesirable qualities that have held data lakes back and led to past frustrations. Looking forward, this also means Iceberg does not need to rationalize how to further break from related tools without causing issues with production data applications. Over time, other table formats will very likely catch up; however, as of now, Iceberg has been focused on the next set of new features, instead of looking backward to fix the broken past.
2: Iceberg is engine–and file format–agnostic from the ground up.
By decoupling the processing engine from the table format, Iceberg provides customers more flexibility and choice. Instead of being forced to use only one processing engine, customers can choose the best tool for the job. Choice can be important for two key reasons. First, the tools (engines) customers use to process data can change over time. For example, many customers moved from Hadoop to Spark or Trino. Second, it’s fairly common for large organizations to use several different technologies and choice enables them to use several tools interchangeably.
Iceberg also supports multiple file formats, including Apache Parquet, Apache Avro, and Apache ORC. This design offers flexibility at present, since customers can choose the formats that make sense on a per-use case basis, but also enables better long-term plugability for file formats that may emerge in the future. In this respect, Iceberg is situated well for long-term adaptability as technology trends change, in both processing engines and file formats.
As a result of being engine-agnostic, it’s no surprise that several products, such as Snowflake, are building first-class Iceberg support into their products. From a customer point of view, the number of Iceberg options is steadily increasing over time.
3: The Iceberg project is well-run open source.
As we have discussed in the past, choosing open source projects is an investment. That investment can come with a lot of rewards, but can also carry unforeseen risks. The Iceberg project is a well-run and collaborative open source project; transparency and project execution reduce some of the risks of using open source.
How is Iceberg collaborative and well run? First and foremost, the Iceberg project is governed inside of the well-known and respected Apache Software Foundation. This means that the Iceberg project adheres to several important Apache Ways, including earned authority and consensus decision-making. This is not necessarily the case for all things that call themselves “open source.” For example, Apache Iceberg makes its project management public record, so you know who is running the project. Other table formats do not even go that far, not even showing who has the authority to run the project. A table format is a fundamental choice in a data architecture, so choosing a project that is truly open and collaborative can significantly reduce risks of accidental lock-in.
4: Collaboration in Iceberg is spawning new ideas and help.
There are several signs the open and collaborative community around Apache Iceberg is benefiting users and also helping the project in the long term. For users of the project, the Slack channel and GitHub repository show high engagement, both around new ideas and support for existing functionality. Critically, engagement is coming from all over, not just one group or the original authors of Iceberg. This “community helping the community” is a clear sign of the project’s openness and healthiness.
Collaboration around the Iceberg project is starting to benefit the project itself. The project is soliciting a growing number of proposals that are diverse in their thinking and solve many different use cases. Additionally, the project is spawning new projects and ideas, such as Project Nessie, the Puffin Spec, and the open Metadata API. These are just a few examples of how the Iceberg project is benefiting the larger open source community; how these proposals are coming from all areas, not just from one organization. We are excited to participate in this community to bring our Snowflake point of view to issues relevant to customers.
5: Iceberg includes features that are paid in other table formats.
Iceberg, unlike other table formats, has performance-oriented features built in. This matters for a few reasons. First, some users may assume a project with open code includes performance features, only to discover they are not included. Second, if you want to move workloads around, which should be easy with a table format, you’re much less likely to run into substantial differences in Iceberg implementations. Third, once you start using open source Iceberg, you’re unlikely to discover a feature you need is hidden behind a paywall. The distinction between what is open and what isn’t is also not a point-in-time problem.
As an open project from the start, Iceberg exists to solve a practical problem, not a business use case. This is a small but important point: Vendors with paid software, such as Snowflake, can compete in how well they implement the Iceberg specification, but the Iceberg project itself is not intended to drive business for a specific business.
How to get started with Apache Iceberg
There are some excellent resources within the Apache Iceberg community to learn more about the project and to get involved in the open source effort.
- The Iceberg Getting Started guide provides examples of how to get started in purely open source Iceberg and Apache Spark
- Iceberg has several robust communities, such as the public Slack channels with which you can get involved.
- If you want to make changes to Iceberg, or propose a new idea, create a Pull Request based on the contribution guide. The community regularly participates in and combines community requests.
If you use Snowflake, you can get started with our Iceberg private-preview support today. Contact your account team to learn more about these features or to sign up.
- Iceberg Tables: Our new table type based entirely on Iceberg and Parquet in external storage, but with the benefits and similar performance of Snowflake tables
External Tables for Iceberg: Enable easy connection from Snowflake with an existing Iceberg table via a Snowflake External Table
